本文主要是介绍[Python]使用Scrapy爬虫框架简单爬取图片并保存本地,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
初学Scrapy,实现爬取网络图片并保存本地功能
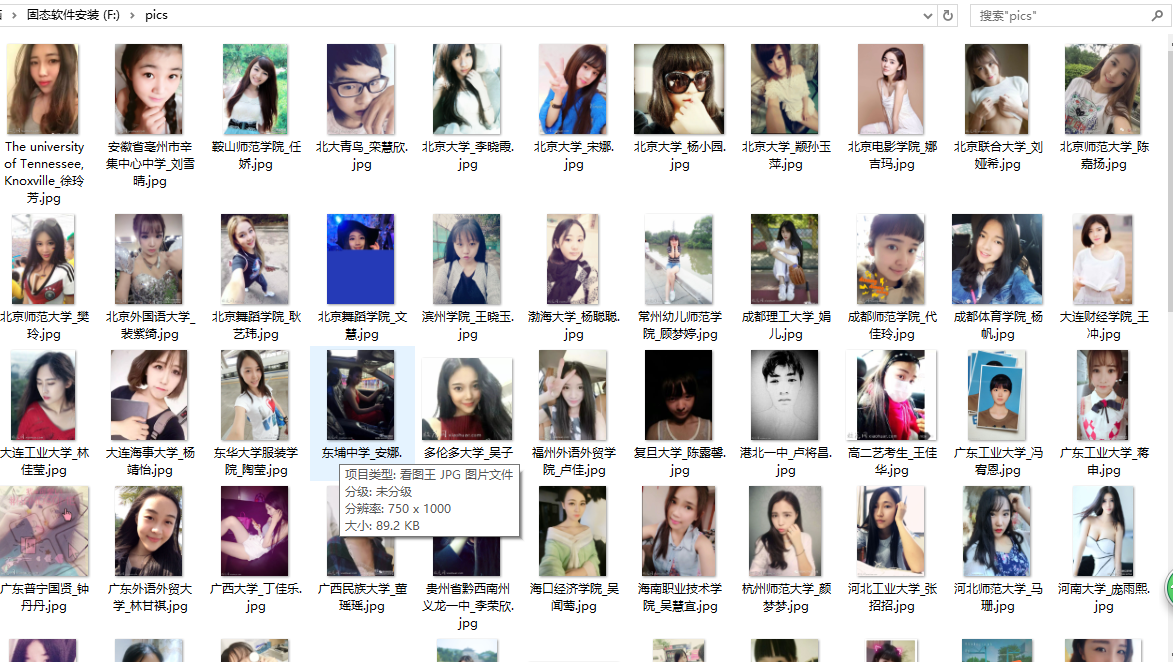
一、先看最终效果
保存在F:\pics文件夹下
二、安装scrapy
1、python的安装就不说了,我用的python2.7,执行命令pip install scrapy,或者使用easy_install 命令都可以
2、可能会报如下错误
***********************************************************
Could not find function xmlCheckVersion in library libxml2. Is libxml2 installed?
