本文主要是介绍forEach和map遍历大数据,到底谁更快?实践出真知,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
你好同学,我是沐爸,欢迎点赞、收藏、评论和关注。
针对大量数据进行遍历时,forEach和map相比,谁的的性能更高,执行的更快?你觉得呢?先百度一下

但是,今天我没选择相信搜索结果,我决定测试一下。我不仅仅测试了forEach和map,还带上了for,结果出乎意料!
我创建一个包含一亿个元素的数组,对三个方法分别执行相同的求和操作:
forEach
const largeArray = Array.from({ length: 100000000 }, (_, index) => index);let total = 0;
console.time("forEach");
largeArray.forEach((item) => {total += item;
});
console.timeEnd("forEach");
map
const largeArray = Array.from({ length: 100000000 }, (_, index) => index);let total = 0;
console.time("map");
largeArray.map((item) => {total += item;
});
console.timeEnd("map");
for
const largeArray = Array.from({ length: 100000000 }, (_, index) => index);let total = 0;
console.time("for");
for (let i = 0; i < largeArray.length; i++) {total += largeArray[i];
}
console.timeEnd("for");
在浏览器中,将三个方法分别运行5次操作,单位ms,最后一行为均值,结果如下:

从结果看,如果用时长排序性能,性能从高到低应该依次是 for > forEach > map。1个亿的数据,好像有点太多了,那就再看看其他量级的比较。
为了相对充分地验证数据的可靠性,覆盖更全面,我将数组元素的数量依次调成了1万、10万、100万、1000万并运行,结果如下,红色部分为均值:
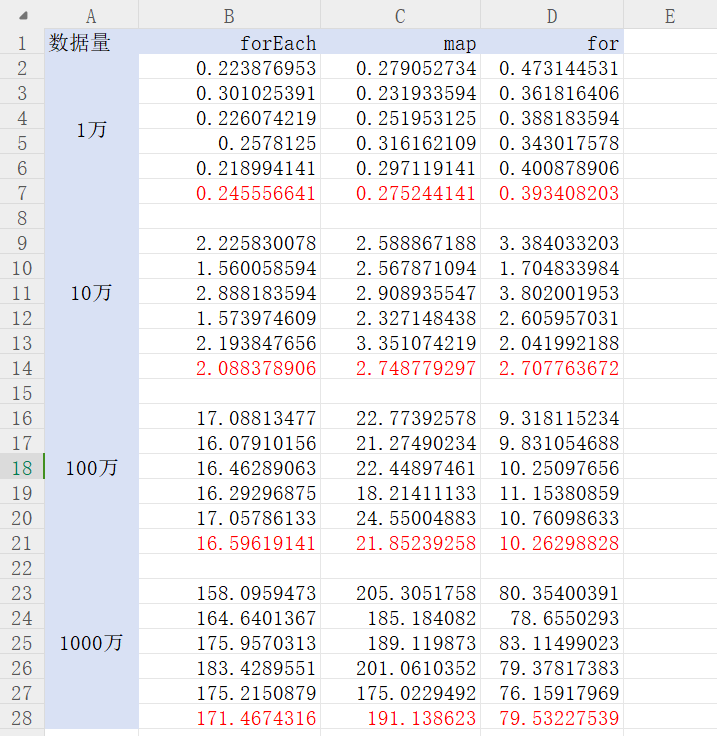
从上图中可以得出以下结论:
- 无论在哪个量级,forEach的性能高于map。
- 在10万级别数据以下,for的性能一般,通常低于另外两个。
- 数据量越大,达到百万级以上时,for的性能最高,其次是forEach,最后是map。
古人云,实践出真知,说的真不错。网上说的未必都是对的,有方法的还是可以测试下。我测试的数据量少,数组元素及操作也简单,所以结论未必完全正确。有实际超大数据处理经验的同学可以发表下意见。还有感兴趣的同学可以自己多试试,看看我们的结论是否一致,期待你的评论!
好了,分享结束,谢谢点赞,下期再见
这篇关于forEach和map遍历大数据,到底谁更快?实践出真知的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







