本文主要是介绍使用sherpa-ncnn进行中文语音识别(ubuntu22),希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
语音大模型专栏总目录
获取该开源项目的渠道,是我在b站上,看到了由csukuangfj制作的一套语音识别视频。以下地址均为csukuangfj在视频中提供,感谢分享!
新一代Kaldi + RISC-V: VisionFive2 上的实时中英文语音识别_哔哩哔哩_bilibili
开源项目地址:GitHub - k2-fsa/sherpa-ncnn: Real-time speech recognition using next-gen Kaldi with ncnn without Internet connection. Support iOS, Android, Raspberry Pi, VisionFive2, LicheePi4A etc.
文档地址:Python API — sherpa 1.3 documentation
该开源项目可以在linux\windows\ios\安卓使用
我用的机器是ubuntu22虚拟机进行测试
请注意,需要首先安装安装了所有必要的依赖项,包括 CMake、Git 和一个合适的 C/C++ 编译器。如果遇到任何问题,您可以查看 sherpa-ncnn 的 GitHub 仓库(Issues · k2-fsa/sherpa-ncnn · GitHub)或相关文档获取帮助。
使用sherpa-ncnn前,安装并编译过kaldi,所以在编译sherpa-ncnn前只安装了cmake
安装命令如下:
sudo apt install cmake其他依赖如需安装,可以参考kaldi的相关依赖安装
详细解析Ubuntu22 部署Kaldi大模型-CSDN博客
一、安装sherpa-ncnn
(!!!按照文档写的,使用python的同志直接跳过,看二、使用sherpa-ncnn的python API实现语音识别)
按照要求,执行安装命令:
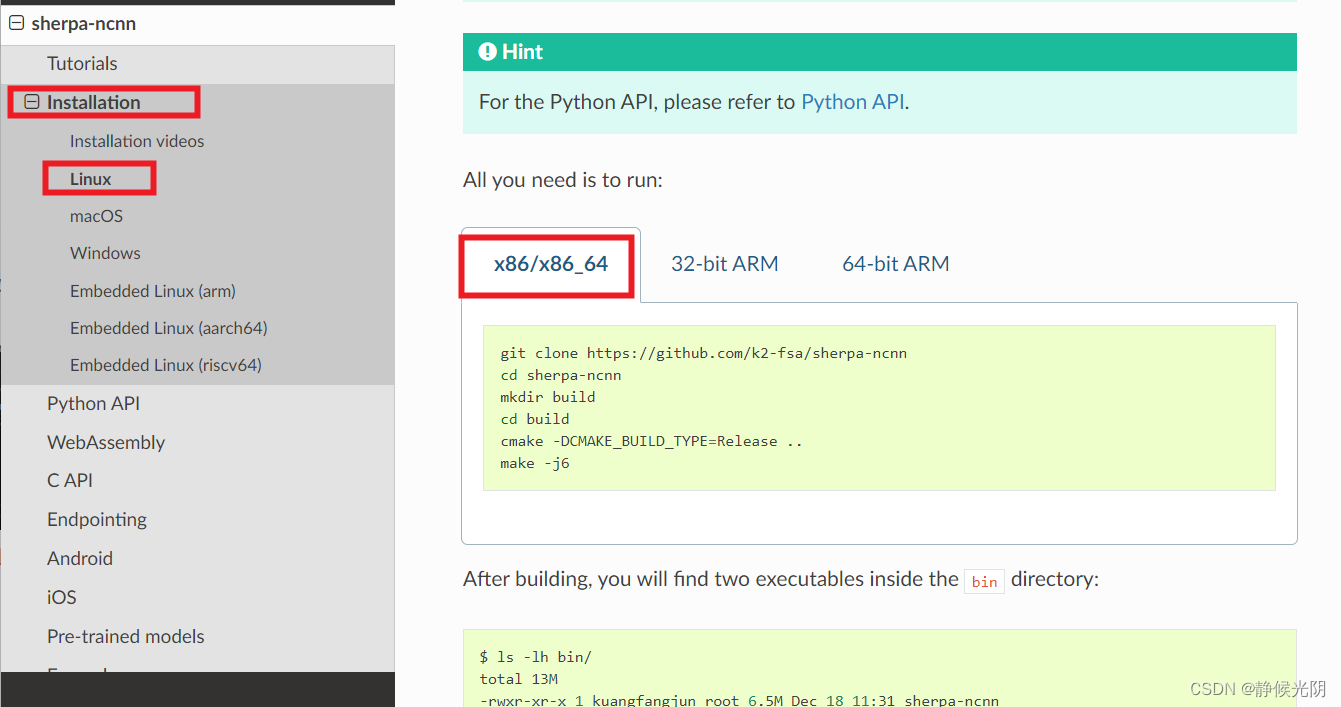
(一)下载sherpa-ncnn脚本文件
git clone https://github.com/k2-fsa/sherpa-ncnn
(二)编译
1. 进入sherpa-ncnn文件夹后,新建build文件并进入build目录
cd sherpa-ncnn
mkdir build
cd build
2. 配置编译
cmake -DCMAKE_BUILD_TYPE=Release ..

