本文主要是介绍数据融合的超速引擎——SeaTunnel,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!

概览
SeaTunnel是一个由Apache软件基金会孵化的数据集成工具,专为应对大规模数据的快速处理而设计。它以高效的数据处理能力和简洁的架构,帮助企业在数据仓库构建、实时数据处理和数据迁移等场景下,实现数据流的无缝整合。SeaTunnel的设计理念是将复杂性封装在后端,让用户通过简单的操作即可完成复杂的数据处理任务。
SeaTunnel的灵活性体现在其丰富的插件生态系统上。用户可以根据不同的数据源和目标需求,选择合适的插件进行数据的读取、转换和写入。这种模块化的设计不仅提高了系统的可扩展性,也使得SeaTunnel能够适应多变的数据处理需求。此外,SeaTunnel的分布式架构确保了在处理大规模数据时的高吞吐量和低延迟,为用户提供了稳定可靠的数据处理体验。
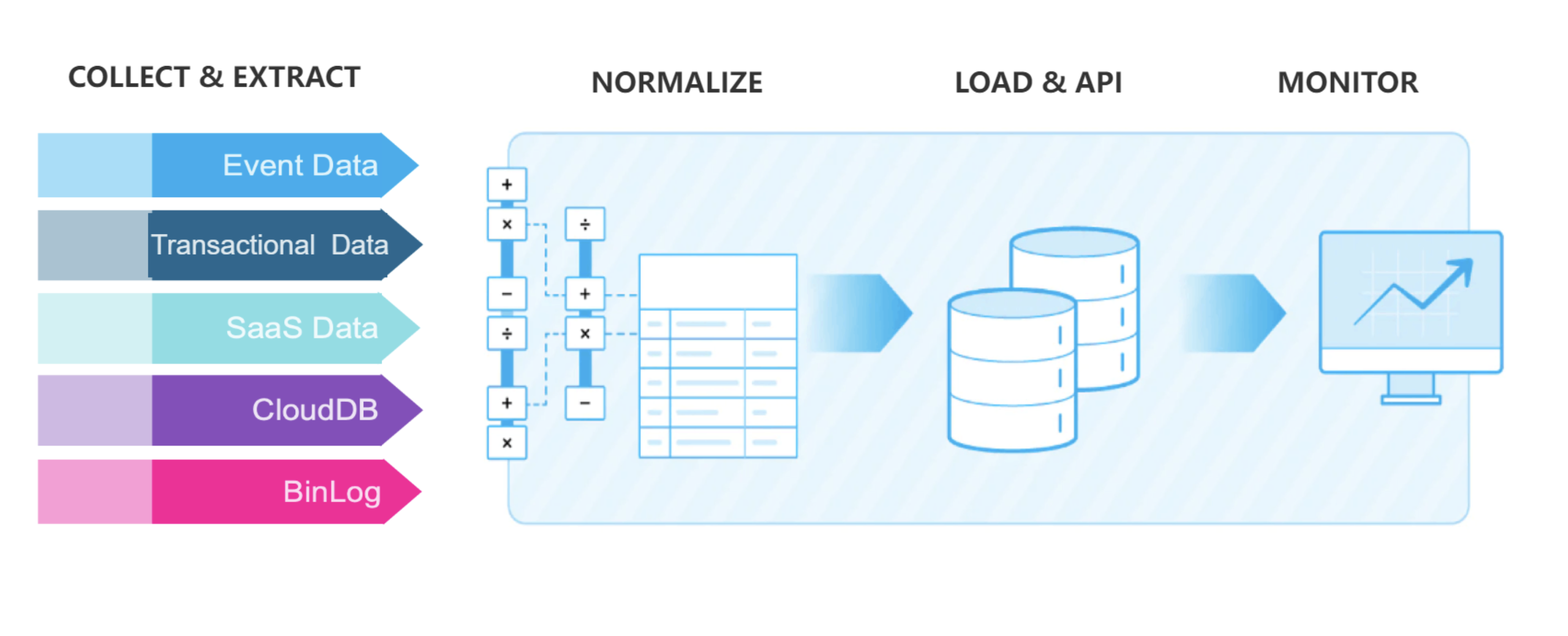
主要功能
你可以进入官网阅览更多:https://seatunnel.apache.org
插件系统
SeaTunnel的插件系统是其核心优势之一。它允许用户通过简单的配置即可连接到各种数据源和数据目的地。这些插件不仅支持常见的大数据技术栈,如Hadoop的HDFS和Hive,以及实时消息系统Kafka,还涵盖了关系型数据库、NoSQL数据库和云存储服务等多种数据存储选项。SeaTunnel的插件设计遵循标准化接口,使得开发者可以轻松扩展或自定义插件,以适应特定的业务需求或新兴的数据技术。
