本文主要是介绍第L1周:机器学习-数据预处理,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
第L1周:机器学习-数据预处理
- 🍨 本文为🔗365天深度学习训练营 中的学习记录博客
- 🍖 原作者:K同学啊
学习要点: ****
- 学习如何处理缺损数据
- 尝试进行Label编码
- 使用train_test_split进行数据划分
- 学习特征标准化
在开始本周的学习任务前,需要先安装好numpy、Pandas、sklearn三个包,安装方法如下:
pip install numpy
pip install Pandas
pip install scikit-learn
🥮 代码学习
🏡 我的环境:
语言环境:Python3.10
编译器:PyCharm
第1步:导入库
import numpy as np
import pandas as pd
第2步:导入数据集
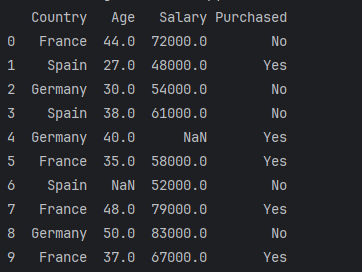
●数据集:
![[Data.csv]]
dataset = pd.read_csv('../data/Data.csv')
print(dataset)
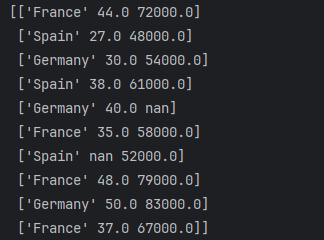
X = dataset.iloc[ : , :-1].values
Y = dataset.iloc[ : , 3].values
print(X)
print(Y)

第3步:处理丢失数据
SimpleImputer函数用于处理缺损值,详细介绍见文末。
# 处理丢失数据 SimpleImputer可以处理
from sklearn.impute import SimpleImputer
imputer = SimpleImputer(strategy='mean') # 用均值来填补丢失值
imputer = imputer.fit(X[:, 1:3])
X[:, 1:3] = imputer.transform(X[:, 1:3])
print("使用SimpleImputer处理丢失数据后的X:")
print(X)
结果如下:
array([['France', 44.0, 72000.0],['Spain', 27.0, 48000.0],['Germany', 30.0, 54000.0],['Spain', 38.0, 61000.0],['Germany', 40.0, 63777.77777777778],['France', 35.0, 58000.0],['Spain', 38.77777777777778, 52000.0],['France', 48.0, 79000.0],['Germany', 50.0, 83000.0],['France', 37.0, 67000.0]], dtype=object)
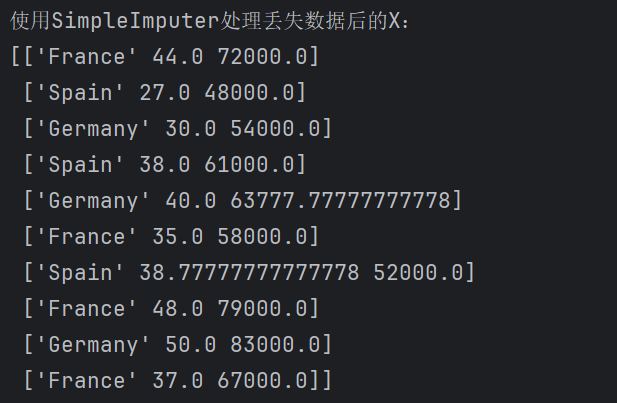
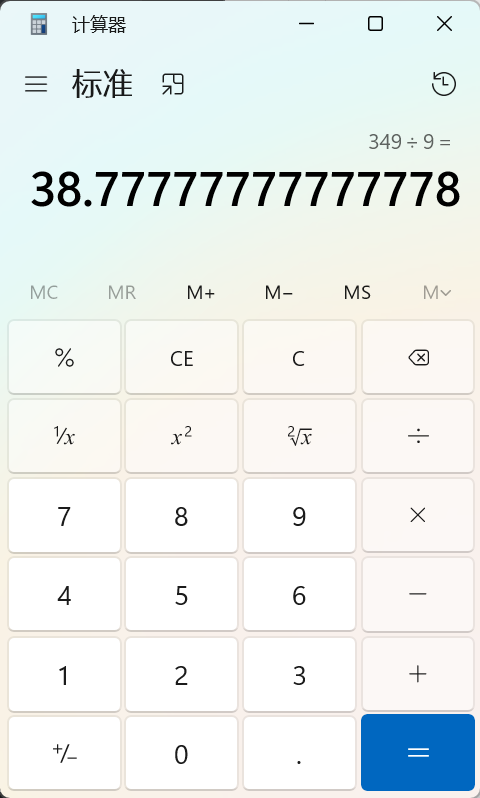
注:原来的NaN处被38.7777778和63.7777778,这个值是通过mean也就是平均值而来,手动计算一下:(44+27+30+38+40+35+48+50+37) / 9 = 38.77777777777778