3. 开始编译
make -j 6编译后结果显示如下:

编译后,在bin文件夹获得这两个文件:

4.(可选)剥离二进制文件:
您可以通过 strip 命令减小二进制文件的大小,移除调试符号
回到sherpa-ncnn文件夹中,执行下列命令:
strip bin/sherpa-ncnn
strip bin/sherpa-ncnn-microphone
二、使用sherpa-ncnn的Python API实现语音识别
参考Python API — sherpa 1.3 documentation
我们将实现如下工作:
实时语音识别
识别一个文件
(一) 安装必备软件及依赖
在Linux或Windows上使用时,python版本必须>=3.6
如果您使用方法1,它将安装预编译的库。缺点是它可能没有针对您的平台进行优化,而优点是您不需要安装cmake或C++编译器。
对于其他方法,需要先执行以下命令:
安装cmake:
pip install cmakeC++编译器,例如在Linux和macOS上的GCC,在Windows上的Visual Studio,这里我们使用的ubuntu22所以安装gcc
sudo apt update
sudo apt install build-essential
build-essential 包含了编译 C 和 C++ 程序所需的工具,其中就包括 GCC。
安装完成后,您可以通过以下命令来检查 GCC 的版本,以确保它已正确安装:
gcc --version
(二)安装 Python 包 sherpa-ncnn
1. 方法1
安装sherpa-ncnn包
pip install sherpa-ncnn安装完毕显示如下:

2. 方法2
下载并进入sherpa-ncnn文件夹
git clone https://github.com/k2-fsa/sherpa-ncnn
cd sherpa-ncnn
执行安装命令(按照官网说法没有使用sudo命令,会报错)
sudo python3 setup.py install
3. 方法3
直接使用以下命令进行安装
pip install git+https://github.com/k2-fsa/sherpa-ncnn4. 方法4(适用于开发者和嵌入式开发板)
针对不同平台,有不同的安装方式。

使用ubuntu22平台,使用x86_64的安装方法
# 下载sherpa-ncnn
git clone https://github.com/k2-fsa/sherpa-ncnn
# 进入sherpa-ncnn目录
cd sherpa-ncnn
# 新建build目录
mkdir build
# 进入build目录
cd build# 配置编译
cmake \-D SHERPA_NCNN_ENABLE_PYTHON=ON \-D SHERPA_NCNN_ENABLE_PORTAUDIO=OFF \-D BUILD_SHARED_LIBS=ON \..
# 开始编译
make -j6配置环境变量
export PYTHONPATH=$PWD/lib:$PWD/../sherpa-ncnn/python:$PYTHONPATH5. 检查安装是否成功
(1)检查方法1
使用命令,导入sherpa-ncnn和_sherpa_ncnn两个包,并显示其所在路径
python3 -c "import sherpa_ncnn; print(sherpa_ncnn.__file__)"
python3 -c "import _sherpa_ncnn; print(_sherpa_ncnn.__file__)"执行完毕显示如下:

(2)检查方法2
使用命令,显示sherpa-ncnn的版本号
python3 -c "import sherpa_ncnn; print(sherpa_ncnn.__version__)"执行后显示如下:

(三)实时语音识别
安装python图形化编译器geany,命令如下:
sudo apt install geany1.实时语音识别(使用麦克风)
(1)环境配置
A. 设置虚拟机共享主机麦克风
a.在VirtualBox虚拟机窗口右下角,点击音频,在声音输入上打勾