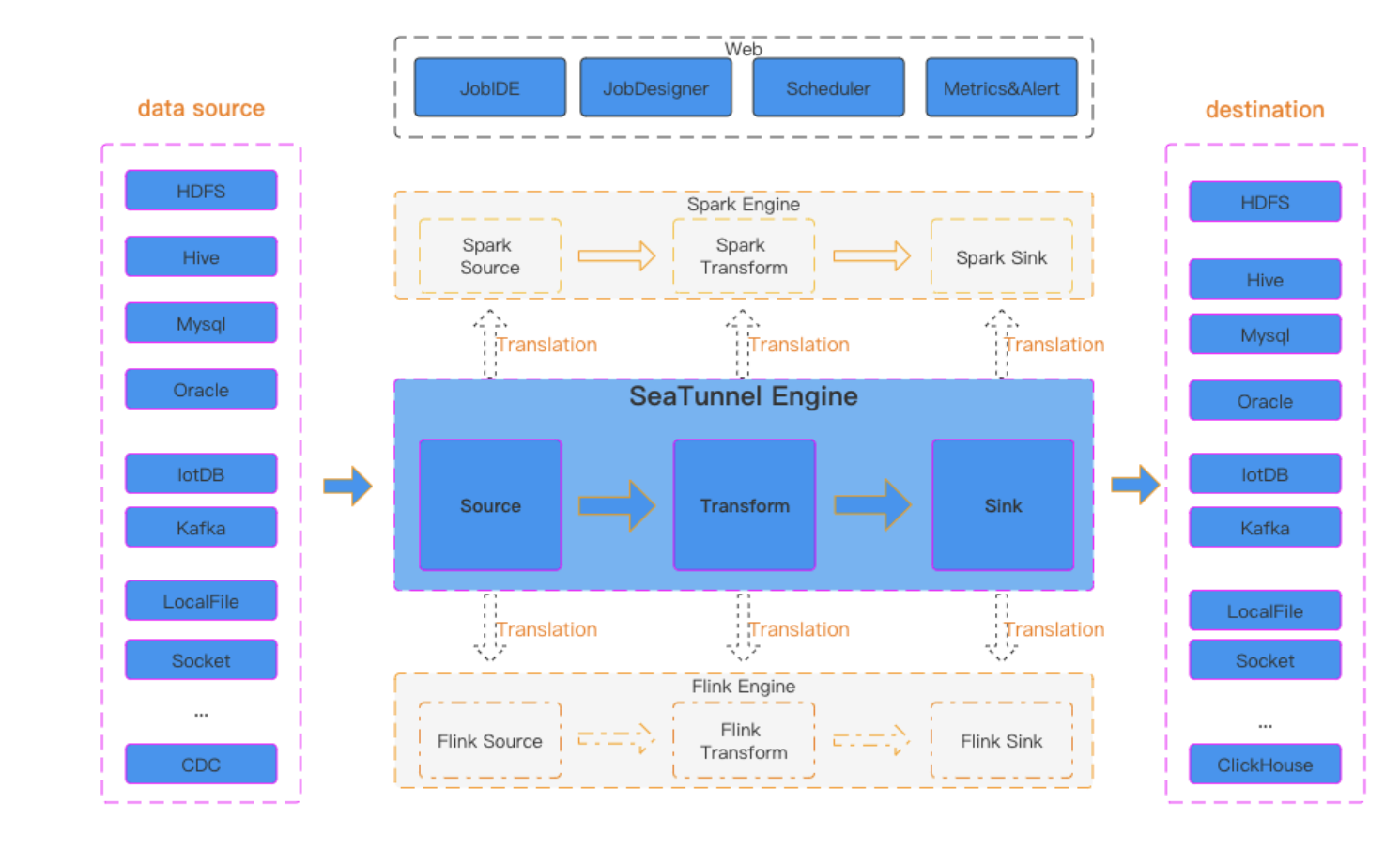
易用性
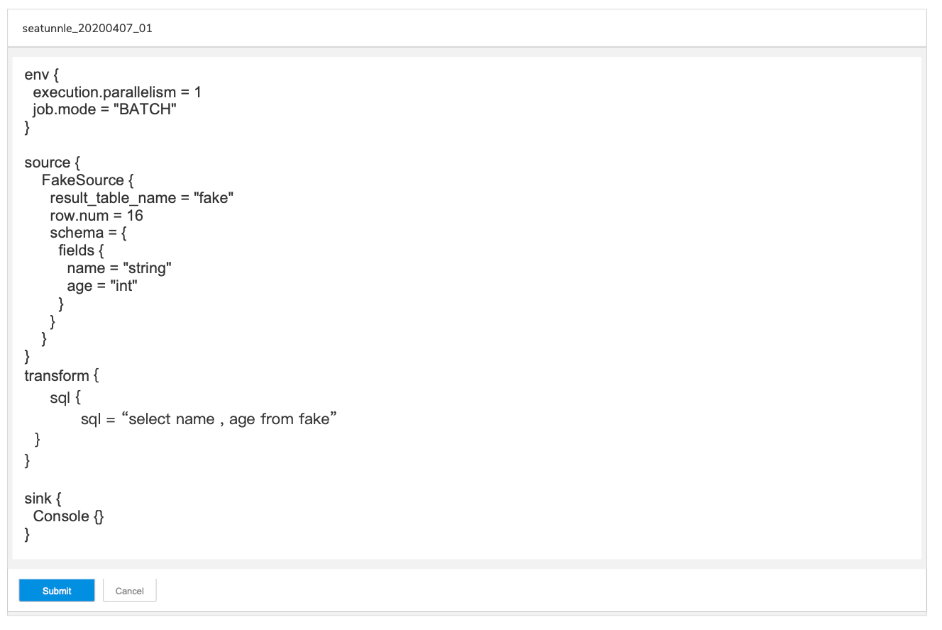
SeaTunnel注重用户体验,提供了直观的API和命令行界面。无论是通过编程方式还是直接在命令行中,用户都可以快速配置数据处理流程。SeaTunnel的文档详尽,提供了从安装到部署的逐步指导,确保用户能够快速掌握并有效利用SeaTunnel进行数据处理。此外,SeaTunnel的配置文件格式清晰,逻辑性强,便于用户理解和维护。
性能优化
SeaTunnel在性能方面进行了深入的优化。它采用了先进的执行引擎,能够智能地规划数据处理流程,减少不必要的数据移动和转换。SeaTunnel还支持多线程和并行处理,充分利用现代多核处理器的能力,加快数据处理速度。此外,SeaTunnel提供了丰富的配置选项,允许用户根据具体的硬件环境和数据特性调整性能参数,以达到最优的处理效率。

容错机制
SeaTunnel内置了强大的容错机制,确保了数据处理的高可靠性。在分布式环境中,节点的故障是不可避免的。SeaTunnel能够自动检测到节点故障,并重新分配任务到其他健康的节点上,从而最小化中断对数据处理流程的影响。此外,SeaTunnel还支持数据的自动重试和事务管理,确保数据处理的一致性和完整性。
信息
截至发稿概况如下:
-
