本文主要是介绍labelme 标注岩石薄片数据集流程,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
labelme 数据标注使用流程
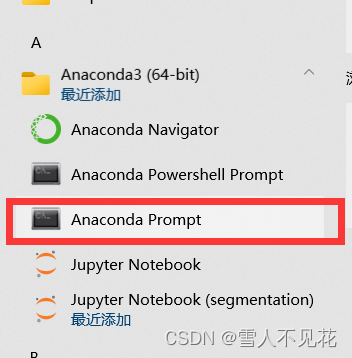
- 1.打开anaconda环境
- 2.打开labelme工具
- 3.打开数据集文件夹
- 4.开始标注
- 5. 标注完成
- 6. 修改labels.txt文件
- 7. 将标注结果可视化
- 8. 完成json转图片
- 9. 全部命令总结
1.打开anaconda环境
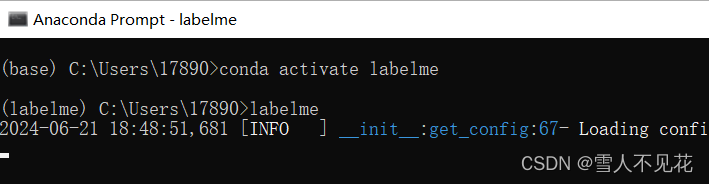
2.打开labelme工具
输入下列两条命令,打开labelme工具
(前提是本机anaconda中已经安装了labelme工具)
conda activate labelme
labelme
输入完成后,此窗口不可关闭
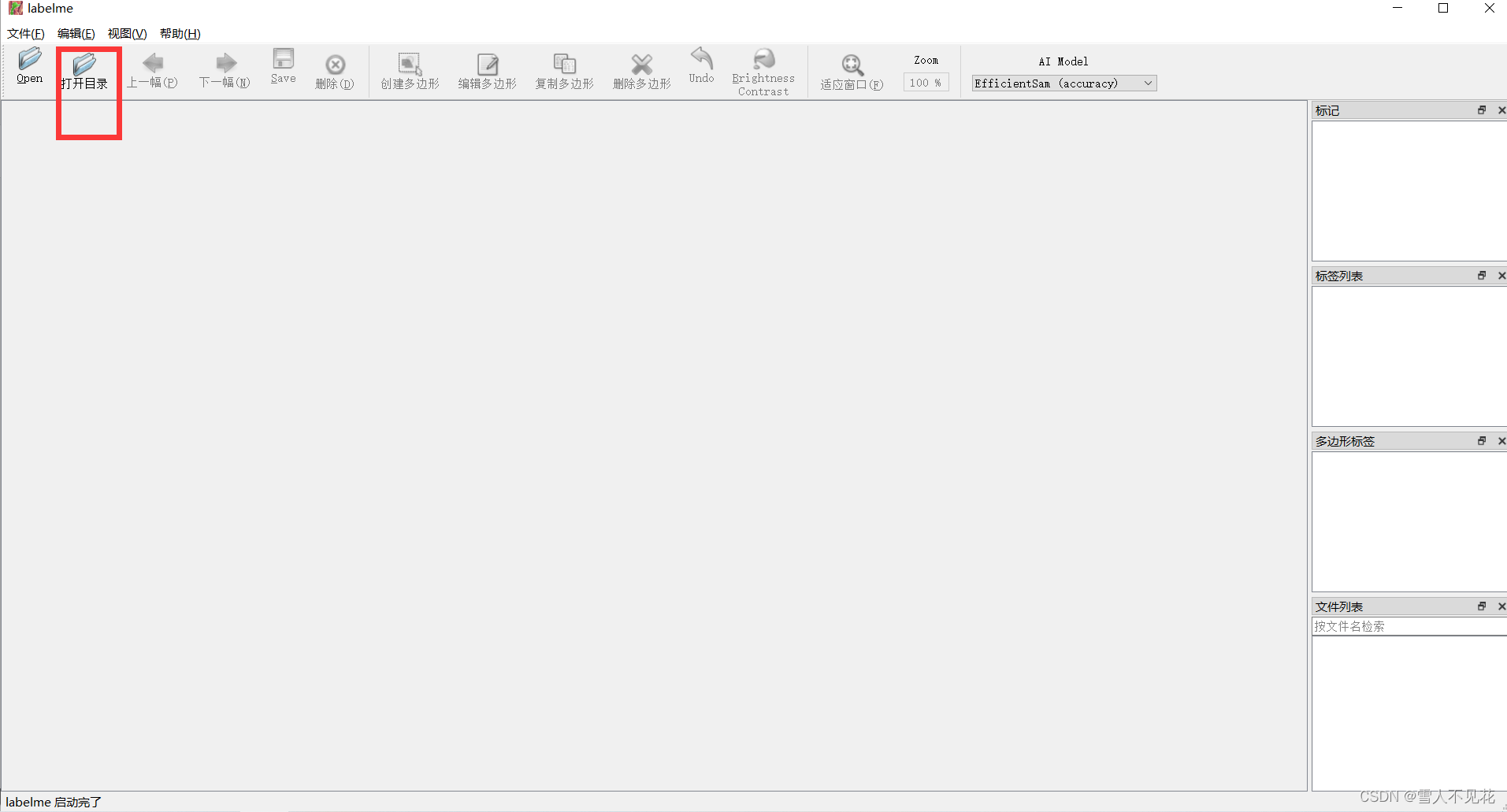
