本文主要是介绍【有手就会】图数据库Demo教程,实现反洗钱场景下银行转账流水数据分析,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
前言
星环社区版家族于近期发布了单机、30s一键启动的StellarDB图数据库,本篇文章将为用户介绍如何使用开发版StellarDB实现人物关系探索。
友情链接:白话大数据 | 关于图数据库,没有比这篇更通俗易懂的啦
TDH社区版本次发布StellarDB社区版开发版,让更多用户地低资源成本上手体验企业级图数据库。如果您感兴趣的话,可以访问星环官网进行产品下载,StellarDB社区开发版是免费提供给大家的,欢迎大家下载使用。
StellarDB社区开发版相关链接
- StellarDB社区开发版安装手册(含演示视频)
- StellarDB使用手册
- 产品下载地址
- 更多社区版相关资源
- 《诡秘之主》中人物关系探索Demo
操作前提
您需要先基于安装手册完成StellarDB图数据库的安装后才可以开始进行下方操作。
一、 场景描述
金融技术的飞速进步促使金融机构规模急剧扩张,同时,洗钱犯罪活动亦随之进化,变得更为新颖、专业化、团伙导向且难以察觉,给反洗钱工作带来严峻挑战。在此背景下,本演示将以StellarDB的KGExplorer工具为核心,展示如何分析并可视化银行转账记录,从中抽丝剥茧,揭示潜在的反洗钱犯罪线索。
二、 数据集介绍
数据集结构

节点介绍
| 节点名称(label) | 节点包含的属性(数据的类型) |
|---|---|
| 客户 | 姓名(STRING)、地址(STRING) |
| 受益人 | 姓名(STRING)、地址(STRING) |
| 银行 | 名称(STRING) |
| 交易 | id(STRING)、金额(INT) |
边介绍
| 边名称(label) | 边的起始节点与指向节点 |
|---|---|
| 发起交易 | 客户指向交易 |
| 转账给 | 交易执行受益人 |
| 持有账户 | 客户指向银行 |
数据集获取
https://transwarp-ce-1253207870.cos.ap-shanghai.myqcloud.com/TDH-CE-2024-5/%E5%8F%8D%E6%B4%97%E9%92%B1%E4%B9%8B%E9%93%B6%E8%A1%8C%E8%BD%AC%E8%B4%A6%E6%B5%81%E6%B0%B4%E5%88%86%E6%9E%90.csv
三、 创建图谱并导入数据
1. 创建图谱(schema)
步骤一 进入KG Explorer,点击右上角“创建图”按钮,填写图名称进行创建



注意:StellarDB社区开发版创建图时,副本数只能为1。

2. 定义图谱
添加节点
按alt/command+左键单击。
在画布中添加节点后,将节点的“label”定义为“交易”,并为其添加“id”属性,属性类型为“STRING”,添加“金额”属性,属性类型为“INT”。添加完成后点击“保存”。

