本文主要是介绍关于飞浆文字识别技术的运用,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
飞桨PaddlePaddle-源于产业实践的开源深度学习平台,有关文章可以在此进行查询
飞桨(PaddlePaddle)是一个由百度开源的深度学习平台,它提供了丰富的机器学习算法库,支持多种深度学习模型的构建、训练和部署。飞桨平台具有以下特点:
-
易用性:飞桨提供了简洁的API设计和丰富的文档,使得初学者和研究人员可以快速上手。
-
高性能:飞桨针对多种硬件进行了优化,包括CPU、GPU和百度自研的AI加速芯片XPU,能够提供高效的训练和推理速度。
-
灵活性:支持静态图和动态图两种编程模式,用户可以根据需要选择使用。
-
多平台支持:飞桨支持在多种操作系统上运行,包括Linux、Windows和Mac OS。
-
大规模分布式训练:飞桨提供了大规模分布式训练的能力,支持多机多卡训练,适合处理大规模数据集。
-
工业级应用:飞桨在百度内部得到了广泛应用,支持了百度的许多核心业务,如搜索、语音识别、图像识别等。
-
模型库:提供了大量的预训练模型和模型库,用户可以根据自己的需求选择合适的模型进行迁移学习或微调。
-
工具和组件:飞桨提供了包括数据增强、模型压缩、模型可视化等多种工具和组件,帮助用户优化模型性能和部署。
-
社区支持:飞桨拥有活跃的开源社区,用户可以在社区中获取帮助、分享经验和参与讨论。
-
端到端部署:飞桨支持模型从训练到部署的全流程,提供了模型导出、转换和在不同设备上运行的能力。
-
教育和研究:飞桨平台也广泛应用于教育和研究领域,提供了丰富的教程和案例,帮助学生和研究人员学习深度学习
本次使用的知识飞浆的一小部分内容,想要获取更多关于飞浆的知识,可以在官网上进行查看。
准备工作:
前景介绍:我们在爬取某些网站的时候,爬取下来的文字有时会不显示,或显示不完全。观察字体也不难发现,字体和字体之间会有不同。网站主要运用了自己制作的字体文件font文件,其中的每一串不同的数字对应一个字,这是一种映射的关系。只要将一串数字和字体对应,就可以完成破解,但人工对应比较麻烦,利用文字识别技术,将获取的文字图片与文件名上的一串数字对应就能很方便的破解。
前景过程:以某茄小说网为例

不难发现,小说的文章字体不一致,有的粗有的细
在进行网页制作的时候,我们可以设置多个字体,并且可以自定义字体只需有字体文件(以woff开头),在第一个字体中没用该字体会使用第二个字体,都没默认使用微软雅黑
<!DOCTYPE html>
<html lang="en">
<head><meta charset="UTF-8"><meta name="viewport" content="width=device-width, initial-scale=1.0"><title>Document</title><style>// 自定义字体@font-face {font-family: nihao;src: url(./字体/e26e946d8b2ccb7.woff2);}// 所使用的字体h1 {font-family: fangsong, nihao;}</style>
</head>
<body><h1>你好世界</h1><h1>终焉</h1>
</body>
</html>在检查中也会发现,元素中有些字体看不到,观察样式会发现在第一个字体文件是自定义的字体文件。

