本文主要是介绍大模型项目落地时,该如何估算模型所需GPU算力资源,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!

近期公司有大模型项目落地。在前期沟通时,对于算力估算和采购方案许多小伙伴不太了解,在此对相关的算力估算和选择进行一些总结。
不喜欢过程的可以直接 跳到HF上提供的模型计算器
要估算大模型的所需的显卡算力,首先要了解大模型的参数基础知识。
大模型的规模、参数的理解
模型参数单位
我们的项目中客户之前测试过Qwen1.5 -110B的模型,效果还比较满意。(Qwen还是国产模型中比较稳定的也是很多项目的首选)
模型中的110B 术语通常指的是大型神经网络模型的参数数量。其中的 “B” 代表 “billion”,也就是十亿。表示模型中的参数量,每个参数用来存储模型的权重和偏差等信息。110B也就是1100亿参数。(大模型的能力涌现基本都是参数要在千亿之上,几十亿几百亿的参数模型虽然也能满足大多数场景,但是谁不想要个更好的呢?『手动狗头』)
比如最新的Qwen2 开源了 5种模型规模,包括0.5B、1.5B、7B、57B-A14B和72B;(57B-A14B模型是570亿参数激活140亿的意思 )
模型参数精度
在深度学习领域内,构建高效率且精确度高的神经网络模型时,选择适当的参数精度至关重要。参数的精度通常指的是其存储和计算方式所采用的数据类型(data type),这直接关系到内存使用、计算性能以及最终模型的准确性。

单精度浮点数(float32):
单精度浮点数主要用于表示实数,具有较高的数值精确度,广泛应用于深度学习任务中。它的优点是能提供足够的精度来处理大部分的计算需求,而其32位的数据结构在内存中的占用空间仅为4字节。
半精度浮点数(float16):
相较于单精度浮点数,半精度浮点数具有较低的存储位数(16位),因此可以显著减少所需内存,并加速计算过程。这种数据类型尤其适合在图形处理器(GPU)上进行大量并行处理的应用场景。
BF16,全称为Brain Floating Point Format,是一种16位的半精度浮点数格式,特别为机器学习和人工智能领域的高性能计算优化而设计。BF16是在FP32(单精度浮点数)的基础上进行简化,旨在通过减少存储和计算需求来加速计算密集型任务,同时尽量减少对模型精度的损失。
具体来说,BF16浮点数格式由以下几个部分组成:
- 1位符号位,用来表示数值的正负。
- 8位指数位,相较于FP16的5位指数位,这提供了更宽的数值范围,有助于避免在处理较大或较小数值时的上溢或下溢问题。
- 7位尾数位(也称为小数部分或 mantissa),相比FP16的10位尾数位,这导致BF16在表示小数时的精度略低。
BF16的设计目标是在牺牲一定精度的前提下,提供足够的数值范围来支持深度学习模型的高效运行,尤其是在大规模分布式训练和高性能推理场景中。由于许多深度学习算法对数值的精确度要求不是极高,因此这种折衷在很多情况下是可以接受的,并且能够显著减少内存带宽需求和提高计算效率。
值得注意的是,BF16最初由Google提出,并在一些特定的硬件平台上获得了支持,比如某些CPU(特别是支持ARM NEON指令集的处理器)和NVIDIA的Ampere架构及后续版本的GPU,这些硬件直接支持BF16的加速运算,进一步促进了BF16在AI应用中的普及。
双精度浮点数(float64):
提供更高的数值精确度的是双精度浮点数,通常用于对数值精确度要求较高的任务中,如某些科学研究或金融分析等。虽然提供了额外的准确性保障,但这种数据类型占用内存较大,每单位存储需要8字节。
