本文主要是介绍jenkins远程部署使用shell脚本进行备份与find和grep匹配的区别,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
需求
公司想jenkins在远程部署项目的同时,还要进行项目备份,
之前只备份最近一次构建的数据,也就是只保留到一份,
现在公司希望能保留按时间进行倒序,保留三份备份包。
思路
1、使用rm -rf 文件名把我们要保留的三份备份包排除掉。
2、要排除查询到的文件,可以使用grep -v命令。排除多少个可以使用head -n 3
rm -rf `ls | grep "ggservice-dataservice-.*" | grep -v `find . -name "ggservice-dataservice-*" | xargs ls -t | head -n 3|xargs|sed "s/.\///g"|xargs|sed "s/ /\\\\\\|/g"``这么一条命令太长了。我们使用变量的方式:
# 打包的文件名
fileName="ggservice-dataservice"backup=`find . -name "${fileName}-*" | xargs ls -t | head -n 3|xargs|sed "s/.\///g"|xargs|sed "s/ /\\\\\\|/g"`
echo "保留最近三个备份包:" \"$backup\"
echo "删除的备份包:"`ls | grep "${fileName}-.*" | grep -v $backup`
#删除ggservice的备份包
rm -rf `ls | grep "${fileName}-.*" | grep -v $backup`1、我们先查询出需要保留的三个备份包。
backup=`find . -name "${fileName}-*" | xargs ls -t | head -n 3|xargs|sed "s/.\///g"|xargs|sed "s/ /\\\\\\|/g"`①首先find命令去模糊查询文件名为ggservice-dataservice-*。
find和grep匹配的区别
注意: find命令中
*号表示是通配符,而不是正则表达式。 grep 中的则是正则表达式。
Linux通配符与正则表达式
http://blog.csdn.net/nybornhawk/article/details/43730667
详细区别,自己百度吧!
以我自己例子;查询结果为:
./ggservice-dataservice-20161210
./ggservice-dataservice-20161211
./ggservice-dataservice-20161209
./ggservice-dataservice-20161202
./ggservice-dataservice-20161212看到这个我们肯定希望把它们拼成如下形式:
ggservice-dataservice-20161212\|ggservice-dataservice-20161211\|ggservice-dataservice-20161202为什么要拼成这种实现呢?
我们要知道grep -v同时排除多个文件的方法是这样的!
grep -v 'aaaa\|bbbb'也就是说当有多个文件时,需要 |,进行分割,但是在Linux中|是管道的意思,
所以需要使用反斜杠进行转义;所以是\|。
②xargs ls -t 是进行按日期排序(倒序)。
③head -n 3 取前三个。
④xargs|sed "s/.\///g"把查询文件结果中 ./ 去除掉。
sed是 正则 替换 格式:s/填写需要替换字符/填写需要替换成什么字符/g
s/被替换字符1/替换字符/g
⑤xargs|sed "s/ /\\\\\|/g" 把查询文件结果中的空格替换成|。
这里说明下⑤,在命令行中写成三个反斜杠即xargs|sed "s/ /\\\|/g",但是写到shell里,或是赋值给一个变量时,会把反斜杠弄没了:
ggservice-dataservice-20161212|ggservice-dataservice-20161211|ggservice-dataservice-20161202后来经过我不断尝试,连续五个反斜杠就可以啦!即便是赋值给变量也是可以的。
最后backup变量得到的就是:
ggservice-dataservice-20161212\|ggservice-dataservice-20161211\|ggservice-dataservice-20161202有了这个后,我们就可以开始删除了。
#删除ggservice的备份包
rm -rf `ls | grep "^${fileName}-.*" | grep -v $backup`①rm -rf 文件名,由于文件名是通过命令来查询出来的。所以需要使用`符号包裹起来, grep “^${fileName}-.”
