本文主要是介绍《数据资产管理核心技术与应用》读书笔记-第五章:数据服务(二),希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
《数据资产管理核心技术与应用》是清华大学出版社出版的一本图书,全书共分10章,第1章主要让读者认识数据资产,了解数据资产相关的基础概念,以及数据资产的发展情况。第2~8章主要介绍大数据时代数据资产管理所涉及的核心技术,内容包括元数据的采集与存储、数据血缘、数据质量、数据监控与告警、数据服务、数据权限与安全、数据资产管理架构等。第9~10章主要从实战的角度介绍数据资产管理技术的应用实践,包括如何对元数据进行管理以发挥出数据资产的更大潜力,以及如何对数据进行建模以挖掘出数据中更大的价值。
图书介绍:数据资产管理核心技术与应用
今天主要是给大家分享一下第五章的内容:
第五章的标题为数据服务
内容思维导图如下:
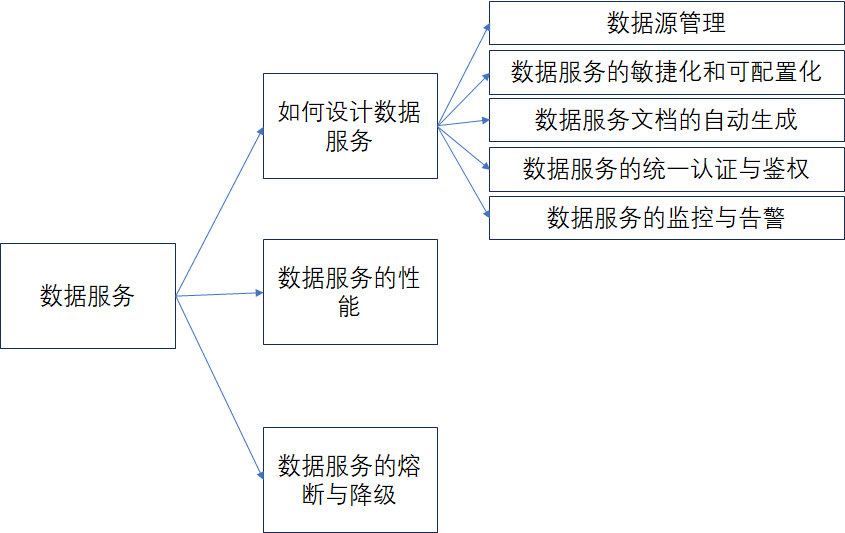
本文是接着
《数据资产管理核心技术与应用》读书笔记-第五章:数据服务(一)
继续往下讲。
1.5、 数据服务的监控与告警
在完成了数据服务的配置后,数据服务在调用时,还需要进行监控,在监控到发生故障时还需要支持自动发送告警通知信息,这样才能更好的保障数据服务的稳定性。在书中的数据监控与告警那一章节中,有提到数据服务的监控与告警的技术设计实现主要是通过异步采集数据服务的调用日志,然后再配合Prometheus与Grafana来完成,如下图所示。《数据资产管理核心技术与应用》是清华大学出版社出版的一本图书,作者为张永清等著
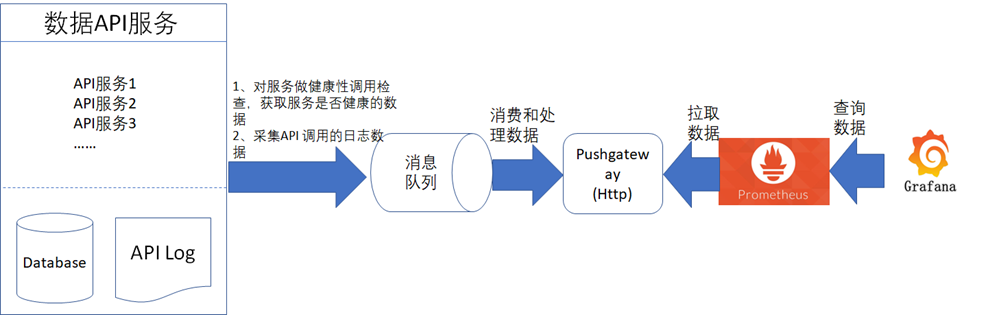
从图中可以看到数据服务的监控与告警的关键在于数据服务的日志数据采集,这就意味着数据服务在被调用时,需要输出日志,为了让数据服务的监控更加准确和细致,日志在设计时,通常建议包含如下表6中的常见字段。《数据资产管理核心技术与应用》是清华大学出版社出版的一本图书,作者为张永清等著
| 字段名称 | 字段描述 |
| appId | 被调用的数据服务的ID,这个ID代表了具体的某个数据服务的身份 |
| requestArgs | 调用数据服务时,传入的请求参数 |
| cliendIp | 数据服务平台端获取到请求方的IP地址 |
| requestTime | 请求方调用数据服务时的时间戳,通常建议精确到毫秒 |
