本文主要是介绍游戏高度可配置化(一)通用数据引擎(data-e)及其在模块化游戏开发中的应用构想图解,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
游戏高度可配置化(一)通用数据引擎(data-e)及其在模块化游戏开发中的应用构想图解
码客 卢益贵 ygluu
关键词:游戏策划 可配置化 模块化配置 数据引擎 条件系统 红点系统
一、前言
在插件式模块化软件开发当中,既要模块高度独立(解耦)又要共享模块数据,最好的方法是有个中间平台(中间件)提供标准的接口来进行数据的交换,这在很多行业软件开发中已经广泛应用。但是,由于中间件的抽象和封装没有具备通用性的前提,使得在实际应用中受到了很大的制约。
本文将以“数据引擎”的概念来阐述通用数据中间件的理论和构成,以及以“通用数据引擎在游戏开发中的应用构想”来作为其的应用范例。
本文主要针对服务端开发,但客户端也可以参考。
二、模块化与插件
有关模块化软件开发的详细介绍这里不再做赘述(网上有很多参考资源[1])。
1、常规模块化
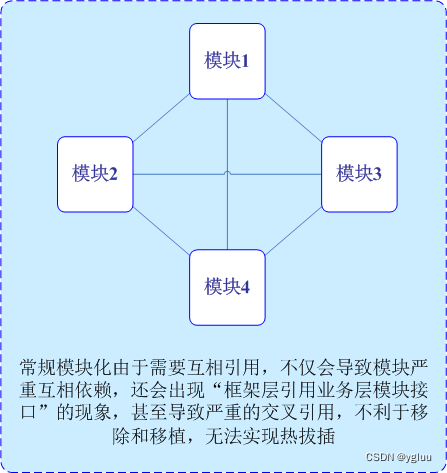
图1
2、插件式模块化(插件开发)

图2
三、通用数据引擎理论与构成
数据引擎是业界常用方法的集合(包含名字系统、数据仓库、条件系统、公式系统、运算集合、流程步骤控制系统、监听系统(数据变化监听和条件监听)、自定义函数系统、Go数学函数库、数据工作站),是为系统数据和模块数据提供统一交互接口的中间件(参考 data-e 源码[2])。

图3 数据引擎结构及数据交互模式
1、名字系统(数据类型)
名字系统是数据引擎的基础核心,它将系统所有数据进行命名和ID编号。

图4 数据名称配置表(可根据分类进行分表配置)

图5 数据ID编码方式
2、数据仓库(数据持久化)
数据仓库为数据提供了标准的Get/Set/Save/Load接口。

图6 数据统一持久化
3、监听器(事件与订阅-通知模型,观察者模式)
监听器是采用订阅-通知模型[3]而做的,是模块监听数据变化和做出及时响应处理的管理单元。

图7
4、生产-消费模型
事实上所有活动都是消费-生产的过程。在信息化系统里面,消费不一定是消耗。比如我们0元购买合法的商业信息,但这个信息并没有改变,我们仅是获得信息副本,但对提供信息的商家来说你的行为就是对这个信息的消费行为。也就是说GetValue和Value=Value-1都是消费行为。
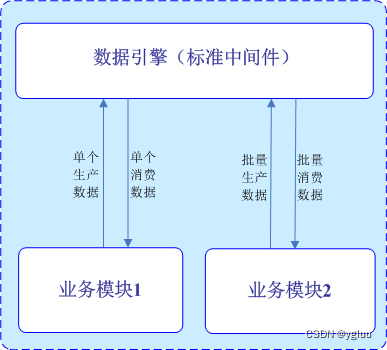
图8 生产消费模型
再对消费-生产[4]进行一个概念的升级就是:依据什么条件(消费数据)做什么事情(生产数据),即On-Do,就此引入条件系统[5]。

图9 消费-生产配置表

图10 消费-生产模型实现代码
由图9和图10可见,模型化的生产-消费方式实现了高度可配置化——代码层并不知道具体执行什么。
5、公式系统[6]、条件系统[5]、运算集合、流程控制系统
数据引擎将四则运算表达式统称为公式。公式表达、条件表达、运算集合表达式关系如图11:

图11 公式、条件、运算集合表达式关系
流程控制表达式包含了运算集合和控制指令(计算控制和行为控制),如果图12:

图12 流程控制表达式
6、数据工作站
数据工作站是每个模块操作数据的个体实例,当生产数据时该模块的工作站会记录相关数据ID,便于条件符合时对该模块所生产的数据进行清理操作,并同时提供对数据的监听操作。
四、通用数据引擎在游戏开发中的构想
通用数据引擎在模块化开发中的应用场景很广,以下以游戏开发的应用构想为例。
1、游戏的高度信息化(系统数据、玩家数据和行为信息的大统一)
游戏中各种数据都是已经数字化的,但数字化不一定就能信息化,信息化离不开交互环节。当我们把游戏数据都纳入到数据引擎的管辖范围以后,才能够实现信息的无障碍交互。
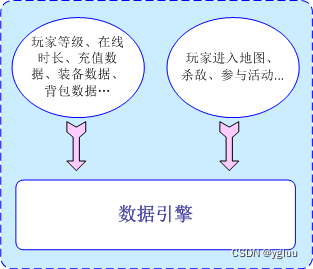
图13 游戏数据的高度信息化
2、游戏服务端与客户端数据同步(红点系统)
依托标准数据同步接口和客户端数据引擎,服务端可以有超过50%以上的数据无需再编程实现和客户端的交换,客户端也可以依赖条件系统在红点处理方面减少开发工作量,能够进一步提升开发效率。

图14 游戏服务端与客户端数据同步
3、基础数据与衍生数据
每个一款游戏都有固定的基础数据和信息(比如属性等数据、进入离开地图和杀敌等事件)。无论是游戏业务模块还是游戏框架模块,玩家行为产生的仅是基础数据,由基础数据衍生的数据放在配置层来实现:

图15 游戏基础数据与衍生数据
如果图15所示,在配置层配置条件表达式“当次充值>0”和数据表达式“总充值+当次充值;日充值+当次充值;周充值+当次充值”,并加载到数据引擎的监听器中,当条件满足时即可衍生出“总充值、日充值、周充值”等衍生数据。以此类推,依托框架模块和业务模块的基础数据可以在配置层衍生出任意所需的数据。
4、数据维度空间模型与游戏的高度可配置化
以往,我们习惯于在玩家的各个行为事件环节用代码实现游戏数据的加工和逻辑控制。假如我们以一种模型的角度来现实,它产生效果是意想不到的。在此引用本人在数学建模的案例插图说明一下维度空间模型(见《可配置化数学建模的应用案例图解》[7]):

图16 数据维度空间模型
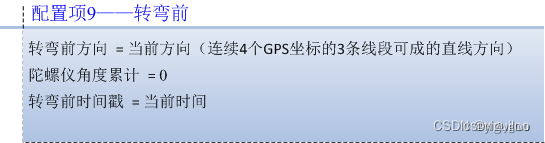
图17 数据维度空间模型的配置项样例
由图16和图17可见,在模型方式下,在代码层不再执行具体的数据运算和流程控制,而放在了配置层,依托数据引擎对配置表达式的解析和执行,我们游戏的可配置化程度再提升到了一个新的高度,并且也减少了大量的编码工作。
关于游戏的完整数据维度空间模型在此不多做举例,仅以玩家登录后在地图杀敌为例:

图18 数据维度空间模型及高度可配置化
由图18可见,依据代码层提供的基础数据,在配置层衍生了玩家杀敌需要的时长(可统计敌我实际战力平衡指数)、每日杀敌数量、总杀敌数量、赛季杀敌数量等,这些数据可应用于福利模块、任务模块等以满足一连串的策划需求。
5、成长线、活动、任务等策划需求的抽象和配置实现
这是本文重点的重点。
通过对成长线、活动、任务等策划需求的分析,结合相关数据特性,可以抽象出两类数据管理对象:递进式和并列式数据管理对象,根据对数据的响应方式可以抽象出观察者模式、探测者模式。
递进式数据管理对象可以用于成长线(皮肤晋级、技能升级等)、七日福利、任务等等,而成长线、七日福利属于探测者模式(玩家请求后从数据引擎探测条件是否满足再执行),任务模块则是属于观察者模式(把条件提交给数据引擎的监听器,条件满足后自动执行相应的任务配置表达式)。
并列式数据管理对象可用于宝石系统等,各类颜色的宝石激活后即可叠加给属性加成,而每个颜色的宝石又是一个递进式的数据(宝石有升级需求),所以并列式的数据管理对象包含了递进式的数据管理对象。
上述抽象描述有点难理解,以图例说明(前述抽象的封装对象可以轻松完成以下例子的配置):

