本文主要是介绍数据结构:二叉树详解 c++信息学奥赛基础知识讲解,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!

目录
一、二叉树的定义
二、二叉树的形态
三、二叉树的性质
四、二叉树的存储
五、二叉树的创建与遍历(递归)
六、二叉树实现
创建二叉树
展示二叉树
1、计算数的高度
2、计算数的叶子数量
3、计算数的宽度
4、层次遍历
5、前序遍历
递归写法
非递归写法
6、中序遍历
递归写法
非递归写法
7、后序遍历
递归写法
非递归写法
8、输出根节点到所有叶子节点的路径(递归)
递归写法
非递归写法
一、二叉树的定义
二叉树(Binary Tree) 是由n个结点构成的有限集(n≥0),n=0时为空树,n>0时为非空树。对于非空树T TT:
- 有且仅有一个根结点;
- 除根结点外的其余结点又可分为两个不相交的子集TL 和TR,分别称为T的左子树和右子树,且TL和TR 本身又都是二叉树。
很明显该定义属于递归定义,所以有关二叉树的操作使用递归往往更容易理解和实现。
从定义也可以看出二叉树与一般树的区别主要是两点,一是每个结点的度最多为2;二是结点的子树有左右之分,不能随意调换,调换后又是一棵新的二叉树。
二、二叉树的形态
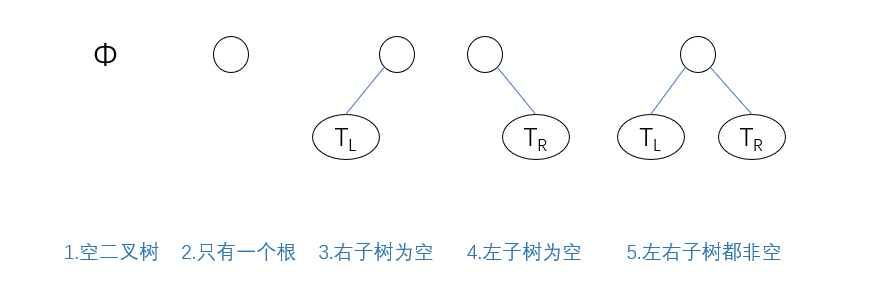
五种基本形态
从上面二叉树的递归定义可以看出,二叉树或为空,或为一个根结点加上两棵左右子树,因为两棵左右子树也是二叉树也可以为空,所以二叉树有5种基本形态:
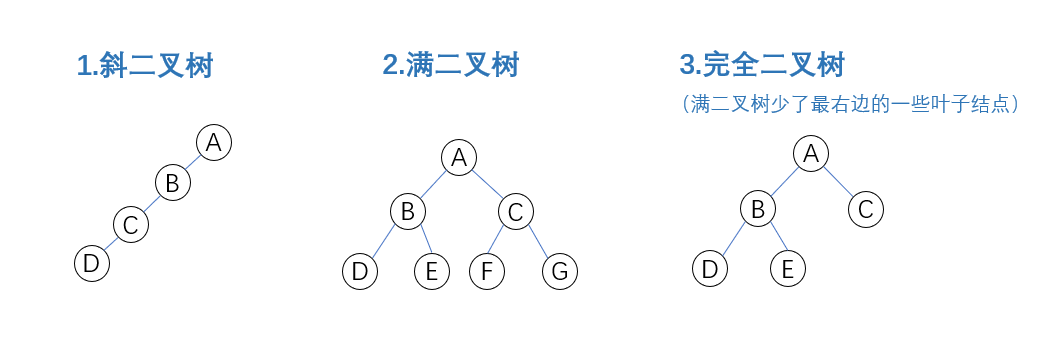
三种特殊形态
三、二叉树的性质
- 任意二叉树第 i 层最大结点数为
。 ( i ≥ 1 )
- 深度为 k 的二叉树最大结点总数为
。 ( k ≥ 1 )
- 对于任意二叉树,用n0 , n1 , n2分别表示叶子结点,度为1的结点,度为2的结点的个数,则有关系式n0 = n2 + 1
- n个结点完全二叉树深度为⌊
⌋ + 1
四、二叉树的存储
存储的目的是为了取,而取的关键在于如何通过父结点拿到它的左右子结点,不同存储方式围绕的核心也就是这。
顺序存储
使用一组地址连续的存储单元存储,例如数组。为了在存储结构中能得到父子结点之间的映射关系,二叉树中的结点必须按层次遍历的顺序存放。具体是:
- 对于完全二叉树,只需要自根结点起从上往下、从左往右依次存储。
- 对于非完全二叉树,首先将它变换为完全二叉树,空缺位置用某个特殊字符代替(比如#),然后仍按完全二叉树的存储方式存储。
假设将一棵二叉树按此方式存储到数组后,左子结点下标=2倍的父结点下标+1,右子节点下标=2倍的父结点下标+2(这里父子结点间的关系是基于根结点从0开始计算的)。若数组某个位置处值为#,代表此处对应的结点为空。
可以看出顺序存储非常适合存储接近完全二叉树类型的二叉树,对于一般二叉树有很大的空间浪费,所以对于一般二叉树,一般用下面这种链式存储。
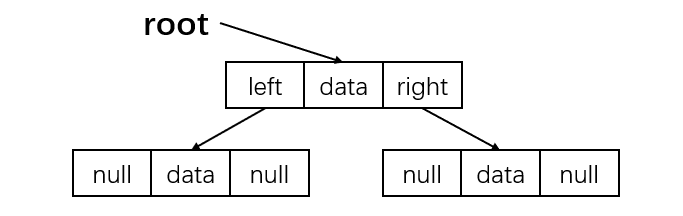
链式存储
对每个结点,除数据域外再多增加左右两个指针域,分别指向该结点的左孩子和右孩子结点,再用一个头指针指向根结点。对应的存储结构:
五、二叉树的创建与遍历(递归)
二叉树由三个基本单元组成:根结点,左子树,右子树,因此存在6种遍历顺序,若规定先左后右,则只有以下3种:
1.先序遍历
若二叉树为空,则空操作;否则:
(1)访问根结点
(2)先序遍历左子树
(3)先序遍历右子树
2.中序遍历
若二叉树为空,则空操作;否则:
(1)中序遍历左子树
(2)访问根结点
(3)中序遍历右子树
3.后序遍历
若二叉树为空,则空操作;否则:
(1)后序遍历左子树
(2)后序遍历右子树
(3)访问根结点
从上可以看出先中后其实是相对根结点来说。
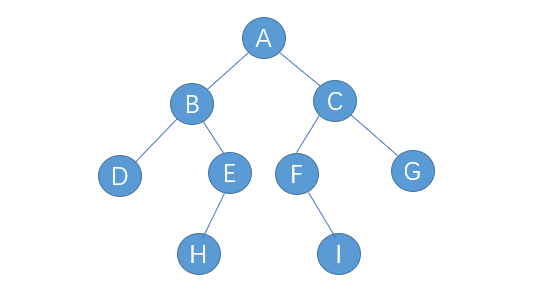
对于下面这棵二叉树,其遍历顺序:
先序:ABDEHCFIG
中序:DBHEAFICG
