本文主要是介绍如何让数据治理快速出成效——反向治理,以终为始,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
数据治理有不少知名的方法和框架,如DAMA、DGI、CMMI-DMM、DCMM、ITSS数据治理框架等。这些数据治理方法和框架,从战略到落地都提出来完善的体系,但是按照这些方法和框架实施的,却鲜有成功案例。究其问题无非在于:
一、体系框架过于复杂,涉及组织、流程制度、标准规范、技术平台等诸多方面,难于协调和管控。
二、过于依靠专家设计,数据治理项目往往集中很多来自于内外部的技术专家、管理专家、业务专家等,企图通过专家们的调查、研讨设计出一套完美的数据治理体系出来。这几乎是不可能完成的任务,因为要组建能从广度和深度方面都能完全覆盖的专家团队就基本不可能,再者时间、资源总是有限的。
三、以出文件解决问题,数据治理确实需要产出标准规范、流程制度、组织架构等文件,但出文件就结束了,没有客观、持续、有效的手段进行保障文件的执行,不能解决实际问题。
四、以建系统解决问题,也有不少单位数据治理仅仅定义为咨询,提出一套体系框架,规划出一系列系统建设,认为只要建设了相关系统就能解决数据问题。比如财务科目、客商信息、物料编码,认为上一套主数据系统就解决了,而实际的情况,上了主数据系统的单位,各业务系统中主数据依然存在不一致问题。
五、 以规划思路自顶向下而行,缺少抓手、范围无限扩大、具体问题轻拿轻放。
那么,是不是由于数据治理的复杂性,如果按照以前的方法去做,就一定会出范围广、周期长、投入大、见效慢等问题。
鲁四海团队根据十多年的数据治理经验,也就是十多年的填坑经历,提出了“反向治理,以终为始”的数据治理方法,解决了数据治理缺少抓手、投入大、见效慢的问题。
“反向治理,以终为始”是在吸收了DAMA、DGI等优秀数据治理框架基础上,突出落地性和技术融合性,以结果为导向持续迭代的方法。整体框架如下图所示:
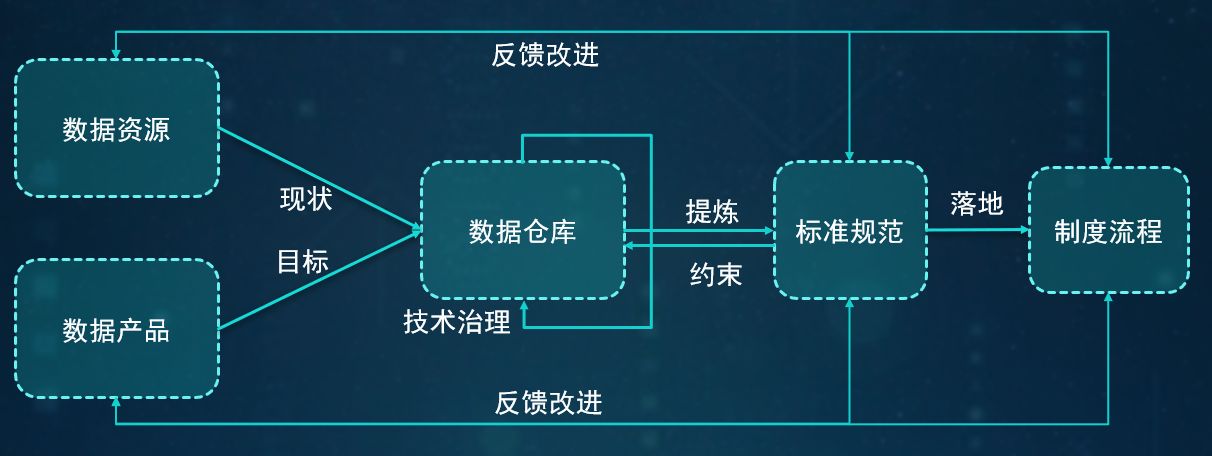
“反向治理”的特点:
一、抓手在“数据仓库”,即先建设数据仓库,将分散在业务系统数据库、接口的数据集中到数据仓库进行碰撞,提出基于现状的数据模型。
二、“目标导向,兼顾先进性”,通过对数据产品(数据的应用,比如报表、报告、API接口等)的梳理,扩展数据模型,使得数据模型具备满足更多应用场景的先进性。
三、数据质量“以终为始”,数据质量是数据治理的目标,以数据仓库建模开始,基于数据模型,通过MPP数据仓库的高性能,快速定位数据质量问题,并以此开始数据治理任务实施,形成“质量反馈——治理改进”的循环迭代,让数据问题收敛。
四、解决标准规范,与实际系统、业务需求偏离问题。通过现有数据碰撞和数据应用目标的分析,提出的数据模型,在模型基础上提出的标准规范,不再空洞。
五、流程制度和组织改进的依据来源于数据仓库得出的标准规范和质量报告,所以在和各部门研讨时有理有据,避免传统数据治理研讨中“只有定性问题,没有定量问题;只有宏观问题,没有具体问题”的尴尬。
这篇关于如何让数据治理快速出成效——反向治理,以终为始的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!




