本文主要是介绍【实践】学大模型必看!手把手带你从零微调大模型!,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
今天分享一篇技术文章,你可能听说过很多大模型的知识,但却从未亲自使用或微调过大模型。
今天这篇文章,就手把手带你从零微调一个大模型。
大模型微调本身是一件非常复杂且技术难度很高的任务,因此本篇文章仅从零开始,手把手带你走一遍微调大模型的过程,并不会涉及过多技术细节。
希望通过本文,你可以了解微调大模型的流程。

微调大模型需要非常高的电脑配置,比如GPU环境,相当于你在已经预训练好的基础上再对大模型进行一次小的训练。
但是不用担心,本篇文章会使用阿里魔塔社区提供的集成环境来进行,无需使用你自己的电脑配置环境。
你只需要有浏览器就可以完成。
本次微调的大模型是零一万物的 Yi 开源大语言模型,当然微调其他大模型的过程和原理也有差不多。
这里说明一下,阿里魔塔社区对于新用户提供了几十小时的免费GPU资源进行使用,正好可以来薅一波羊毛,学习一下大模型的微调。
话不多说,直接开始。

1. 账号和环境准备
首先你需要注册和登录魔搭的账号:https://modelscope.cn/home
注册完成后,登录这个模型网址:
https://www.modelscope.cn/models/01ai/Yi-1.5-6B**.**
然后按照下面的箭头操作。
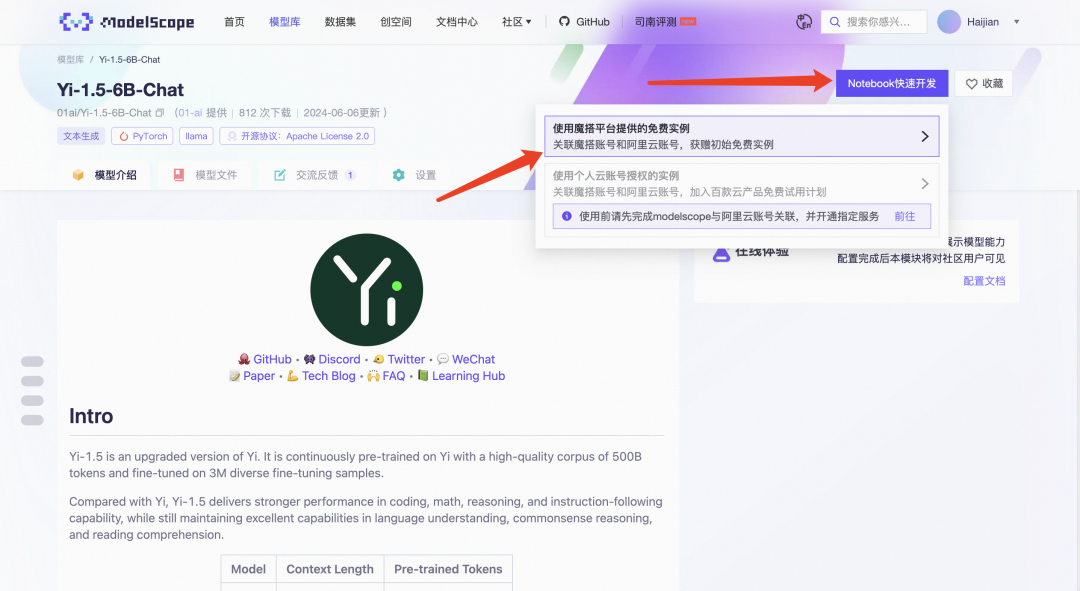
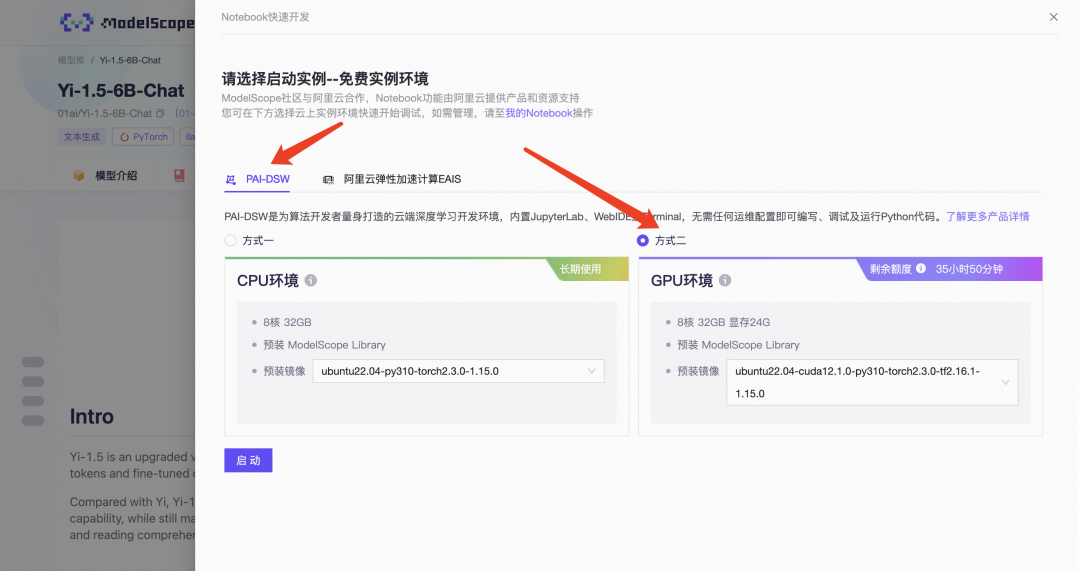
选择完方式二:GPU环境后,点击“启动”。
启动大概需要2分钟,等GPU环境启动好以后点击"查看NoteBook"进入。
魔塔社区内置了JupyterLab的功能,你进入之后,可以找到 Notebook 标签,新建一个Notebook(当然你在terminal 里执行也没问题)。
如下箭头所示,点击即可创建一个新的 Notebook 页面。
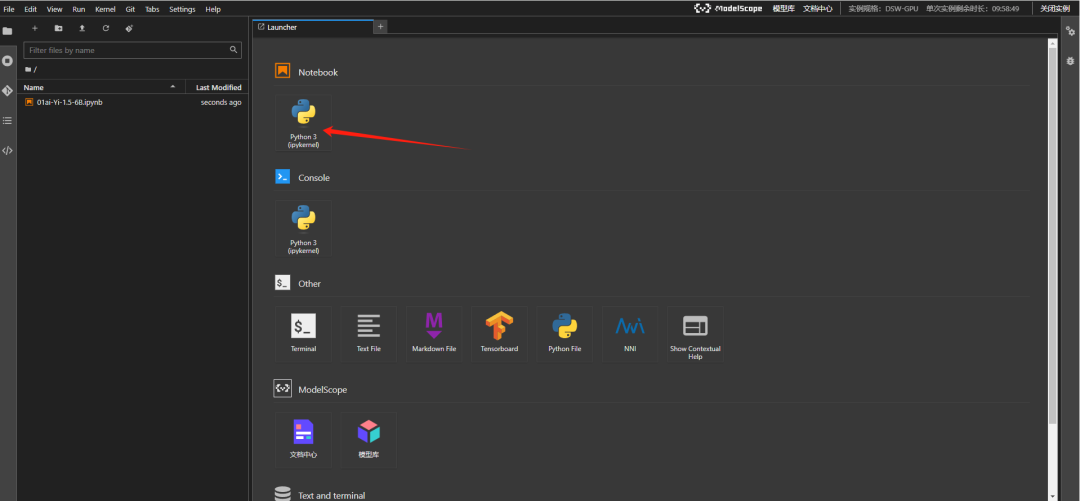
增添一个代码块,并且执行以下命令(点击左侧的运行按钮运行该代码块,下同,这一步是安装依赖库)。