图19 成长线、活动、任务等策划需求的抽象和配置实现
从图19的需求范例可以看出,我们只需抽象出两类数据管理对象即可实现多数的策划需求,因为多数的策划需求不外乎消费什么数据来生产什么数据,所以无论可配置化率还是开发效率都是极度的提升。
6、抽象的八二法则与高效开发
俗话说没有100%绝对的事情。如果抽象能解决80%(多数)问题那么就是正确的(剩下20%(少数)问题再具体问题解决解决),如果优化能减少80%(多数)繁琐细节那么他也是正确的。

图20 八二法则(图片来源于网络)
7、游戏模块(插件)的冷热拔插
系统初始化有代码单元初始化、线程初始化、模块依赖初始化,只要遵循一定框架规范,任意一个游戏模块都可以在运营时关闭和启动,当关闭时其他模块对它的数据取值返回为0而已,只是相关功能不能操作,不影响系统正常运营。
8、留给给策划更广阔的想象空间
高度可配置化可以留给策划更广阔的想象空间,可以轻松设定和实现数值模型,并且能深度发掘需求潜力。

图21 想象空间(图片来源于网络)
9、程序员的思维转换和工作转移
相对于传统方式,生产-消费模型需要程序员转变思维方式。成熟的插件开发框架能让程序开发更加容易和轻松,所以程序员的工作方向转移到配合策划进行配置表配置。
五、通用数据引擎的应用问题与前景展望
1、应用问题1:中间商赚差价
但凡有中间商都会被赚取差价。所以中间件对性能是有损耗的,但以当下的CPU算力,多数系统是绝对能接受的(其实实际开发中有很多不良的编码方式导致很大的性能消耗),也就是说在性能可接受的前提下开发效率为王。
2、应用问题2:细节与方法论
确定了插件式的软件开发方向,往往很多细节问题会让人无所适从,解决问题无外乎方法论,而方法源于经历和阅历。
3、前景展望1:公司内部插件式软件开发框架
在优秀的抽象和逻辑能力下,随着时间迭代,基于数据引擎的软件系统就会形成一个成熟的软件框架,插件式开发可为企业提高可观的开发效率。
4、前景展望2:云插件及云IDE服务商(插件式模块化游戏云开发平台)
更乐观一些的,依托于docker、k8s、grafana和成熟软件框架及编辑器(如捕鱼游戏框架、棋牌游戏框架、MMO游戏框架等)可组成一个云插件游戏开发平台,其他公司或工作室只需开发具体游戏业务的插件,平台托管插件代码和负责运营并按比例抽成。
六、相关知识与链接
[1] 模块化参考链接:插件式模块化软件框架的思想图解(一、二、三)
https://blog.csdn.net/guestcode/article/details/119701789?spm=1001.2014.3001.5501
https://blog.csdn.net/guestcode/article/details/119981524?spm=1001.2014.3001.5501
https://blog.csdn.net/guestcode/article/details/124780626?spm=1001.2014.3001.5501
[2] 数据引擎(data-e))源码:
https://github.com/ygluu/data-e
[3] 订阅-通知模型(观察者模式)介绍
https://baike.baidu.com/item/%E8%A7%82%E5%AF%9F%E8%80%85%E6%A8%A1%E5%BC%8F/5881786?fr=aladdin
[4] 生产-消费模型 (线程队列模式)参考链接
https://wenku.baidu.com/view/38b499c85df7ba0d4a7302768e9951e79b89691f.html?_wkts_=1677317893084&bdQuery=%E7%94%9F%E4%BA%A7%E6%B6%88%E8%B4%B9%E6%A8%A1%E5%9E%8B
https://blog.csdn.net/weixin_34409703/article/details/92112762
[5] 条件系统参考链接
https://baike.baidu.com/item/%E6%9D%A1%E4%BB%B6%2F%E4%BA%8B%E4%BB%B6%E7%B3%BB%E7%BB%9F/53173668?fr=aladdin
https://blog.csdn.net/weixin_34409703/article/details/92112762
[6] 公式系统参考链接
https://studygolang.com/articles/24125?fr=sidebar
[7] 可配置化数学建模的应用案例图解
https://blog.csdn.net/guestcode/article/details/127469191?spm=1001.2014.3001.5501
这篇关于游戏高度可配置化(一)通用数据引擎(data-e)及其在模块化游戏开发中的应用构想图解的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!