3.打开数据集文件夹
注意:打开一个文件夹后,要将本文件夹中的所有图片全部标注完成后,再可以关闭labelme图形界面(防止文件混乱)
打开完成后界面如下:
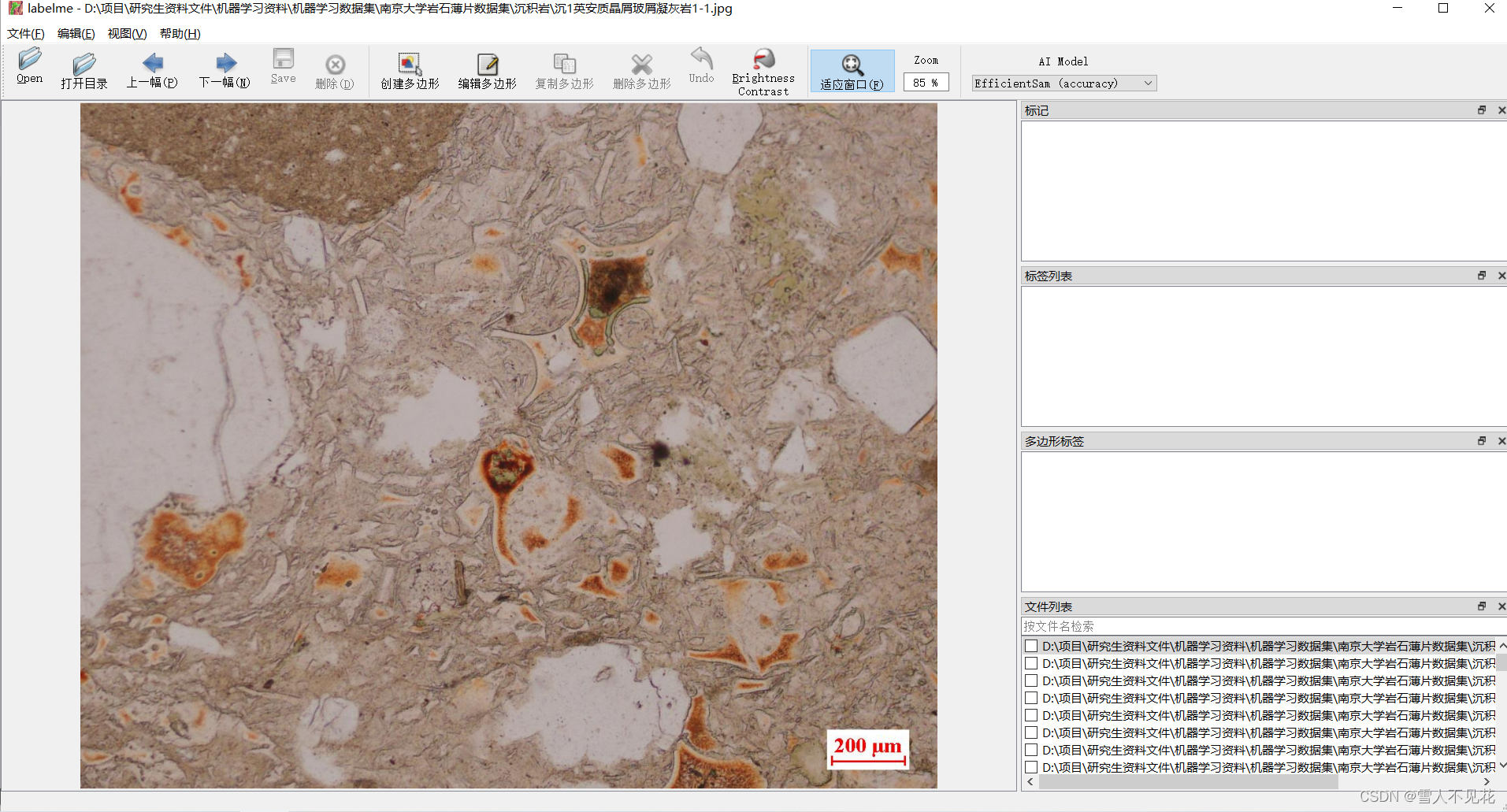
4.开始标注
4.1 点击编辑按钮,选择创建标注的类型
这里选择create-AI-Polygon,采用ai辅助标注
注意:ai辅助标注速度块,但是精度或许不够,要注意附加手动调整来确保标注具有较高精度