拉取 LLaMA-Factory,过程大约需要几分钟

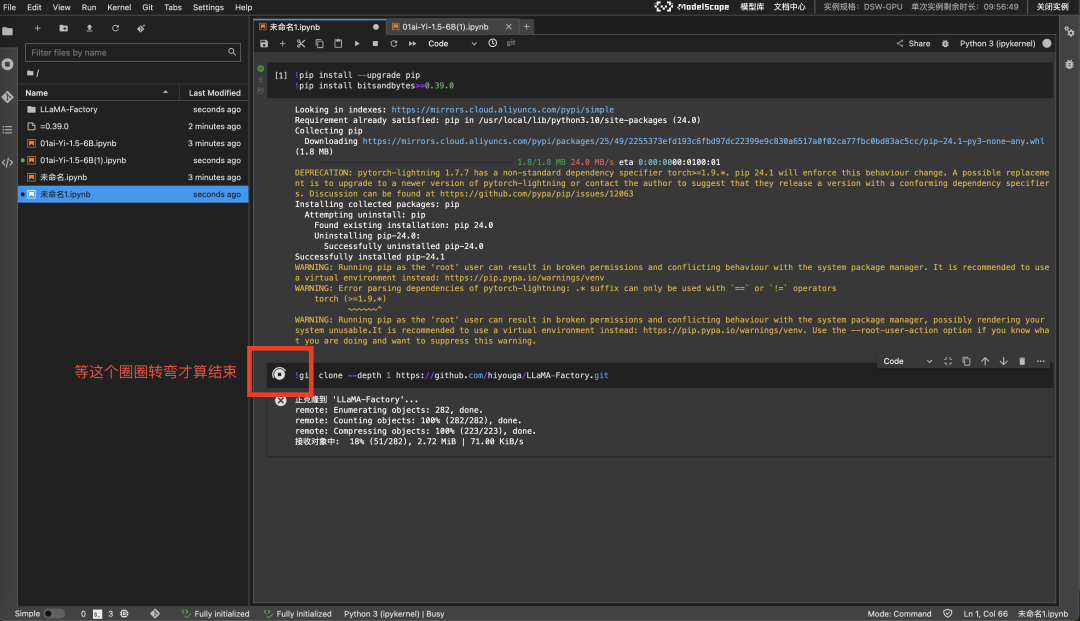
接下来需要去 Launcher > Terminal 执行(按照图片剪头指示操作)。
安装依赖的软件,这步需要的时间比较长。