在画布中添加节点,将节点的的“label”定义为“客户”,并为其添加“姓名”与“地址”属性,属性类型为均为“STRING”,添加完成后点击“保存”。
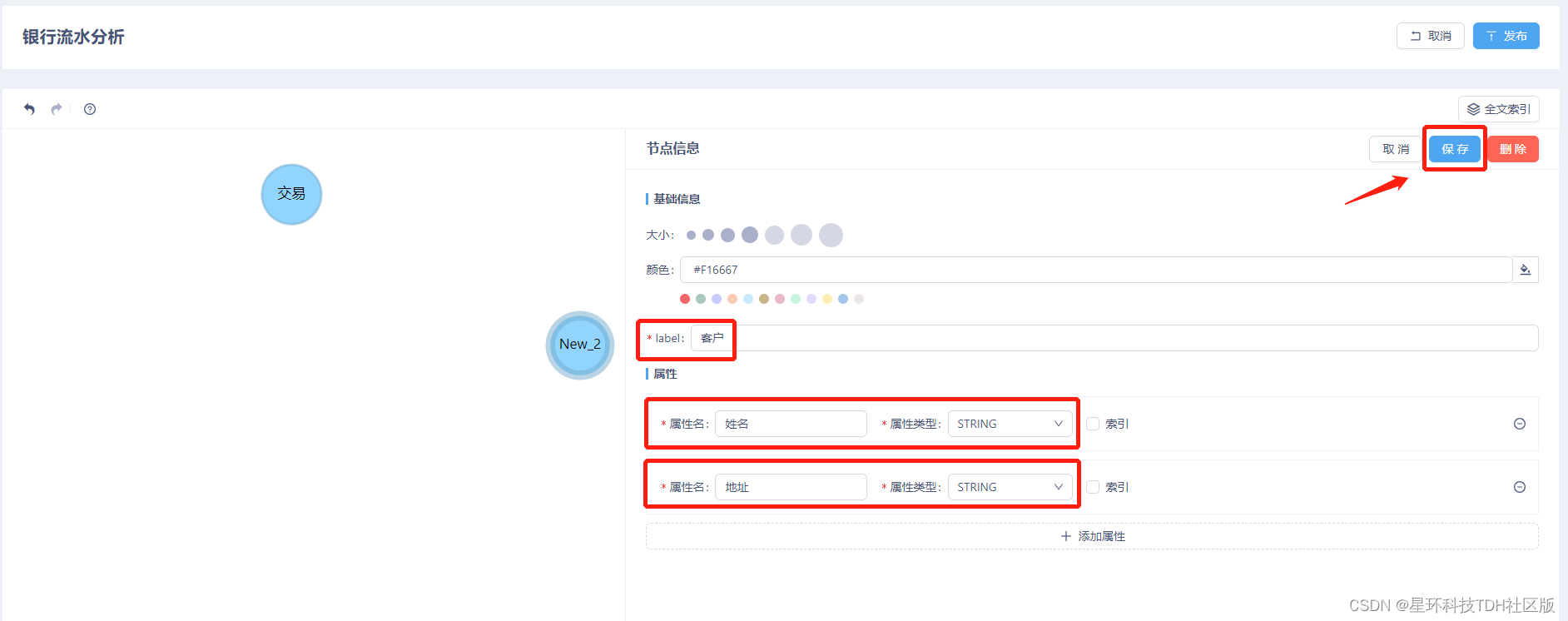
继续重复上述操作,分别添加“银行”与“受益人”等节点,并为其添加对应的属性及属性的数据类型(具体属性参考第二部分节点介绍中的表格)


tips: 可以选择将点的颜色进行差异化定义,以便于后续观察分析,最终效果如下:

添加关系
按住shift键同时选中两个节点完成关系添加
注意,关系具有指向性,先点击为起点,后点击为终点。
按住shift键,依次点击“客户”与“交易”,创建“客户”与“交易”节点之间的关系,label为“发起交易”,添加完成后点击“保存”。

重复上述操作,分别在“客户”与“银行”之间创建“持有账户”关系、“交易”与“受益人”之间创建“转账给”关系。

此时,图谱已经创建完成,点击右上角![]() 后,即可导入数据进行数据分析。
后,即可导入数据进行数据分析。
3. 导入数据
数据集上传
注意:在上传文件之前,需要提前对‘hive’用户进行赋权,否则上传时将报错。操作方式有两种,推荐使用Guardian赋权的方式解决。
a) 在Guardian服务界面“一键开启安全”后,访问Guardian Server界面对hive用户赋予 HDFS 的 ‘/’ 目录可读可写可执行的权限。(推荐操作)
b) 未开启Guardian时,在服务端初始化客户端后,执行如下命令:
export HADOOP_USER_NAME=hdfs
hdfs dfs -chmod -R 777 /
步骤一 在图管理页面找到刚刚创建的图谱,点击“导数”进入数据导入页面。
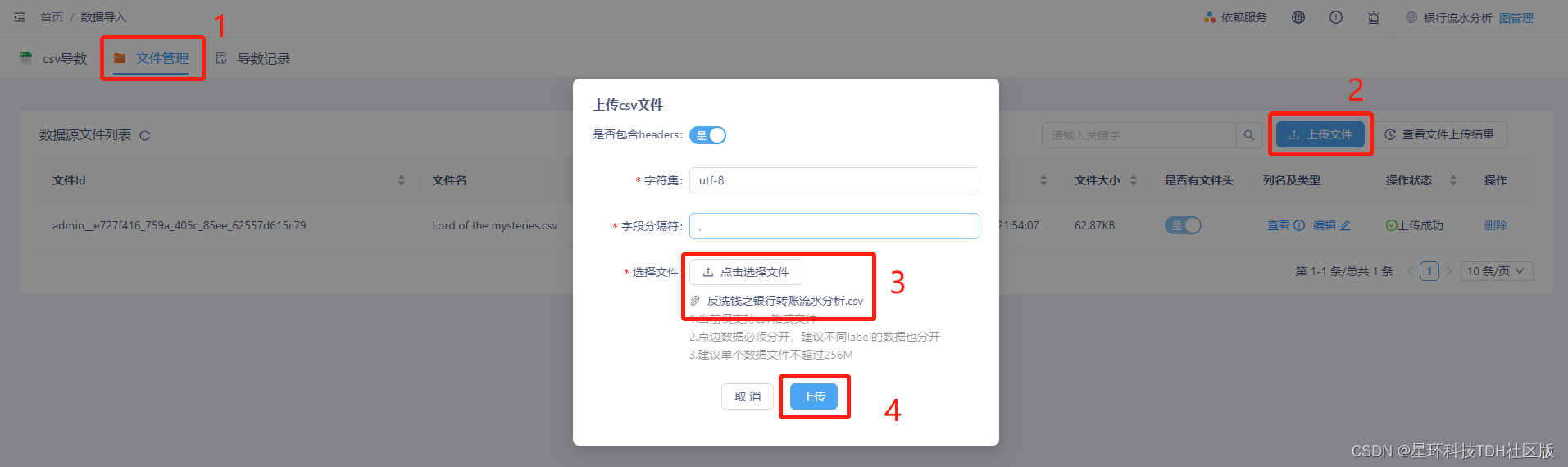
步骤二 下载<第二部分数据集获取>中的数据集后上传至KG
在“数据导入”页面中选择“文件管理”,点击“上传文件”选择下载好的csv文件,将其上传至KG。上传成功后可以看到数据源文件列表中有对应的文件显示。