b.在ubuntu22声音设置中,声音输入选择“line in”,并关掉设置窗口。
B. 测试麦克风
rec test.wav使用"Ctrl+C"结束录音,可以直接双击test.wav文件进行播放,检查刚才是否已经将声音录制进去。
C. 安装python声音设备驱动包,命令如下:
pip install sounddeviceD. 让python命令可以直接调用python3,执行如下命令
sudo update-alternatives --install /usr/bin/python python /usr/bin/python3 10
E. 安装portaudio(我在后面的执行中的出现了报错,显示sounddevice不包括protaudio,解决办法就是单独安装一下),命令如下
sudo apt install portaudio19-dev(2)使用下列代码
可以直接从这里下载代码:https://github.com/k2-fsa/sherpa-ncnn/blob/master/python-api-examples/speech-recognition-from-microphone.py
在shell窗口中输入geany,打开编译器。复制代码并另存为speech-recognition-from-microphone.py(该文件只有在sherpa-ncnn下可以使用)
import systry:import sounddevice as sd
except ImportError as e:print("Please install sounddevice first. You can use")print()print(" pip install sounddevice")print()print("to install it")sys.exit(-1)import sherpa_ncnndef create_recognizer():# Please replace the model files if needed.# See https://k2-fsa.github.io/sherpa/ncnn/pretrained_models/index.html# for download links.recognizer = sherpa_ncnn.Recognizer(tokens="./sherpa-ncnn-conv-emformer-transducer-2022-12-06/tokens.txt",encoder_param="./sherpa-ncnn-conv-emformer-transducer-2022-12-06/encoder_jit_trace-pnnx.ncnn.param",encoder_bin="./sherpa-ncnn-conv-emformer-transducer-2022-12-06/encoder_jit_trace-pnnx.ncnn.bin",decoder_param="./sherpa-ncnn-conv-emformer-transducer-2022-12-06/decoder_jit_trace-pnnx.ncnn.param",decoder_bin="./sherpa-ncnn-conv-emformer-transducer-2022-12-06/decoder_jit_trace-pnnx.ncnn.bin",joiner_param="./sherpa-ncnn-conv-emformer-transducer-2022-12-06/joiner_jit_trace-pnnx.ncnn.param",joiner_bin="./sherpa-ncnn-conv-emformer-transducer-2022-12-06/joiner_jit_trace-pnnx.ncnn.bin",num_threads=4,)'''# 可以使用这里的代码,将浮点16位,改为8位recognizer = sherpa_ncnn.Recognizer(tokens="./sherpa-ncnn-conv-emformer-transducer-2022-12-06/tokens.txt",encoder_param="./sherpa-ncnn-conv-emformer-transducer-2022-12-06/encoder_jit_trace-pnnx.ncnn.int8.param",encoder_bin="./sherpa-ncnn-conv-emformer-transducer-2022-12-06/encoder_jit_trace-pnnx.ncnn.int8.bin",decoder_param="./sherpa-ncnn-conv-emformer-transducer-2022-12-06/decoder_jit_trace-pnnx.ncnn.param",decoder_bin="./sherpa-ncnn-conv-emformer-transducer-2022-12-06/decoder_jit_trace-pnnx.ncnn.bin",joiner_param="./sherpa-ncnn-conv-emformer-transducer-2022-12-06/joiner_jit_trace-pnnx.ncnn.int8.param",joiner_bin="./sherpa-ncnn-conv-emformer-transducer-2022-12-06/joiner_jit_trace-pnnx.ncnn.int8.bin",num_threads=4,'''return recognizerdef main():print("Started! Please speak")recognizer = create_recognizer()sample_rate = recognizer.sample_ratesamples_per_read = int(0.1 * sample_rate) # 0.1 second = 100 mslast_result = ""with sd.InputStream(channels=1, dtype="float32", samplerate=sample_rate) as s:while True:samples, _ = s.read(samples_per_read) # a blocking readsamples = samples.reshape(-1)recognizer.accept_waveform(sample_rate, samples)result = recognizer.textif last_result != result:last_result = resultprint(result)if __name__ == "__main__":devices = sd.query_devices()print(devices)default_input_device_idx = sd.default.device[0]print(f'Use default device: {devices[default_input_device_idx]["name"]}')try:main()
(3)创建识别器:使用模型: csukuangfj/sherpa-ncnn-conv-emformer-transducer-2022-12-06 (Chinese + English) 可以同时识别英语和中文。
A. 进入sherpa-ncnn目录