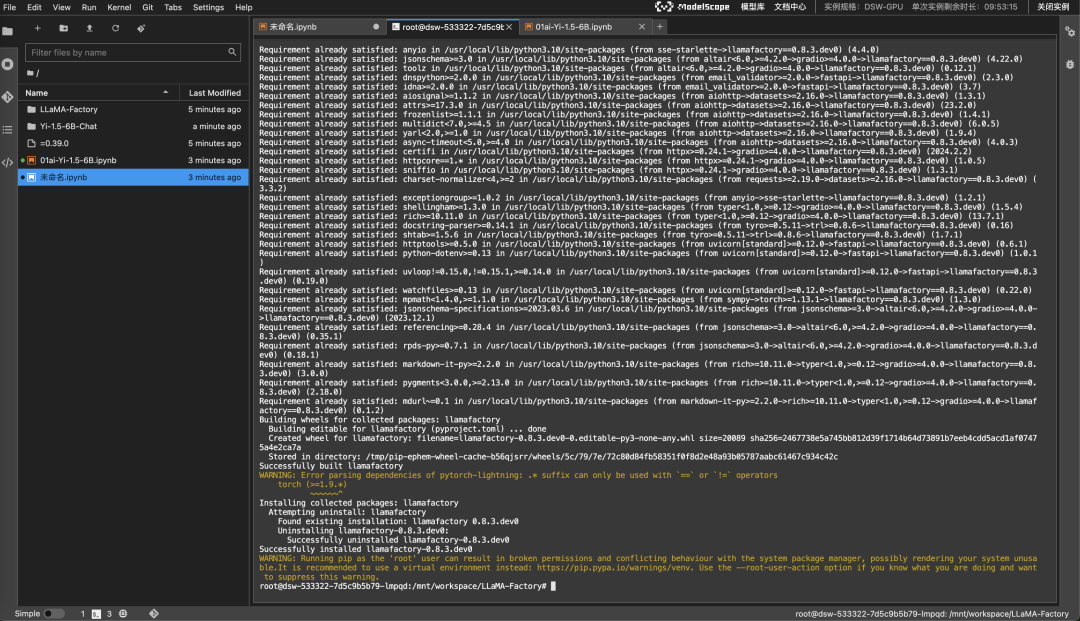
等以上所有步骤完成后,再进行下面的操作。
2. 下载模型
零一万物的 Yi 开源大语言模型的权重可以在HuggingFace和ModelScope上找到,这里我选择从ModelScope上下载。
零一万物的所有开源模型链接在这里:
https://www.modelscope.cn/organization/01ai/
模型下载需要一定的时间,这里选择了最小的Yi-1.5-6B-chat模型进行实验。
模型的说明在这里:
https://www.modelscope.cn/models/01ai/Yi-1.5-6B-Chat/summary
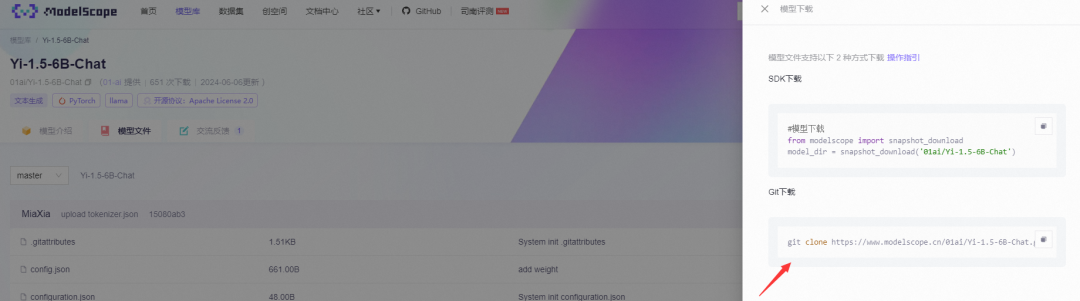
Yi-1.5-6B-chat模型大小大约12G,下载大约需要10分钟(取决于网速)。
接下来,你通过下面的命令就可以在 notebook 里执行下载(在 terminal也一样,如果需要在terminal执行需要去掉前面的!)。


这一步,耐心等待下载完成即可。
3. 微调Yi模型实战
等以上所有步骤完成后,准备工作就做好了,现在可以开始准备微调了。
⚠️注意:虽然本篇文章仅仅是简单的过一遍微调的流程,但是不要低估他的难度。微调跑起来很容易,但是跑出很好的结果非常的难。
开源社区有许多非常优秀的专门用于微调代码库具体的你可以参考这里:
https://github.com/01-ai/Yi-1.5?tab=readme-ov-file#fine-tuning
站在巨人的肩膀上开始这次实战,这里选择llama_factory。
LLaMA Factory是一款开源低代码大模型微调框架,集成了业界广泛使用的微调技术。llama_factory 的介绍可以在这里查看:
https://github.com/hiyouga/LLaMA-Factory
4. 开始微调
a. 创建微调训练相关的配置文件
在左侧的文件列表,Llama-Factory的文件夹里,打开examples\train_qlora(注意不是 train_lora)下提供的llama3_lora_sft_awq.yaml,复制一份并重命名为yi_lora_sft_bitsandbytes.yaml。
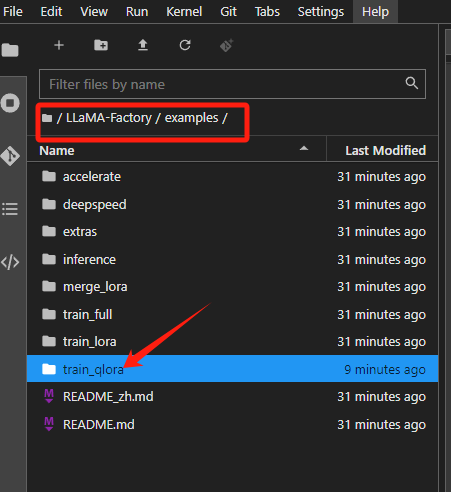
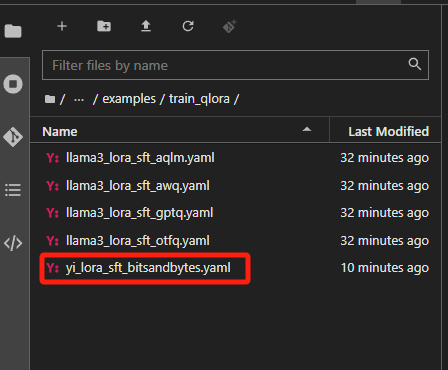
这个文件里面写着和微调相关的关键参数。
打开这个文件,将第一行model_name_or_path更改为你下载模型的位置。