第4步:进行Label编码
为什么要进行Label编码?进行Label编码的主要原因是为了将文本转换为模型可以理解的数值形式。
from sklearn.preprocessing import LabelEncoder, OneHotEncoderlabelencoder_X = LabelEncoder()
# X[:, 0]是指X的所有行中的第1列进行处理
X[ : , 0] = labelencoder_X.fit_transform(X[ : , 0])
print(X)
结果:
array([[0, 44.0, 72000.0],[2, 27.0, 48000.0],[1, 30.0, 54000.0],[2, 38.0, 61000.0],[1, 40.0, 63777.77777777778],[0, 35.0, 58000.0],[2, 38.77777777777778, 52000.0],[0, 48.0, 79000.0],[1, 50.0, 83000.0],[0, 37.0, 67000.0]], dtype=object)
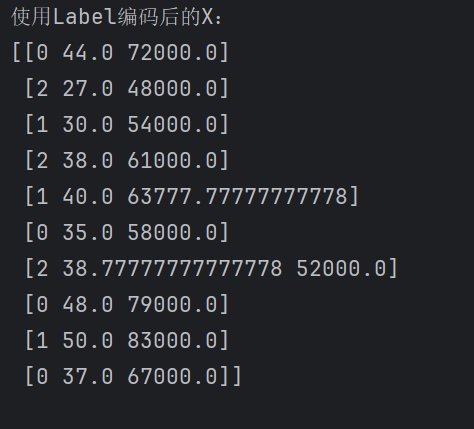
注:根据结果可以看到,labelEncoder将原X中的"France,Germany"等等按字母顺序进行了一个编号。编码规则一定是写死的吗?
labelencoder_Y = LabelEncoder()
Y = labelencoder_Y.fit_transform(Y)
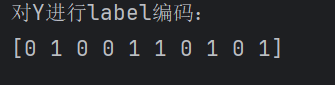
print("对Y进行label编码:")
print(Y)
注:Y原来的值是:Y = dataset.iloc[ : , 3].values 即下面这一列:
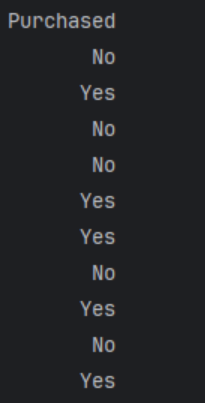
很明显:No被编码成0,Yes被编码成1. 这里很奇怪,它并没有按No和Yes的字母顺序进行编码。那么它的编码规则到底是什么?labelencode的fit里进行编码规则的设定,参考:LabelEncoder 类属性类方法及用法-CSDN博客
第5步:拆分为训练集和测试集
# 拆分训练集和测试集
from sklearn.model_selection import train_test_split
X_train, X_teest, Y_train, Y_test = train_test_split(X, Y, test_size=0.2, random_state= 0)
🌟 train_test_split()函数详解
train_test_split():将数据集划分为测试集与训练集。
●X:所要划分的整体数据的特征集;
●Y:所要划分的整体数据的结果;
●test_size:测试集数据量在整体数据量中的占比(可以理解为X_test与X的比值);
●random_state:
○若不填或者填0,每次生成的数据都是随机,可能不一样。
○若为整数,每次生成的数据都相同;
第6步:特征标准化
解释:

print("X_train:\n", X_train)
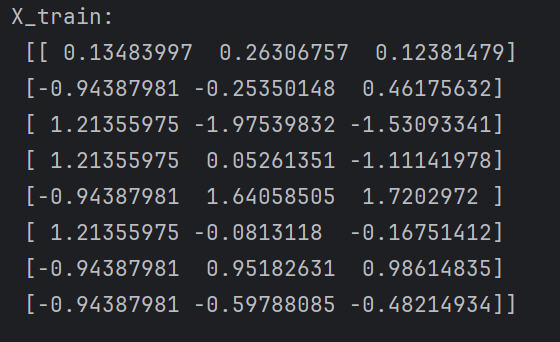