也就是键盘数字1左边的那个键。
②这里面的.是正则表达式,匹配查询到相应格式的文件。 ^
这里添加这个符号表示的是以指定字符开头进行匹配。 grep -v $backup`这里是排除掉我需要备份的文件。即不删除它们,其余匹配查询到的文件都进行删除。
③
至此,我的需求已经达到要求了。
下面是我自己写的完整脚本:
#!/bin/bash
export PATH=~/gogoal_platform/ggopenapi:~/play-1.2.7:$PATH
echo "构建后的路径pwd:"`pwd`
whoami
cd /home/developer/gogoal_platform/ggopenapi/
cur=$(pwd)
currday=`date +%Y%m%d`
# 打包的文件名
fileName="api"#创建最新的备份包
gogalwebfile=${cur}/${fileName}-$currday
if [ ! -d $gogalwebfile ]; then
echo "不存在":$gogalwebfile
cp -r ${fileName} ${fileName}-$currday
fibackup=`ls -lt | find . -name "${fileName}-*" | sort -r | head -n 3|xargs|sed "s/.\///g"|xargs|sed "s/ /\\\\\\|/g"`
echo "保留最近三个备份包:" \"$backup\"
echo "删除的备份包:"`ls | grep "^${fileName}-.*" | grep -v $backup`
# 删除备份包
rm -rf `ls | grep "^${fileName}-.*" | grep -v $backup | xargs | sed "s/ / /g"`# 将分批打包的jar拷贝到ggservice项目中
cp -r package/* /home/developer/gogoal_platform/ggopenapi/api/ggservice/
rm -rf packagecd /home/developer/gogoal_platform/ggopenapi/api/ggservice/cp /dev/null nohup.out
nohup ./ggservice.sh更新
注:
2017-2-15修改:
1、
backup=`ls -lt | find . -name "${fileName}-*" | sort -r | head -n 3|xargs|sed "s/.\///g"|xargs|sed "s/ /\\\\\\|/g"`添加了sort -r,因为在使用ls -lt排序后,再使用find命令,会导致之前排好的顺序变成无须,所以再使用sort命令在排序一次,sort默认是升序,所以我们要进行添加参数-r,进行取反。
2、由于我打包的是.class文件,命令如下:
#!/bin/bash
export PATH=~/play-1.2.7:$PATH
#获得当前目录
cur=$(pwd)
echo "pwd:"${cur}
rm -rf ggservice-dataservice.jar
output_path=${cur}/classes
package=${cur}/package
echo $output_path
if [ ! -d $output_path ]; thenmkdir $output_path
fiif [ ! -d $package ]; thenmkdir $package
fi## 获取依赖库和需要编译的java文件
export libs=`find ./dataservice/lib -name "*.jar" |xargs|sed "s/ /:/g"`
export javafiles=`find ./dataservice/ -name "*.java" |xargs|sed "s/ / /g"`
export javautils=`find ./utils/app/ -name "*.java" |xargs|sed "s/ / /g"`
export play_lib=/opt/play-1.2.7/framework/play-1.2.7.jar
export play_lib_common=`find /opt/play-1.2.7/framework/lib/ -name "*.jar" |xargs|sed "s/ /:/g"`
#echo ${javafiles}
#echo "公共---------"
#echo ${javautils}# 清除
rm -rf package/*
# 清除编译后的class文件
rm -rf ${output_path}/*##编译
javac -d ${cur}/classes -cp ${libs}:$play_lib:$play_lib_common -encoding utf-8 ${javafiles} ${javautils}
##打包
cd /home/jenkins/workspace/ggservice/dataservice/app/ggservice/v1/
dir=$(ls -l |awk '/^d/ {print $NF}')
cd $output_path
for i in $dir
doecho "ggservice-"${i}".jar打包情况":jar -cvf ${package}/ggservice-${i}.jar */v1/$i/*
done每次打jar包的时候,最好先清除class文件,今天就这个原因导致浪费很多时间。
# 清除编译后的class文件
rm -rf ${output_path}/*2017-6-22修改:
今天偶然发现执行上面的脚本居然把不想删除的文件给删除啦!
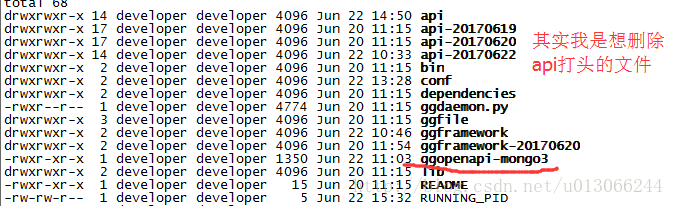
结果呢?其把ggopenapi-mongo3这个文件也删除啦!

看了看我的脚本:
echo "删除的备份包:"`ls | grep "${fileName}-.*" | grep -v $backup`由于grep是正则匹配,所以只要包含指定的字符就匹配成功,所以呢,我们需要加上^。
echo "删除的备份包:"`ls | grep "^${fileName}-.*" | grep -v $backup`这篇关于jenkins远程部署使用shell脚本进行备份与find和grep匹配的区别的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