修改列属性
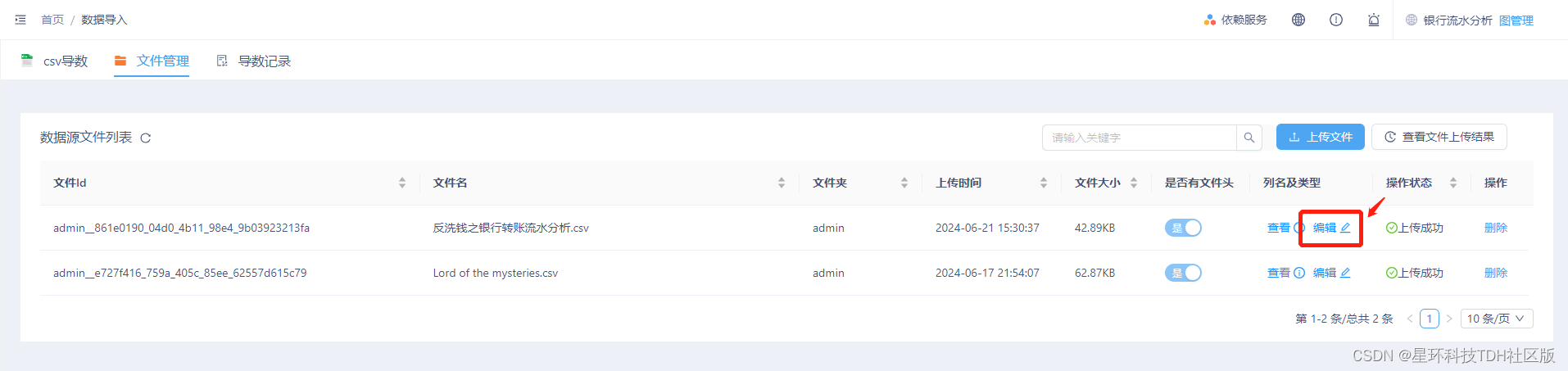
点击编辑,将“col0”列的列名改为“客户姓名”,将“交易金额”列的数据类型改为“int”。


csv导数
然后,返回csv导数页面,按照如下顺序,依次点击选中目标数据集。注意:此处需点击7次 ‘添加’,然后将添加文件分别设定为4个“点”与3条“边”。


配置点属性映射
先对4个点数据配置属性映射。具体映射配置的内容为:
第一个点数据对应点的uid为“客户姓名”,label映射为“客户”;下方属性映射:图属性“姓名”对应的映射列名为“客户姓名”、“地址”对应“客户地址”。可参照下图进行配置:
第二个点数据“交易”属性配置如下所示:

第三个点数据“受益人姓名”属性配置如下所示:

第四个点数据“银行名称”属性配置如下所示:

配置边属性映射
接着对边数据进行起点uid、终点uid映射配置。具体配置内容为:
- 1) 边label映射为“发起交易”、起点uid为“客户姓名”、起点label映射为“客户”、终点uid为“交易id”、终点label映射为“交易”。
- 2) 边label映射为“转账给”、起点uid为“交易id”、起点label映射为“交易”、终点uid为“受益人姓名”、终点label映射为“受益人”。
- 3) 边label映射为“持有账户”、起点uid为“客户姓名”、起点label映射为“客户”、终点uid为“银行名称”、终点label映射为“银行”。

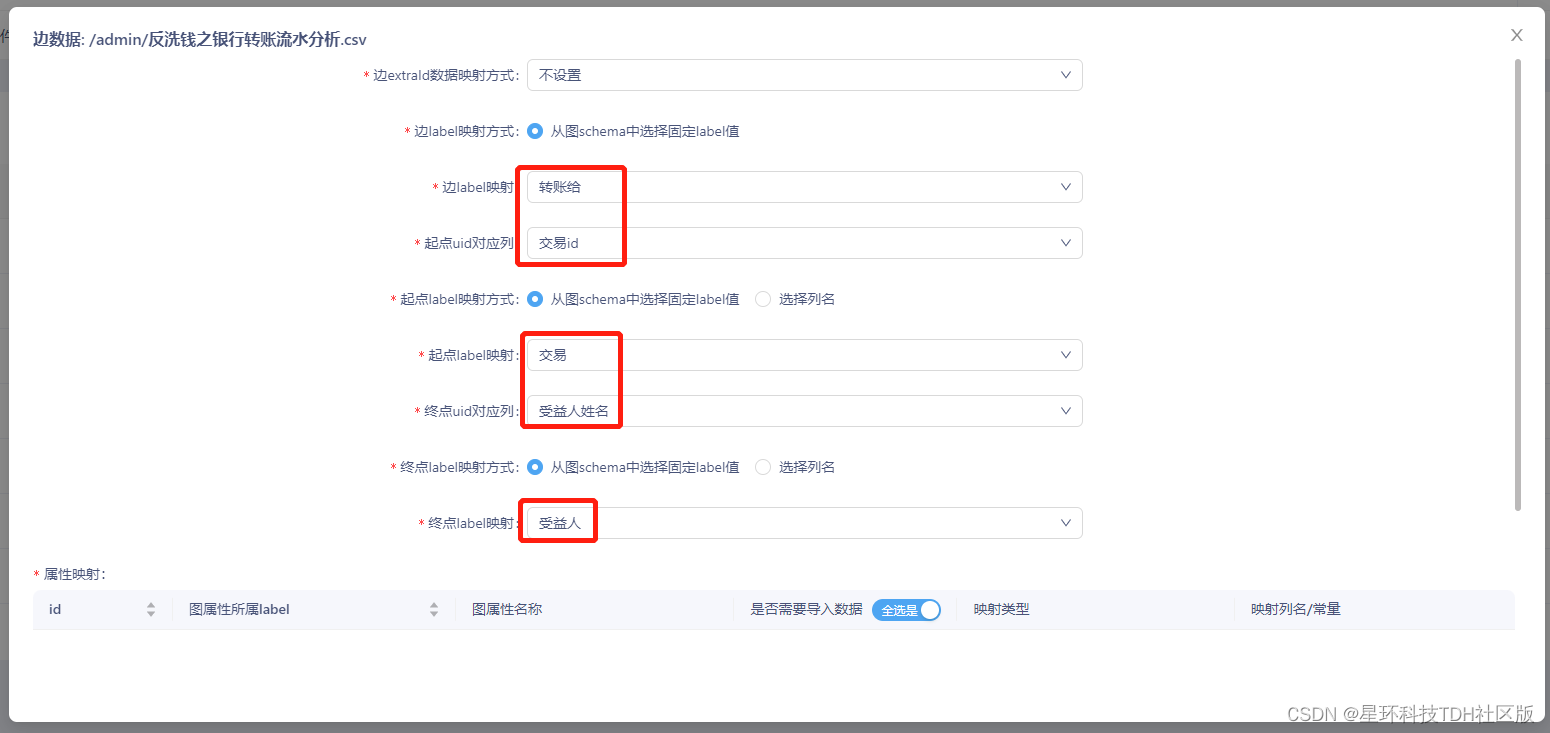

配置完成后,点击右下角“导入”,等待数秒钟后,即可完成数据导入。

Note:导入完成后可以点击右侧感叹号查看是否有失败的,如果有的话仔细查看是否前面的步骤配置有问题,进行重新映射或修改点/边数据。

四、 展示节点关系
回到首页进入图探索页面。

操作示例1. 展示客户与银行节点之间的关系
MATCH (c:客户)-[a:持有账户]->(b:银行)
RETURN c,a,b
limit 100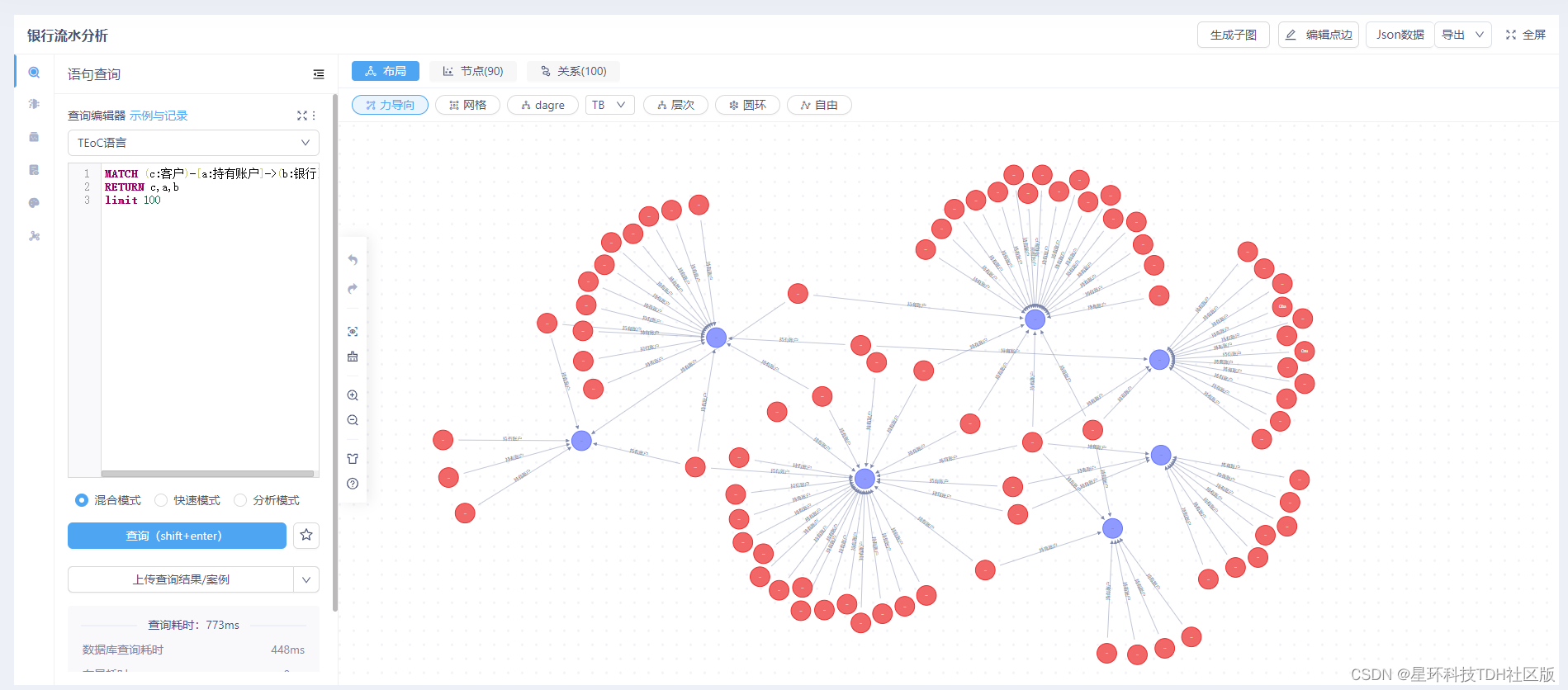
操作示例2. 展示客户节点、交易节点、受益人节点之间的关系。
MATCH (c:客户)-[f:发起交易]->(t:交易)-[z:转账给]->(s:受益人)