| receiveTime | 数据服务平台端接收到请求的时间戳,通常建议精确到毫秒 |
| responseTime | 数据服务平台处理完请求后的响应给请求方结果时的时间戳,通常建议精确到毫秒 |
| queryDataDuration | 数据服务平台在查询数据过程中的耗时时长 |
| responseMessage | 数据服务平台处理完请求后响应给请求方的响应结果 |
| exception | 数据服务平台在处理请求的过程中发生的异常信息,如果没有异常时,该字段会保持为空 |
在输出日志时,可以通过JSON的格式,将表格中的字段都包含进去,然后再通过日志采集的方式采集到这些JSON日志后发送到消息队列中供数据处理程序做日志数据的解析,之后再发送到Prometheus的Pushgateway组件中。
常见的日志采集工具如下表所示。《数据资产管理核心技术与应用》是清华大学出版社出版的一本图书,作者为张永清等著
| 日志采集工具 | 描述以及下载与部署地址 |
| Flume | Apache 基金会下的开源项目,使用Java语言实现的日志采集工具,Github地址为https://github.com/apache/logging-flume |
| Logstash | 基于Pipeline 实现的开源日志采集工具,Github地址为https://github.com/elastic/logstash |
| Fluentd | 基于C/Ruby实现的可插拔开源日志数据采集工具,Github地址为https://github.com/fluent/fluentd |
| Splunk | 非开源的商业性质的日志采集和处理以及存储工具,官方网址为http://www.splunk.com/ |
在通过采集获取到JSON的日志数据后,经过对日志数据的加工处理后,通常可以生成如下的核心指标数据用于监控,如下图所示。
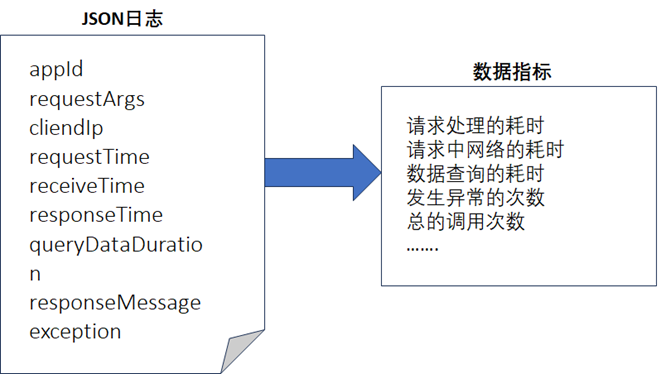
- 请求处理的耗时很长时,代表数据服务的处理很慢,此时需要检查是否是数据服务的处理能力或者服务器资源不够。
- 请求中网络的耗时很长时,很可能是网络的带宽不够或者网络经常性的出现了抖动等,需要对网络链路进行排查。
- 数据查询的耗时很长时,代表了查询数据库查询很慢,此时需要检查数据库中是否有慢查询或者是数据库的资源不够。