***********************************************************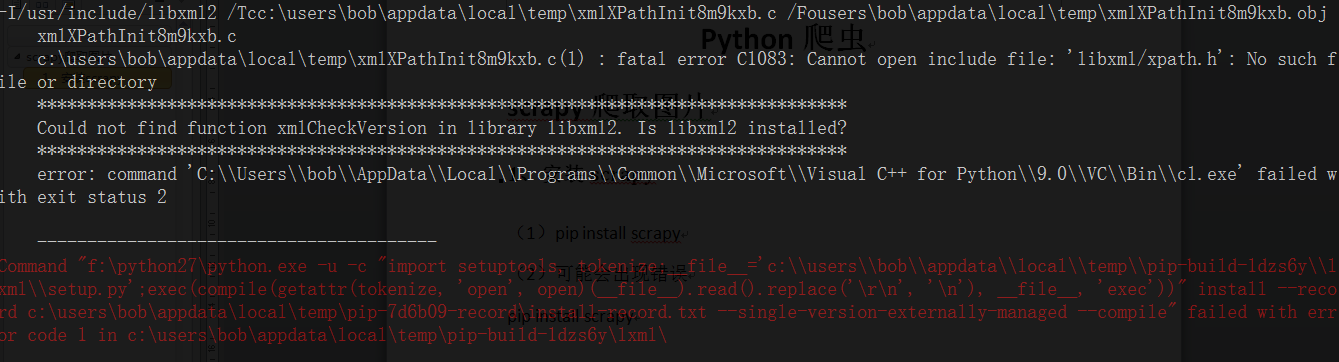
解决方法:安装libxml2
下载对应的python的版本,安装即可,网址:
https://pypi.python.org/pypi/lxml/3.4.4
三、创建项目
1、执行命令
scrapy startproject xiaohuar会自动创建xiaohuar的scrapy项目
2、项目结构(我用的是WingIDE)
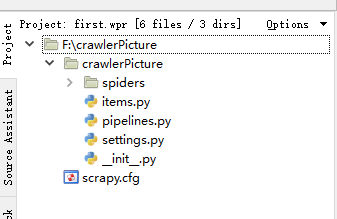
文件说明:
• scrapy.cfg 项目的配置信息,主要为Scrapy命令行工具提供一个基础的配置信息。(真正爬虫相关的配置信息在settings.py文件中)
• items.py 设置数据存储模板,用于结构化数据,如:Django的Model
• pipelines 数据处理行为,如:一般结构化的数据持久化
• settings.py 配置文件,如:递归的层数、并发数,延迟下载等
• spiders 爬虫目录,如:创建文件,编写爬虫规则
四、编写爬虫程序
1、在spiders文件夹下创建.py文件
代码中注释已经很详细了,就不解释了,关于解析html内容,使用的是xpath,之前使用java的webmagic 爬虫框架也是使用的此种方式,所示还是比较熟悉,一些插叙语法参考步骤2
# -*- coding:utf-8 -*-
import scrapy
import re
import os
import urllib
from scrapy.selector import Selector
from scrapy.http import HtmlResponse,Requestclass Xiaohuar_spider(scrapy.spiders.Spider):name="xiaohuar"#定义爬虫名allowed_domains=["xiaohuar.com"] #搜索的域名范围,也就是爬虫的约束区域,规定爬虫只爬取这个域名下的网页start_urls=["http://www.xiaohuar.com/list-1-1.html"]#该函数名不能改变,因为Scrapy源码中默认callback函数的函数名就是parsedef parse(self, response):current_url=response.url #爬取时请求的urlbody=response.body #返回的htmlunicode_body=response.body_as_unicode() #返回的html unicode hxs=Selector(response) #创建查询对象,HtmlXPathSelector已过时if re.match('http://www.xiaohuar.com/list-1-\d+.html', response.url):#如果url能够匹配到需要爬取的url,就爬取items=hxs.xpath('//div[@class="item_list infinite_scroll"]/div')#匹配到大的div下的所有小div(每个小div中包含一个图片)for i in range(len(items)):#遍历div个数src=hxs.xpath('//div[@class="item_list infinite_scroll"]/div[%d]//div[@class="img"]/a/img/@src'%i).extract() #查询所有img标签的src属性,即获取校花图片地址name=hxs.xpath('//div[@class="item_list