后序:DHEBIFGCA
下面是将以下二叉树的顺序存储[A,B,C,D,E,F,G,#,#,H,#,#,I]转换为链式存储的代码,结点不存在用字符#表示,并分别遍历。
六、二叉树实现
我们的二叉树的是以链式结构建立的,下面通过c++实现二叉树的相关操作。链式结构的每个节点都用BT结构体表示,这个结构体的data代表树的该节点存储的数据(此处为了方便使用char作为存储数据,实际使用时,可以使用各种各样的数据类型代表这个data,甚至在BT下挂载多个数据也是没问题的)。*left和*right分别代表指向该节点的左节点和右节点的指针。
#include <iostream>
#include <cstring>
#define N 100
using namespace std;typedef struct node
{char data;struct node *left, *right;
}BT;BT *createbt(char *in, char *pre, int k); // 根据输入二点中序表达式和前序表达式创建一颗二叉树
void showBt(BT *T); // 展示一颗二叉树,以A(B, C(D, E))这样加了括号的前序遍历来实现
int height(BT *T); // 计算树的高度
int leaf(BT *T); // 计算叶子的数量
int width(BT *T); // 计算树的宽度
void layer(BT *T); // 层次遍历
void preorder(BT *T); // 前序遍历
void inorder(BT *T); // 中序遍历
void postorder(BT *T); // 后序遍历
void getPath(BT *T, BT **path, int top) // 输出根节点到所有叶子节点的路径(递归)
void getPath(BT *T); // 输出根节点到所有叶子节点的路径(非递归)创建二叉树
为了方便,此处使用前序遍历和中序遍历的表达式递归地创建一颗二叉树。
BT *createbt(char *in, char *pre, int k)
{if (k <= 0)return NULL;else{BT *node = new BT;node->data = pre[0]; // 前序表达地第一个元素就是这颗子树地根节点int i;for (i = 0; in[i] != pre[0]; ++ i); // 根据一个计数器i获取中序表达式中node->data的位置node->left = createbt(in, pre + 1, i);node->right = createbt(in + i + 1, pre + i + 1, k - i - 1);return node;}
}展示二叉树
展示一棵二叉树。它的顺序和前序遍历是一样的,只是我们给他们加上括号
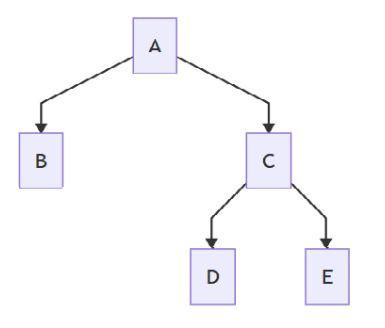
很显然,它的前序表达式为ABCDE,那么我们的展示函数就在前序表达式的基础上加上括号来代表其层次关系:A(B,C(D,E))。
void showBt(BT *T)
{if (T){cout << T->data << " ";if (T->left || T->right) // 判断一下当前递归到的节点有没有字节点,如果没有子节点,我们就不需要打上括号了{cout << "(";showBt(T->left);cout << ",";showBt(T->right);cout << ")";}}
}1、计算数的高度
树的高度可以认为是层数,也就是根节点到叶子节点中路径最长的那条路径包含的节点数量。此后通过递归实现:
int height(BT *T)
{if (!T)return 0;elsereturn max(height(T->left) + 1, height(T->right) + 1);
}2、计算数的叶子数量
思路和计算树的高度差不多,不过需要额外判断一下叶子节点的情况:
int leaf(BT *T)
{if (!T) return 0;else if (!T->left && !T->right) // 当前节点为叶子,那么叶子的数量当然是1return 1;elsereturn leaf(T->left) + leaf(T->right);
}3、计算数的宽度
树的宽度定义为含有节点为最多节点的那一层所含有的节点数,比如下面这幅图:

上面这幅图中DEFG这层有的节点数量最多,为4个,因此这颗二叉树的宽度为4。
很明显,我们是通过比较层的节点数量来确定宽度,因此我们需要通过层次遍历来获取宽度。不过不同于一般的层次遍历的写法,我们需要统计完一层的节点树,然后直接把这一层的节点全部弹出,然后把它们的子节点入队。
我们记答案为max_wid,每层的节点数为count,很明显count = rear - front,那么我们通过count这个值做count次出队,入队操作就可以把第n层的节点全部弹出,把n+1层的节点全部入队
int width(BT *T)
{BT *q[N], *p;int front, rear;front = rear = 0;q[rear ++] = T;int max_wid = 0;while (front != rear){int count = rear - front; // 通过队列的front和rear直接得出当前层的节点数量max_wid = max(max_wid, count); // 更新当前的最大宽度while (count --) // 根据count将当前层的所有节点弹出,把它们的子节点入队,完成层次遍历的队列更新{p = q[front ++];if (p->left)q[rear ++] = p->left;if (p->right)q[rear ++] = p->right;}}return max_wid;
}4、层次遍历
层次遍历通过队列是实现,每出队一个元素,就将它的左子节点和右子节点入队(如果有的话)。
void layer(BT *T)
{BT *q[N], *p;int front, rear;front = rear = 0;q[rear ++] = T;while (front != rear){p = q[front ++]; // 队首元素出队cout << p->data << " ";// 将出队的元素的子节点入队if (p->left)q[rear ++] = p->left;if (p->right)q[rear ++] = p->right;}
}5、前序遍历
递归写法
前序的递归写法非常直观:
void preorder(BT *T) // 前序遍历
{if (T){cout << T->data << " ";preorder(T->left);preorder(T->right);}
}非递归写法
前序遍历的非递归通过栈来实现,要先输出的元素后入栈,要后输出的元素先入栈:
void preorder(BT *T)
{BT *s[N], *p;int top = 0;s[top] = T;while (top >= 0){// 首元素的栈筛比较简单,就是直接输出就完事儿p = s[top --];cout << p->data << " ";// 后续要递归的栈筛入栈if (p->right)s[++ top] = p->right;if (p->left)s[++ top] = p->left;}
}6、中序遍历
递归写法
void inorder(BT *T) // 中序遍历
{if (T){preorder(T->left);cout << T->data << " ";preorder(T->right);}
}非递归写法
中序遍历的非递归还是通过栈来实现的,只不过与前序遍历相比,我们的根节点不能直接输出,所以我们需要额外的栈筛来保存中间输出的各个子树的根节点,这个节点为p:
void inorder(BT *T)