- 发生异常的次数代表了请求处理中发生了异常,如果异常次数达到了一定的阈值,那就需要排查是数据服务出现了故障还是请求方的请求参数错误等。
- 调用次数代表了请求方的调用量,也是衡量请求方请求并发是否很大的一个重要指标,如果调用量超过了数据服务的处理能力,需要及时增加资源进行扩容或者需要及时询问请求方为啥调用量会非常大的原因,同时也需要检查是否是数据服务受到了外部的恶意攻击导致的。
2、数据服务的性能
一个好的数据服务除了需要有好的设计外,还需要有好的性能,性能最直观的表现就是数据的查询能力,数据的查询能力越快,那么数据服务的性能肯定也会越好,通常情况下性能的优化主要体现在SQL优化、数据库优化、架构设计优化、硬件优化等几个方面,如下图所示。

- (一)、SQL优化:这个很容易理解,就是提高SQL语句的查询性能,定位一个SQL查询性能的常用步骤如下图所示。《数据资产管理核心技术与应用》是清华大学出版社出版的一本图书,作者为张永清等著
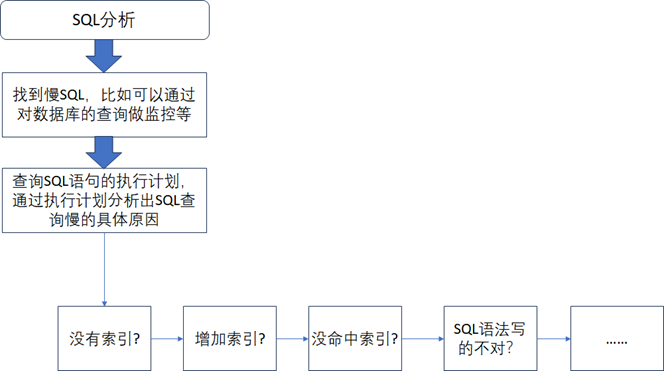
从图中可以看到:
第一步需要尽快的找到性能查询慢的SQL语句,可以通过查询数据库的慢查询日志或者对数据库的查询做监控等方式来获取慢SQL,只有知道了慢SQL才好去做下一步分析。
第二步通过查看SQL语句在数据库中的执行计划来分析SQL语句查询慢的具体原因,一般来说,不管是什么类型的数据库,都可以查看到其执行SQL语句时的执行计划。
第三步是根据分析到的原因来对SQL语句做调优,常用的调优方式就是如果没有索引,那就增加索引,如果是有索引,但是没有命中索引,那就调整SQL语句的写法让其正确的命中相关索引。
- (二)、数据库优化:当数据量确实达到了超高的数据量级,通过SQL优化不能解决问题时,就需要通过数据库优化来解决性能问题。数据库优化的常用方式包括使用缓存、读写分离、分库分表等,如下所示。
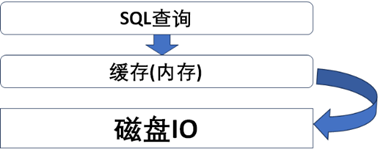
A、使用缓存:指的是数据库查询的缓存,将一些常用的热数据提前加载到缓存中,通常情况下是尽可能给数据库分配比较大的内存,让数据查询时,将数据加载到缓存中,那么下次查询时,就不需要 从物理存储中拉取数据了,如下图所示。
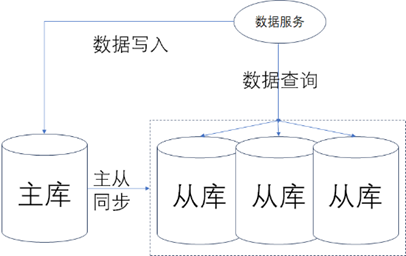
B、读写分离:读写分离是一种从数据库角度来进行的架构优化,当数据服务是“读多写少”时,数据库因为数据量太大,不能扛住高并发的查询时,可以采用读写分离的方式,让更多的数据查询从从库的只读节点来查询,如下图所示。