整数(int32, int64):
在深度学习中,对于处理离散值的情况,例如类别标签,通常会使用整型数据。有符号整数(如int32)能表示正负值,而无符号整数(如uint32)仅用于非负整数。这两种类型分别需要占用4字节和8字节的内存。
参数精度的选择是深度学习实践中的一门艺术,它要求平衡对精度的需求、系统资源限制以及计算效率之间的考量。通常情况下,在不影响模型性能的前提下,倾向于使用较低精度的数据类型以节省内存并提高计算速度。然而,当面对需要更高精度分析的任务时,可能需要权衡增加的内存消耗与提升的准确度。
理解各种参数精度的特点及其在深度学习中的应用是构建高效、优化资源利用和提高模型性能的关键因素之一。在实际应用中,选择适当的参数精度应当基于任务的具体需求、硬件能力以及预期的计算资源限制综合考虑。
大模型的文件体积
大模型除了参数大以外,体积也是相当的大。在了解了参数精度后,我们也就可以一句参数规模推算大模型的体积了。
以Qwen1.5-110B 来说:
全精度模型参数是float32类型, 占用4个字节,粗略计算:1b(10亿)个模型参数,约占用4G存储实际大小计算公式:10^9 * 4 / 1024^3 ~= 3.725 GB
那么Qwen1.5-110B的参数量为110B,那么加载模型参数需要的显存为:3.725 * 110 ~= 409.75GB
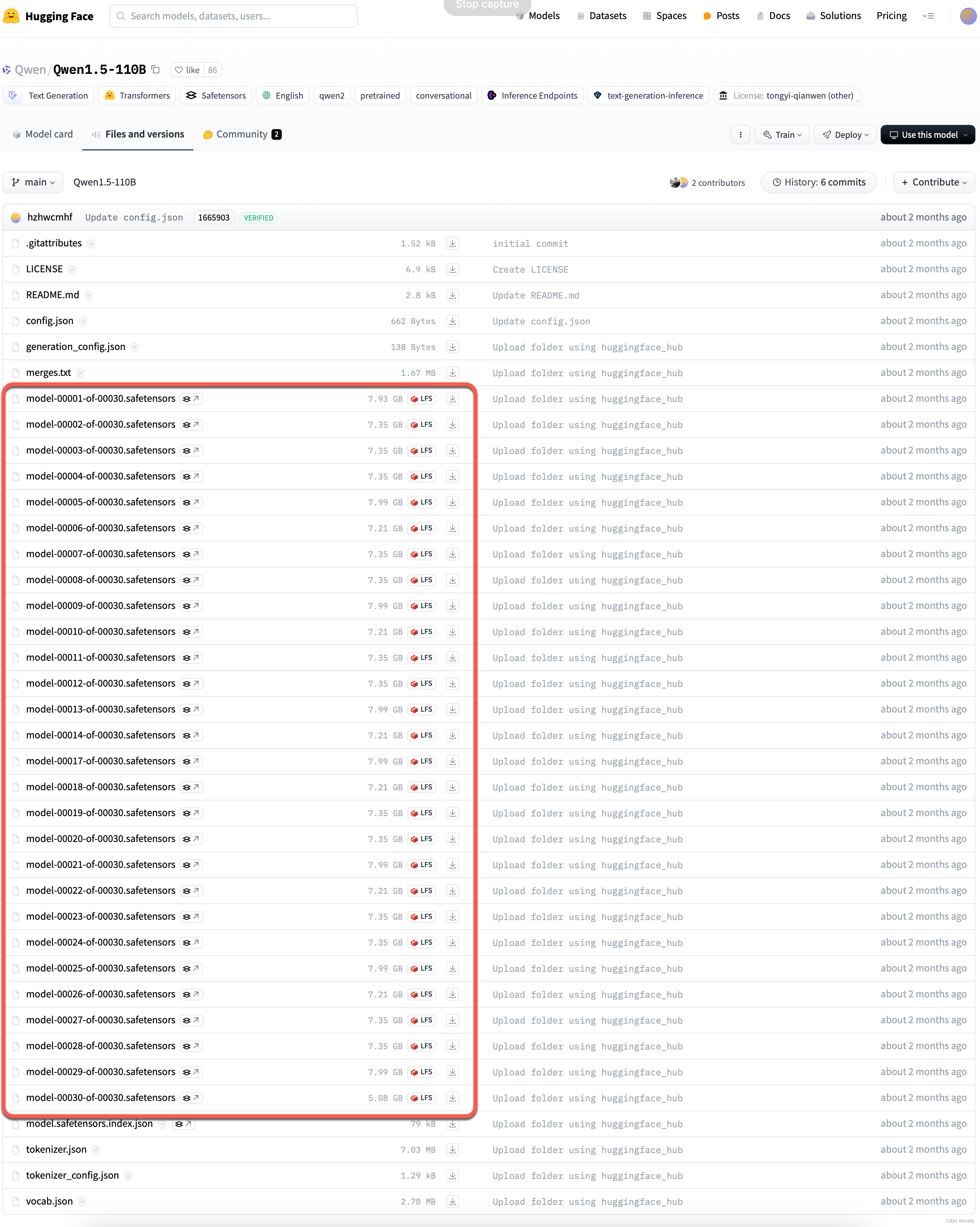
我们可以看下HF上Qwen1.5-110B的开源文件(该开源文件使用的是BF16位数,所以按照计算公式,体积大小为200G左右):
国内在HF上开源的大模型一般都是提供半精度(FP16或BF16)
大模型不光参数大,体积也巨大,要运行这个规模的模型,需要十分高的硬件配置,带来了很大的难度,成为阻碍人工智能发展的障碍,于是很多脑子好使的研究人员就提出了一系列的压缩技术,比如下面说到的常用的量化技术。
大模型量化技术
近年来,在深度学习领域中,研究人员探索使用低比特整数表示模型参数以实现模型的压缩与加速。量化(quantization)技术是其中的关键方法。
量化技术与int4、int8
- 量化技术:通过将浮点数映射到较低位数的整数来减小模型在计算和存储时的需求。
- int4: 使用4位二进制表示一个整数,存储模型参数。量化过程会将浮点数转换为可表示在有限范围内的整数值,并用4个比特记录这些值。
- int8: 类似于int4,但使用8位二进制表示整数,提供更大的表示范围和精确度。
内存占用
- int4:不直接以字节单位描述位数,通常通过位操作存储数据。
- int8:占用1个字节(即8位)空间。
注意事项
量化会导致信息损失,因此需要在压缩效果与模型性能之间进行权衡。根据具体任务需求选择合适的量化精度是关键步骤。通过许多评测综合来看到的结果,通常选择8位(int8)或更低的位宽来表示权重和激活值,但也可根据实际需求选择其他位宽,如BF16。
许多小伙伴在模型本地化尝试中会使用Ollama 来进行本地化部署,有人会觉得本地化部署后,Ollama加载的模型回答质量和能力有些下降。这是因为Ollama 致力于 实现 本地化部署大模型,限于本地化部署用户许多没有足够的算力,在通过
oll
这篇关于大模型项目落地时,该如何估算模型所需GPU算力资源的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!