infinite_scroll"]/div[%d]//div[@class="img"]/span/text()'%i).extract() #获取span的文本内容,即校花姓名school=hxs.xpath('//div[@class="item_list infinite_scroll"]/div[%d]//div[@class="img"]/div[@class="btns"]/a/text()'%i).extract()#校花学校if src:absoluteSrc="http://www.xiaohuar.com"+src[0] #拼接实际路径,因为.extract()会返回一个list,但是我们是依次取得div,所以是取第0个file_name="%s_%s.jpg"%(school[0],name[0])#拼接文件名,学校_姓名file_path=os.path.join("F:\\pics",file_name)#拼接这个图片的路径,我是放在F盘的pics文件夹下urllib.urlretrieve(absoluteSrc,file_path)#接收文件路径和需要保存的路径,会自动去文件路径下载并保存到我们指定的本地路径all_urls = hxs.xpath('//a/@href').extract()#提取界面所有的urlfor url in all_urls:#遍历获得的url,如果满足条件,继续爬取if url.startswith('http://www.xiaohuar.com/list-1-'):yield Request(url, callback=self.parse)
2、xpath查询语法
查询标签中带有某个class属性的标签://div[@class=’c1’]即子子孙孙中标签是div且class=‘c1’的标签
• 查询标签中带有某个class=‘c1’并且自定义属性name=‘alex’的标签://div[@class=’c1’][@name=’alex’]
• 查询某个标签的文本内容://div/span/text() 即查询子子孙孙中div下面的span标签中的文本内容
• 查询某个属性的值(例如查询a标签的href属性)://a/@href
3、运行
进入到xiaohuar目录,执行
scrapy crawl xiaohuar
可能会报以下错误,原因是少win32api的模块
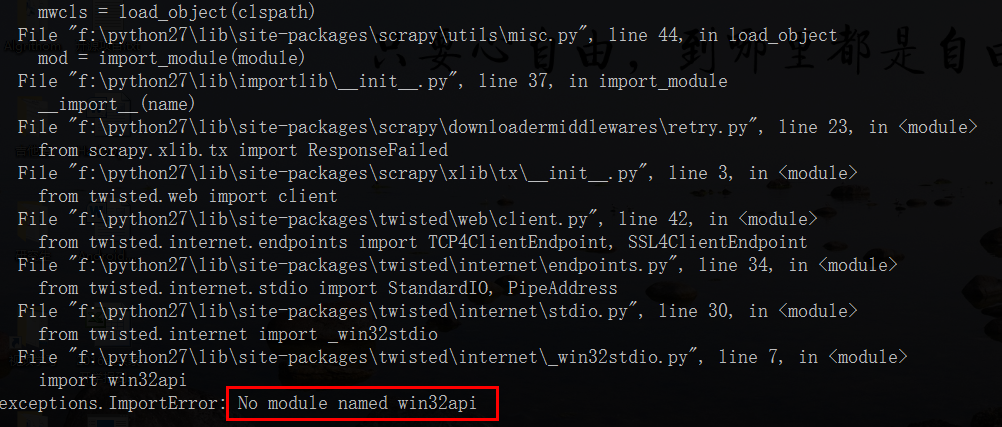
解决方法:
选择对应的版本下载安装即可地址:
http://sourceforge.net/projects/pywin32/files/
4、关于scrapy shell终端
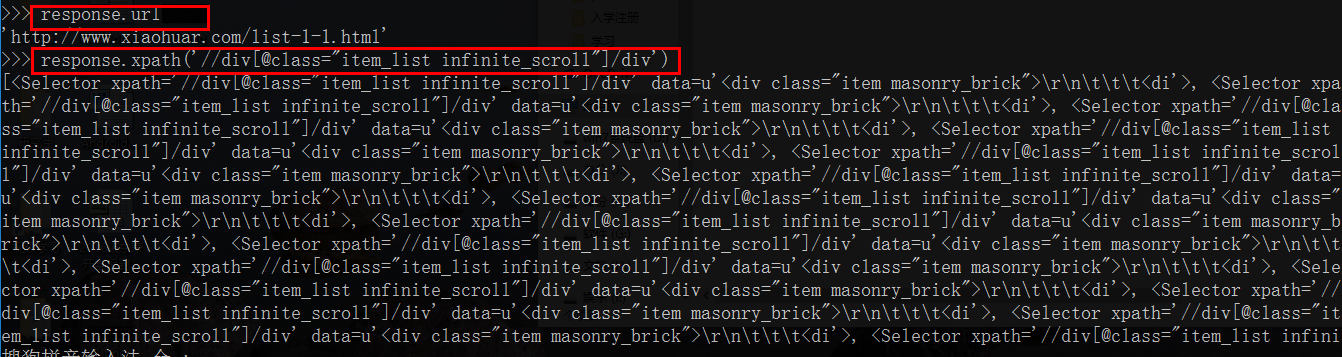
可以使用scrapy shell进行调试,例如执行
scrapy shell http://www.xiaohuar.com/list-1-1.html
就可以查看得到的数据
5、最后的说明
程序执行过程中可以设置爬取的深度,我这里没有设置,可能关掉cmd程序还在执行,可以结束python的进程,或者设置爬取深度
程序放到了github上,地址:
https://github.com/lawlite19/CrawlPicture_Scrapy
五、总结
最近学习在python,实现非常简单的一个爬虫当做练习,中间一些模块的缺少错误,在网上查询还是费了很多的时间,有的回答是没有解决的,总之自己实践之后才会更加深刻。
这篇关于[Python]使用Scrapy爬虫框架简单爬取图片并保存本地的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!