软件地址:https://github.com/apache/seatunnel
-
软件协议:Apache-2.0 许可证
-
编程语言:
| 语言 | 占比 |
|---|---|
| Java | 99.5% |
| Other | 0.5% |
- 收藏数量:7.7K
SeaTunnel作为一个高性能的数据集成工具,虽然在多个方面表现出色,但在实际部署和使用过程中,用户可能会面临一些挑战。例如,某些特定的数据源或目的地可能需要定制化的插件来满足特定的数据处理需求,这可能涉及到额外的开发工作。此外,随着数据量的增长,SeaTunnel的性能可能需要进一步优化以保持高效处理。
为了应对这些挑战,SeaTunnel团队采取了积极的措施。首先,团队通过持续的性能监控和用户反馈,识别性能瓶颈,并针对性地进行优化。其次,SeaTunnel鼓励社区贡献,通过开放的插件开发框架,吸引更多的开发者参与到插件的定制和优化中来。这样不仅能够丰富SeaTunnel的功能,也能够提高其对各种数据源和目的地的兼容性。
各位在使用 SeaTunnel 的过程中是否发现了什么问题?或者对 SeaTunnel 的功能有什么提议?热烈欢迎各位在评论区分享交流心得与见解!!!
声明:本文为辣码甄源原创,转载请标注"辣码甄源原创首发"并附带原文链接。
这篇关于数据融合的超速引擎——SeaTunnel的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