C、分库分表:分库分表是针对单表数据量过大时的一种常用解决方案,当数据量达到单表的瓶颈时,采用分表的方式来让数据重新分布。当数据量达到单库的瓶颈时,采用分库的方式来让数据重新分布,如下图所示。
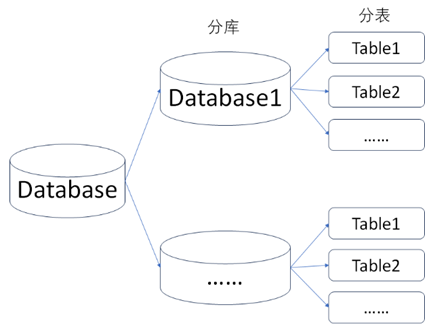
分库分表的常用方式如下:
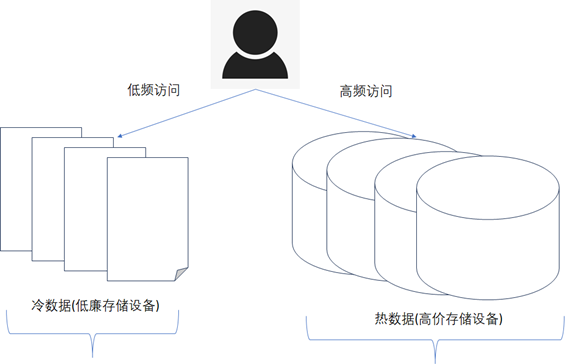
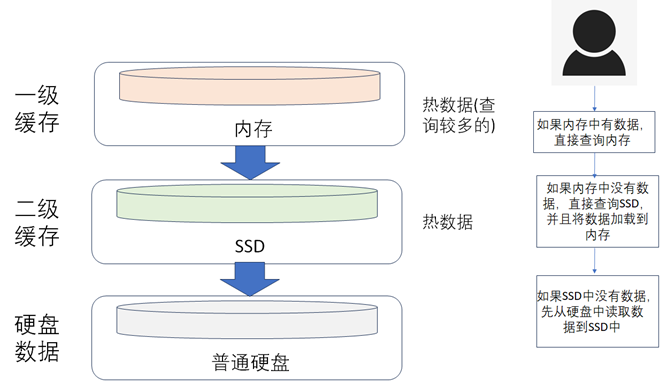
1)、按照冷热数据分离的方式:通常将使用频率非常高的数据称之为热数据,查询频率较低或者几乎不被查询的数据称之为冷数据,冷热数据分离后,热数据单独存储,这样热数据的数据量量就下降下来了,查询的性能自然也就提升了,如下图所示。
除了按照图所示的方式来做冷热数据分离外,随着硬件技术的发展,比如像内存价格的下降以及SSD固态硬盘的出现, 还可以按照如下图所示的方式来自动做冷热数据加载和分离,可以根据一定的规则来判断什么时候需要将普通硬盘中的数据预加载到SSD或者内存中,来加快数据查询的性能,由于SSD和内存中不能存储大量的数据,所以还需要设置一定的规则,将SSD和内存中不查询的数据定期清除来释放缓存的空间。
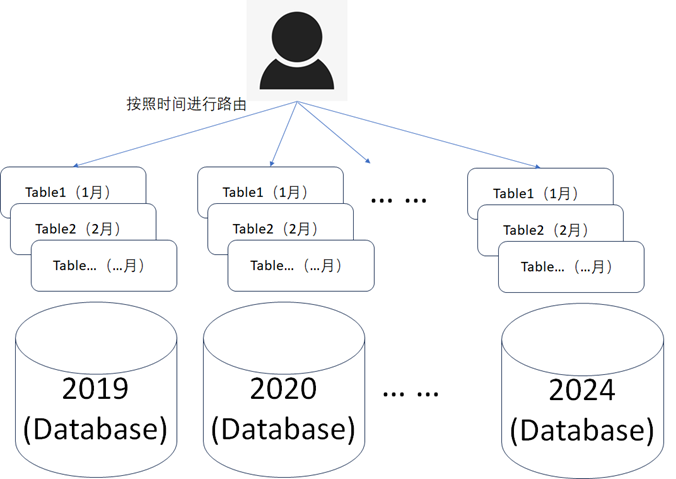
2)、按照时间维度的方式:可以按照实时数据和历史数据分库分表,也可以按照年份、月份等时间区间来进行分库分表,如下图所示,目的是尽可能的减少单个库表中的数据量。《数据资产管理核心技术与应用》是清华大学出版社出版的一本图书,作者为张永清等著
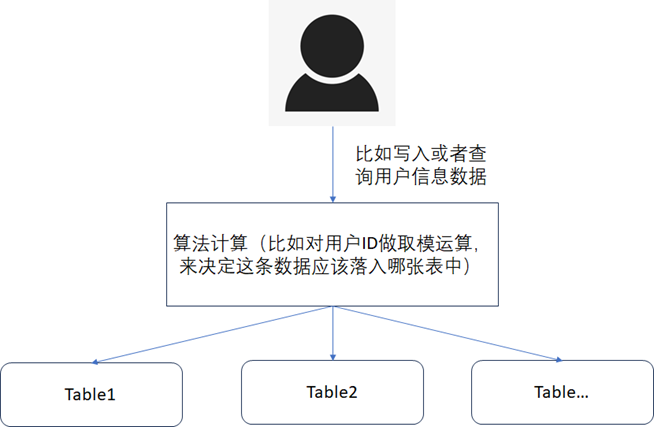
3)、按照一定的算法计算的方式:当数据都是热数据的情况下,比如数据确实无法做冷热分离,所有的数据都经常会被查询,并且数据量又非常的大。此时就可以根据数据中的某个字段做算法计算(需要特别注意这个字段一般是数据查询时的检索条件字段),使得数据能均匀的落到不同的分表中去,查询时再根据查询条件中的该字段做算法计算就可以快速的定位到是需要到哪个表中去进行查询,如下图。
4)、按照时间维度的方式:可以按照实时数据和历史数据分库分表,也可以按照年份、月份等时间区间来进行分库分表,如下图所示,目的是尽可能的减少单个库表中的数据量。