同样修改其他行的内容,下面是我的修改,你可以逐行对比一下,有不一致或缺少的就添加一下。

从上面的配置文件中可以看到,本次微调的数据集是 identity。
那这个文件里面写着什么呢?
你可以打开这个文件看一下:https://github.com/hiyouga/LLaMA-Factory/blob/main/data/identity.json。

微调数据集是“自我认知”,也就是说当你问模型“你好你是谁”的时候,模型会告诉你我叫name由author开发。
如果你把数据集更改成你自己的名字,那你就可以微调一个属于你自己的大模型。
这一步,你可以将 identity.json 中的 {{name}} 字段替换为你的名字来微调一个属于自己的大模型。
保存刚才对于 yi_lora_sft_bitsandbytes.yaml 文件的更改,回到终端terminal。
在 LLaMA-Factory 目录下,输入以下命令启动微调脚本(大概需要10分钟)
llamafactory-cli train examples/train_qlora/yi_lora_sft_bitsandbytes.yaml
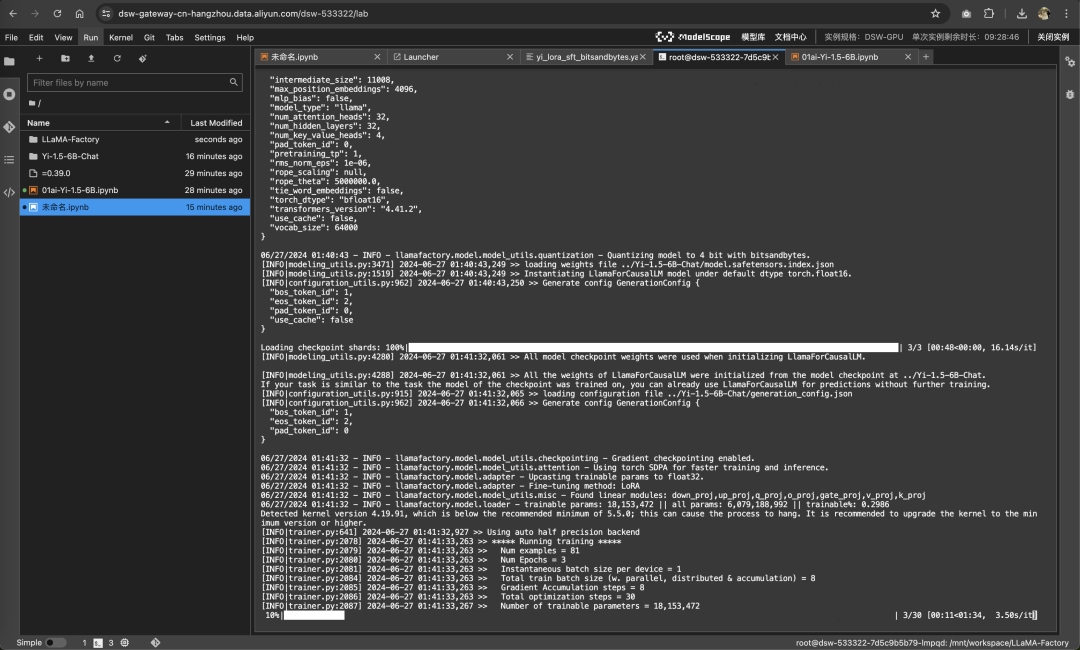
看到进度条就是开始微调了。
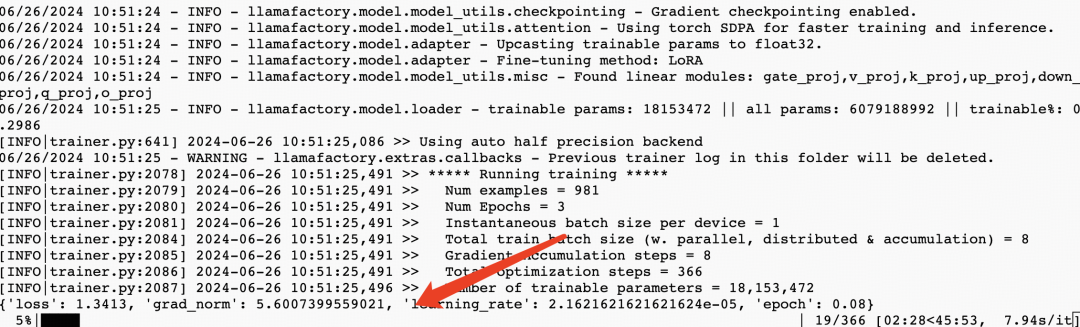
运行过程大概需要10分钟,当你看到下面这个界面的时候,微调过程就结束了。
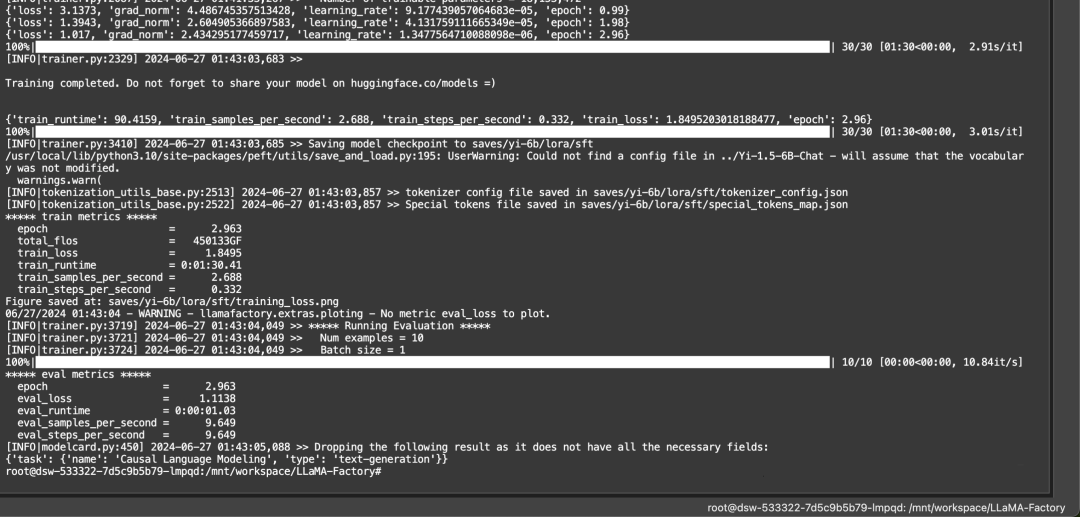
5. 推理测试
微调后的模型有什么不同的地方呢?
这里加载微调后模型进行推理,测试微调前后变化。
参考Llama-Factory文件夹中,examples\inference下提供的llama3_lora_sft.yaml,复制一份,并重命名为 yi_lora_sft.yaml
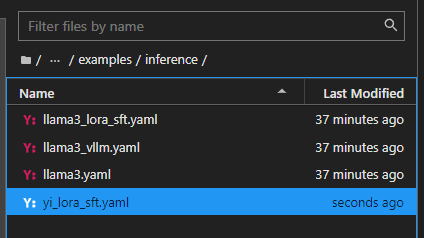
将内容更改为,并且保存(一定记得保存)****。