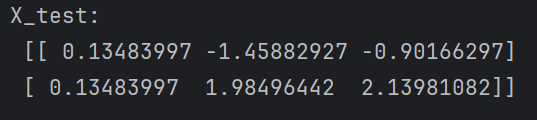
print("X_test:\n", X_test)
StandardScaler()是scikit-learn库中用于数据标准化处理的一个常用工具。标准化目的是将数据缩放到一个均值为 0,标准差为 1 的正太分布,消除不同特征量纲的影响,尤其是像支持向量机 (SVM)、逻辑回归、神经网络等基于梯度的模型。
🍖 知识点讲解
1.SimpleImputer()处理缺损数据
sklearn.impute.SimpleImputer 是 Scikit-learn 库中的一个类,用于处理数据集中缺失值的插补。它通过替换缺失值为统计值(例如均值、中位数或众数)或指定的常数来处理缺失数据。以下是 SimpleImputer 的详细介绍:
🔎 参数详情:
●missing_values: 指定需要替换的缺失值。默认值为 np.nan,表示替换 NaN 值。
●strategy: 指定替换策略。可选值包括:
○’mean’: 用均值替换缺失值。仅适用于数值数据。
○’median’: 用中位数替换缺失值。仅适用于数值数据。
○’most_frequent’: 用众数(出现频率最高的值)替换缺失值。适用于数值和分类数据。
○’constant’: 用常数替换缺失值。需要同时指定 fill_value 参数。
●fill_value: 在 strategy=‘constant’ 时,指定替换缺失值的常数。默认值为 None。
●add_indicator: 是否添加二进制指示变量,用于指示缺失值的位置。默认值为 False。
🔎 SimpleImputer方法该要:
●fit(X, y=None): 拟合 imputer,计算用于替换缺失值的统计值。
●transform(X): 使用拟合的 imputer 替换缺失值。
●fit_transform(X, y=None): 结合 fit 和 transform,对数据集进行拟合并替换缺失值。
以下是一些使用 SimpleImputer 的示例:
👉 用均值替换缺失值
import numpy as np
from sklearn.impute import SimpleImputer
# 创建数据集,其中包含缺失值
X = [[1, 2], [np.nan, 3], [7, 6], [4, np.nan]]
# 创建 SimpleImputer 对象,指定用均值替换缺失值
imputer = SimpleImputer(strategy='mean')
# 训练 imputer 并转换数据
X_imputed = imputer.fit_transform(X)
print(X_imputed)👉 用常数替换缺失值
# 创建 SimpleImputer 对象,指定用常数 -1 替换缺失值
imputer = SimpleImputer(strategy='constant', fill_value=-1)
# 训练 imputer 并转换数据
X_imputed = imputer.fit_transform(X)
print(X_imputed)这篇关于第L1周:机器学习-数据预处理的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