在网络检查-字体中将字体文件下载(通过链接就可以下载)
具体流程:
1,发现该文字是自定义字体
2,了解font-face在哪里使用
3, 通过来源面板调试,找到自定义字体
ord()和chr()
ord() :放回unicode编码chr() :返回unicode编码的值将获取到的未解密的字体数据进行遍历,获取每一个字体的unicode 编码
问题就定位到了每一个unicode对应字符
将获取的自定义字体通过字体在线工具进行查看在线字体查看器 - bejson在线工具
当选中一个文字的时候就会发现文字对应的unicode编码(十六进制)
观察发现文字的名称中的数字部分就是文字的unicode编码(十进制)
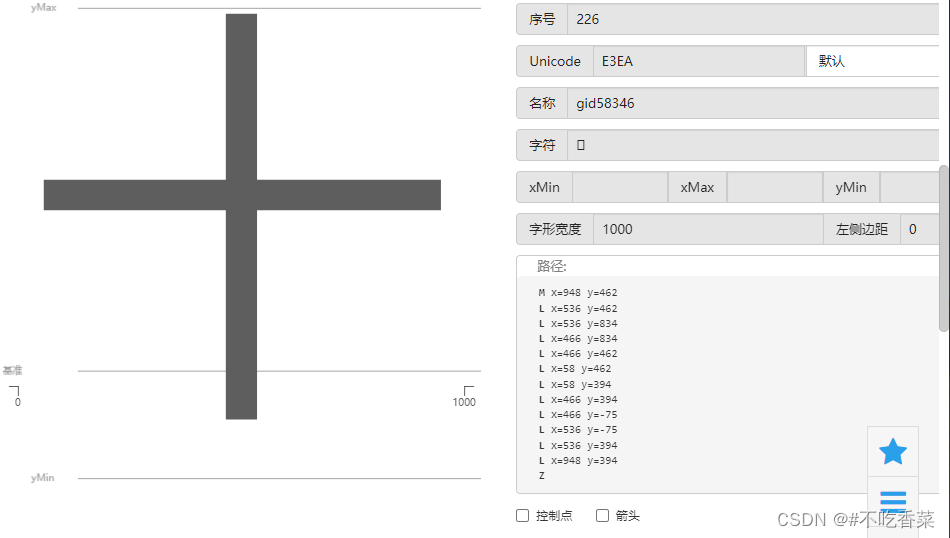 所以要建立字典映射来完成字符与unicode一一对应的字典表,故使用飞浆文字识别提高效率
所以要建立字典映射来完成字符与unicode一一对应的字典表,故使用飞浆文字识别提高效率
通过js手段将字体文件保存下来
// 编写好以后复制到控制台中
let targets = document.querySelectorAll("[id^=g]")
let nameEle = document.querySelector("#input-name")
targets.forEach(function(item, index){if(index >= 2 && index <= 6){setTimeout(function(){item.click();let url = item.toDataURL("image/png");let a = document.createElement("a");a.href = url;a.download = `${nameEle.value.slice(3)}.png`a.click();}, 100*index)}
})

使用飞浆paddleOCR模型 GitHub - PaddlePaddle/PaddleOCR: Awesome multilingual OCR toolkits based on PaddlePaddle (practical ultra lightweight OCR system, support 80+ languages recognition, provide data annotation and synthesis tools, support training and deployment among server, mobile, embedded and IoT devices)
下载包 pip install paddlepaddle
pip install paddleocr
注意相关安装看官方说明,本文不再赘述
测试
在终端中输入
paddleocr.exe --image_dir filepath此时会下载模型
运行结束后会显示文字识别结果

由此可知该图片文字有92%的概率为“却”
单独使用识别:设置--det 为false
paddleocr.exe --image_dir filepath --det false结果为

在python中编写代码,相关代码可在官方文档中查看
from paddleocr import PaddleOCR, draw_ocr
import os
# Paddleocr目前支持的多语言语种可以通过修改lang参数进行切换
# 例如`ch`, `en`, `fr`, `german`, `korean`, `japan`
# 遍历文件ocr = PaddleOCR(use_angle_cls=True, lang="ch") # need to run only once to download and load model into memory
for file_name in os.listdir("../datas/解密图片"):img_path = f'../datas/解密图片/{file_name}'result = ocr.ocr(img_path, cls=True, det=False)for idx in range(len(result)):res = result[idx]for line in res:print(line[0])最后将识别的文件存入在字典中,完成对字体的破解。
这篇关于关于飞浆文字识别技术的运用的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