5)、按照一定的算法计算的方式:当数据都是热数据的情况下,比如数据确实无法做冷热分离,所有的数据都经常会被查询,并且数据量又非常的大。此时就可以根据数据中的某个字段做算法计算(需要特别注意这个字段一般是数据查询时的检索条件字段),使得数据能均匀的落到不同的分表中去,查询时再根据查询条件中的该字段做算法计算就可以快速的定位到是需要到哪个表中去进行查询,如下图所示。
- (三)、架构设计优化:当SQL优化和数据库优化不能解决性能问题时,就需要考虑从架构设计上来进行优化,常见的架构设计优化手段如下:
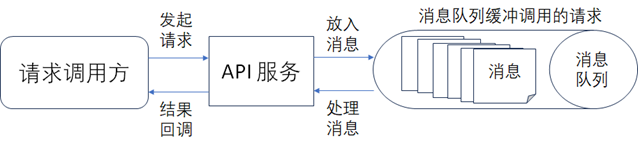
1)、通过消息队列削峰填谷:在调用量的峰值非常大时,通过消息队列缓冲调用的请求,然后让请求异步的处理完后,再同步给请求的调用方,如下图所示。《数据资产管理核心技术与应用》是清华大学出版社出版的一本图书,作者为张永清等著
2)、通过使用分布式数据库来进行处理,分布式数据库是数据库中一种MPP(Massively Parallel Processing的简写)的架构实现,常见的分布式数据库包括Doris(可以通过官网Apache Doris: Open source data warehouse for real time data analytics - Apache Doris了解更多关于Doris的介绍)、Greenplum(可以通过官网https://greenplum.org/了解更多关于Greenplum的介绍)等。
3)、部署架构的优化,比如可以通过Kubernetes的方式来部署,因为Kubernetes可以支持动态的扩缩容, 在保障了数据服务的性能的同时,还可以通过弹性的伸缩来控制成本。
- (四)、硬件优化:硬件优化的常用手段就是对硬件资源进行扩容或者提高硬件资源的性能,常见的手段如下:
- (1)、使用I/O读写更快的硬件,比如使用SSD硬盘来替代普通的机械硬盘。
- (2)、通过增加服务器的数量或者增加服务器的配置来对服务器进行横向或者纵向的扩容。
- (3)、增加网络的带宽或者使用带宽更大网络设备来提高网络通道的传输速度。
未完待续......《数据资产管理核心技术与应用》是清华大学出版社出版的一本图书,作者为张永清等著
这篇关于《数据资产管理核心技术与应用》读书笔记-第五章:数据服务(二)的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