回到刚刚结束微调的终端Terminal,运行下面的推理命令(同样在Llama-Factory目录下运行)。

稍微等待一下模型加载,然后就可以聊天了。
可以看到模型的自我身份认知被成功的更改了。
自我身份认知更改成为数据集规定的样子了,同时也保持了通用对话能力。
那么,和没有经过微调之前的模型对比有什么差别呢?
重复上面的步骤,将llama3.yaml复制并重命名为yi.yaml,将内容更改为以下的内容,并保存(一定记得保存)。

回到终端Terminal,运行下面的推理命令:
llamafactory-cli chat examples/inference/yi.yaml
可以提问和刚才同样的问题,看到模型的原始回答。

基于本实验,你就完成了一个简单的微调,完整的走了一遍模型的微调过程,是不是还挺简单的?
如何学习AI大模型?
大模型时代,火爆出圈的LLM大模型让程序员们开始重新评估自己的本领。 “AI会取代那些行业?”“谁的饭碗又将不保了?”等问题热议不断。
不如成为「掌握AI工具的技术人」,毕竟AI时代,谁先尝试,谁就能占得先机!
但是LLM相关的内容很多,现在网上的老课程老教材关于LLM又太少。所以现在小白入门就只能靠自学,学习成本和门槛很高
针对所有自学遇到困难的同学们,我帮大家系统梳理大模型学习脉络,将这份 LLM大模型资料 分享出来:包括LLM大模型书籍、640套大模型行业报告、LLM大模型学习视频、LLM大模型学习路线、开源大模型学习教程等, 😝有需要的小伙伴,可以 扫描下方二维码领取🆓↓↓↓
👉[CSDN大礼包🎁:全网最全《LLM大模型入门+进阶学习资源包》免费分享(安全链接,放心点击)]()👈

学习路线

第一阶段: 从大模型系统设计入手,讲解大模型的主要方法;
第二阶段: 在通过大模型提示词工程从Prompts角度入手更好发挥模型的作用;
第三阶段: 大模型平台应用开发借助阿里云PAI平台构建电商领域虚拟试衣系统;
第四阶段: 大模型知识库应用开发以LangChain框架为例,构建物流行业咨询智能问答系统;
第五阶段: 大模型微调开发借助以大健康、新零售、新媒体领域构建适合当前领域大模型;
第六阶段: 以SD多模态大模型为主,搭建了文生图小程序案例;
第七阶段: 以大模型平台应用与开发为主,通过星火大模型,文心大模型等成熟大模型构建大模型行业应用。

👉学会后的收获:👈
• 基于大模型全栈工程实现(前端、后端、产品经理、设计、数据分析等),通过这门课可获得不同能力;
• 能够利用大模型解决相关实际项目需求: 大数据时代,越来越多的企业和机构需要处理海量数据,利用大模型技术可以更好地处理这些数据,提高数据分析和决策的准确性。因此,掌握大模型应用开发技能,可以让程序员更好地应对实际项目需求;
• 基于大模型和企业数据AI应用开发,实现大模型理论、掌握GPU算力、硬件、LangChain开发框架和项目实战技能, 学会Fine-tuning垂直训练大模型(数据准备、数据蒸馏、大模型部署)一站式掌握;
• 能够完成时下热门大模型垂直领域模型训练能力,提高程序员的编码能力: 大模型应用开发需要掌握机器学习算法、深度学习框架等技术,这些技术的掌握可以提高程序员的编码能力和分析能力,让程序员更加熟练地编写高质量的代码。

1.AI大模型学习路线图
2.100套AI大模型商业化落地方案
3.100集大模型视频教程
4.200本大模型PDF书籍
5.LLM面试题合集
6.AI产品经理资源合集
👉获取方式:
😝有需要的小伙伴,可以保存图片到wx扫描二v码免费领取【保证100%免费】🆓

这篇关于【实践】学大模型必看!手把手带你从零微调大模型!的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