RETURN c,f,t,z,s
limit 50
五、 数据分析
交易异常检测
检测大额交易:金额超过1000万的交易
MATCH (c:客户)-[f:发起交易]->(t:交易)-[z:转账给]->(s:受益人)
WHERE t.金额 > 10000000
RETURN c,f,t,z,s
检测频繁的小额交易:金额10000以内,且超过10笔交易
MATCH (c:客户)-[f:发起交易]->(t:交易)
WHERE t.金额 < 10000
WITH c, COUNT(t) AS transactionCount
WHERE transactionCount > 10
RETURN transactionCount,c
关系网络分析
查询频繁交易的客户与受益人,超过5次的相同客户与受益人的转账,并展示交易次数
MATCH (c:客户)-[:发起交易]->(t:交易)-[:转账给]->(b:受益人)
WITH c, b, COUNT(t) as transactionCount WHERE transactionCount > 5
RETURN c.姓名 AS 客户名字, b.姓名 AS 受益人名字, transactionCount
ORDER BY transactionCount DESC
客户交易行为分析
找出进行交易次数最多的客户,了解哪些客户最活跃。
MATCH (c:客户)-[:发起交易]->(:交易)
WITH c, COUNT(*) AS transactionCount
ORDER BY transactionCount DESC
LIMIT 10
RETURN c.姓名 AS 客户名字, transactionCount AS 交易次数
受益人地址聚类分析
基于受益人地址分析资金流向的地域分布
MATCH (:交易)-[:转账给]->(b:受益人)
WITH b.地址 AS Address, COUNT(*) AS TransferCount
RETURN Address, TransferCount
ORDER BY TransferCount DESC
了解各银行被多少客户持有账户,评估银行的市场占有率
MATCH (c:客户)-[:持有账户]->(b:银行)
WITH b, COUNT(DISTINCT c) AS accountHolders
RETURN b.名称 AS 银行名称, accountHolders AS 账户持有者数量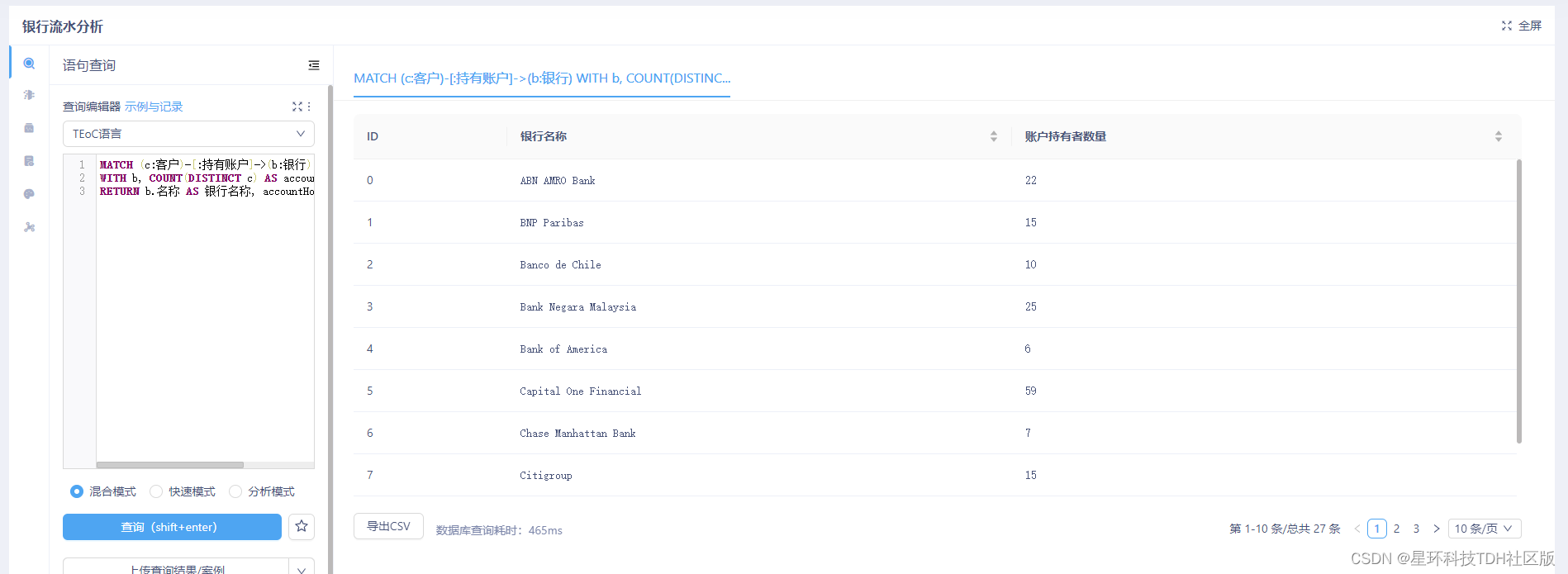
以上就是完整的demo教程,希望对您快速上手图数据库有所帮助,如果还有想要学习了解的内容,欢迎多多留言~~
这篇关于【有手就会】图数据库Demo教程,实现反洗钱场景下银行转账流水数据分析的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