cd /path/to/sherpa-ncnnB.执行下列命令,下载模型
wget https://github.com/k2-fsa/sherpa-ncnn/releases/download/models/sherpa-ncnn-conv-emformer-transducer-2022-12-06.tar.bz2
tar xvf sherpa-ncnn-conv-emformer-transducer-2022-12-06.tar.bz2(4)执行语音识别功能
进入sherpa-ncnn目录
执行speech-recognition-from-microphone.py脚本,命令如下:
python speech-recognition-from-microphone.py
(四)识别一个Wav文件
wav文件要求:波形文件的采样率必须是 16 kHz。此外,它应该只包含一个通道,并且采样应该以 16 位(即 int16)编码。
1. 获得脚本
下载脚本地址:https://github.com/k2-fsa/sherpa-ncnn/blob/master/python-api-examples/decode-file.py
也可以复制下面脚本内容到decode-file.py(该文件只有在sherpa-ncnn下可以使用)
import waveimport numpy as np
import sherpa_ncnndef main():recognizer = sherpa_ncnn.Recognizer(tokens="./sherpa-ncnn-conv-emformer-transducer-2022-12-06/tokens.txt",encoder_param="./sherpa-ncnn-conv-emformer-transducer-2022-12-06/encoder_jit_trace-pnnx.ncnn.param",encoder_bin="./sherpa-ncnn-conv-emformer-transducer-2022-12-06/encoder_jit_trace-pnnx.ncnn.bin",decoder_param="./sherpa-ncnn-conv-emformer-transducer-2022-12-06/decoder_jit_trace-pnnx.ncnn.param",decoder_bin="./sherpa-ncnn-conv-emformer-transducer-2022-12-06/decoder_jit_trace-pnnx.ncnn.bin",joiner_param="./sherpa-ncnn-conv-emformer-transducer-2022-12-06/joiner_jit_trace-pnnx.ncnn.param",joiner_bin="./sherpa-ncnn-conv-emformer-transducer-2022-12-06/joiner_jit_trace-pnnx.ncnn.bin",num_threads=4,)'''# 可以使用这里的代码,将浮点16位,改为8位 recognizer = sherpa_ncnn.Recognizer(tokens="./sherpa-ncnn-conv-emformer-transducer-2022-12-06/tokens.txt",encoder_param="./sherpa-ncnn-conv-emformer-transducer-2022-12-06/encoder_jit_trace-pnnx.ncnn.int8.param",encoder_bin="./sherpa-ncnn-conv-emformer-transducer-2022-12-06/encoder_jit_trace-pnnx.ncnn.int8.bin",decoder_param="./sherpa-ncnn-conv-emformer-transducer-2022-12-06/decoder_jit_trace-pnnx.ncnn.param",decoder_bin="./sherpa-ncnn-conv-emformer-transducer-2022-12-06/decoder_jit_trace-pnnx.ncnn.bin",joiner_param="./sherpa-ncnn-conv-emformer-transducer-2022-12-06/joiner_jit_trace-pnnx.ncnn.int8.param",joiner_bin="./sherpa-ncnn-conv-emformer-transducer-2022-12-06/joiner_jit_trace-pnnx.ncnn.int8.bin",num_threads=4,
)'''filename = ("./sherpa-ncnn-conv-emformer-transducer-2022-12-06/test_wavs/1.wav")with wave.open(filename) as f:assert f.getframerate() == recognizer.sample_rate, (f.getframerate(),recognizer.sample_rate,)assert f.getnchannels() == 1, f.getnchannels()assert f.getsampwidth() == 2, f.getsampwidth() # it is in bytesnum_samples = f.getnframes()samples = f.readframes(num_samples)samples_int16 = np.frombuffer(samples, dtype=np.int16)samples_float32 = samples_int16.astype(np.float32)samples_float32 = samples_float32 / 32768recognizer.accept_waveform(recognizer.sample_rate, samples_float32)tail_paddings = np.zeros(int(recognizer.sample_rate * 0.5), dtype=np.float32)recognizer.accept_waveform(recognizer.sample_rate, tail_paddings)recognizer.input_finished()print(recognizer.text)if __name__ == "__main__":main()2. 执行脚本
执行decode-file.py脚本,将对sherpa-ncnn//sherpa-ncnn-conv-emformer-transducer-2022-12-06/test_wavs/1.wav文件进行转换
python decode-file.py执行结果如下:

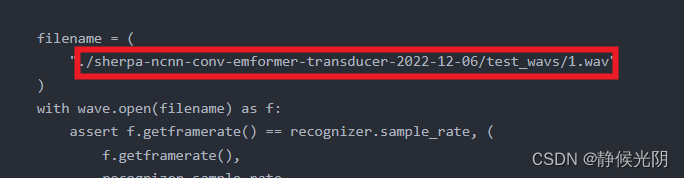
3. 替换指定文件路径
如果想要对指定文件进行转换,可以修改脚本红框内容为想要转换的wav文件的路径。
要了解预训练模型以获取更多模型,可以参考Pre-trained models — sherpa 1.3 documentation
这篇关于使用sherpa-ncnn进行中文语音识别(ubuntu22)的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