{BT *s[N], *p = T;int top = -1;while (top >=0 || p){while (p) // 由于中序遍历需要将所有的左子树输出,所以首先将左子树的栈筛入栈{s[++ top] = p;p = p->left;}p = s[top --];cout << p->data << " ";p = p->right; // 如果该节点有右节点,则根据中序遍历的规则进入右子树(该节点被当作局部子树的根节点);如果没有右节点,根据代码结构,打印上一层的节点(该节点被当作局部子树的左节点)}
}7、后序遍历
递归写法
void postorder(BT *T) // 后序遍历
{if (T){preorder(T->left);preorder(T->right);cout << T->data << " ";}
}非递归写法
后续遍历的非递归写法也是通过栈来实现的,因为此时的各个子树的根节点是在最后才输出的,所以我们需要保存左子树的栈筛和右子树的栈筛。我们还需要一个临时变量来指明当前遍历到的节点的右子节点是否被访问过。
void postorder(BT *T)
{BT *s[N], *p = T, *last; // last变量用来判断当前访问的节点的右子节点是否被访问过int top = -1;do{while (p) // 左子树的栈筛全部{s[++ top] = p;p = p->left;}last = NULL;while (top >= 0) // 遍历打印没有右节点的根节点,或者访问没有访问过的右子树{p = s[top];if (p->right == last){top --;cout << p->data << " ";last = p;}else{p = p->right;break;}} }while (top >= 0);
}8、输出根节点到所有叶子节点的路径(递归)
递归写法没什么好说的=_=,还是很简单的。注意在主函数中调用该函数时,需要额外传入一个存储参数的path数组,起始填入的top为-1。
递归写法
void getPath(BT *T, BT **path, int top)
{ if (!T)return;else if (!T->left && !T->right){for (int i = 0; i <= top; ++ i)cout << path[i]->data << " ";cout << T->data << endl;}else{path[++ top] = T;getPath(T->left, path, top);getPath(T->right, path, top);}
} 非递归写法
此处一定记住,只要是涉及到输出路径输出,一定是优先考虑后序遍历,因为后序遍历是左子树->右子树->根节点的顺序,这就使得使用后序遍历访问到一个元素时,栈中剩余元素恰为根节点到该元素的路径,所以我们只要将后序遍历中的cout改成一个判断:若当前元素是叶子,则将栈中元素依次输出。
void getPath(BT *T)
{BT *s[N], *p = T, *last;int top = -1;do{while (p){s[++ top] = p;p = p->left;}last = NULL;while (top >= 0){p = s[top];if (p->right == last){top --;if (!p->left && !p->right) // 判断当前访问的节点是否为叶子节点,若是,则输出栈内元素{for (int i = 0; i <= top; ++ i)cout << s[i]->data << " ";cout << p->data << endl;}last = p;}else{p = p->right;break;}}}while(top >= 0);
}这篇关于数据结构:二叉树详解 c++信息学奥赛基础知识讲解的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!