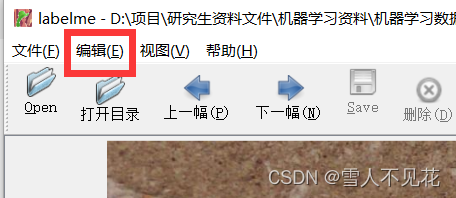
4.2 在区域中间打上关键点来调整标注内容
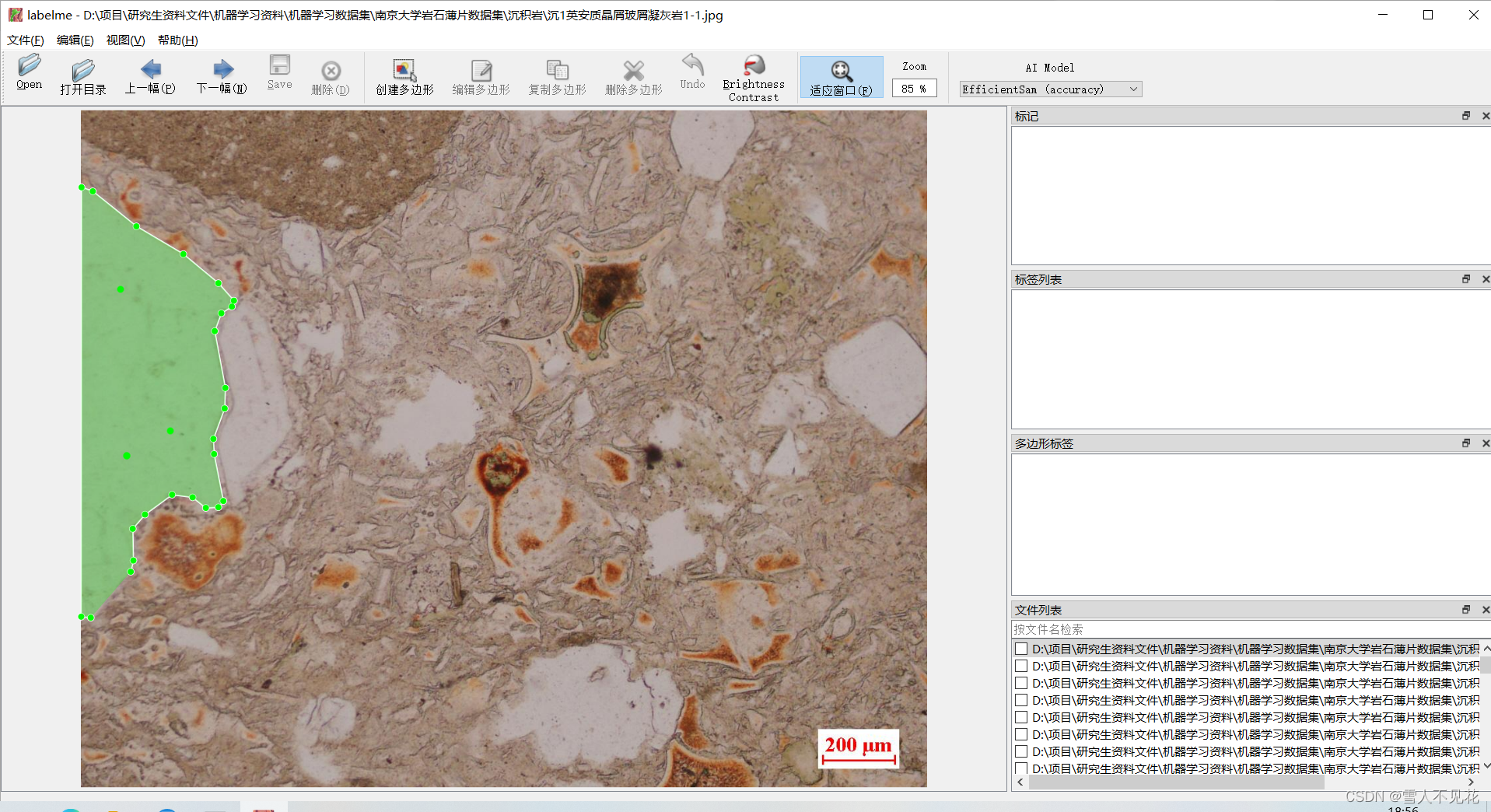
4.3 调整完成后,左键双击完成本区域标注
完成本区域标注,,然后键入岩石类型,这里以test为例
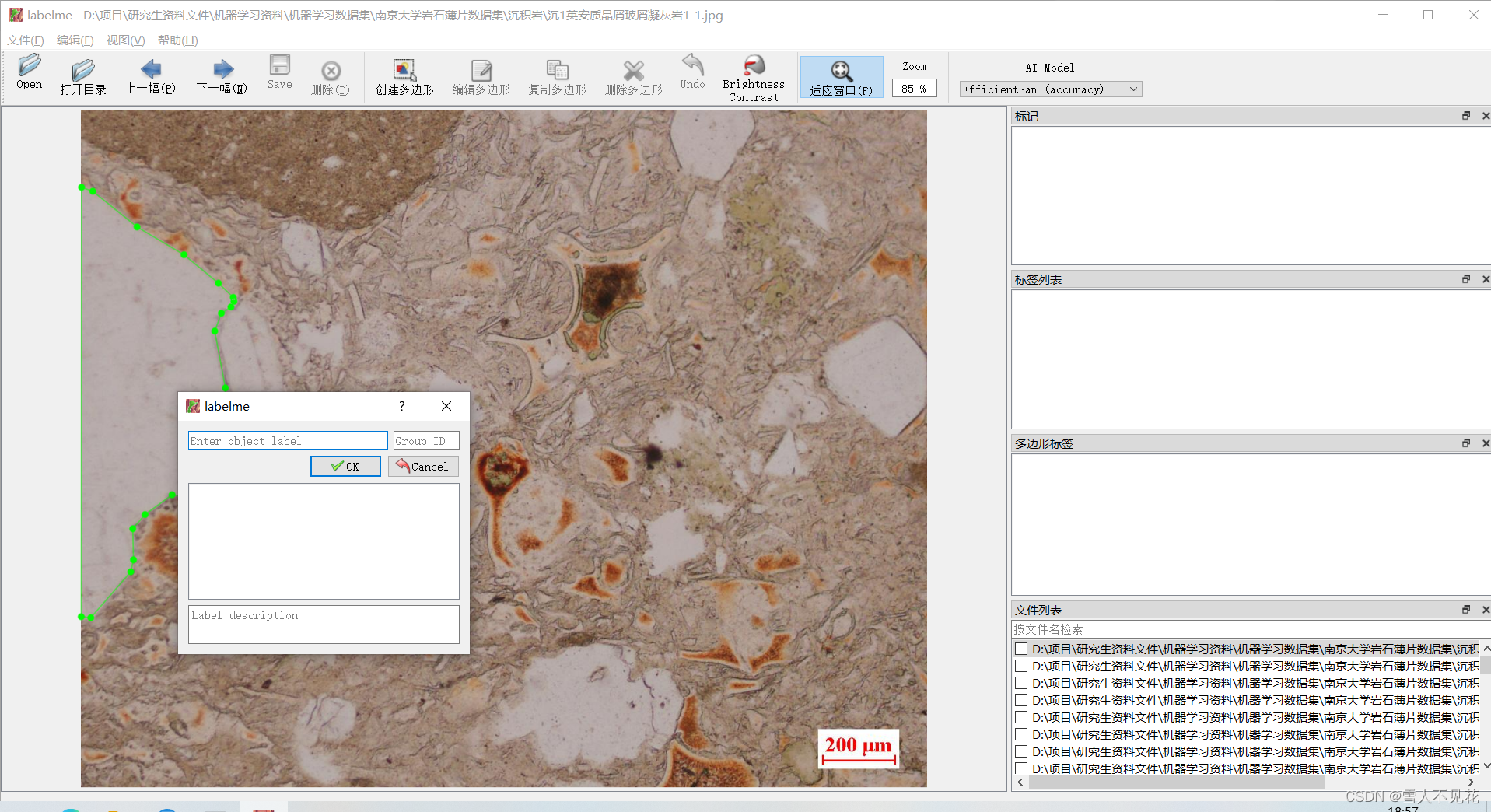
4.4 键入标签后,右侧会显示标签列表
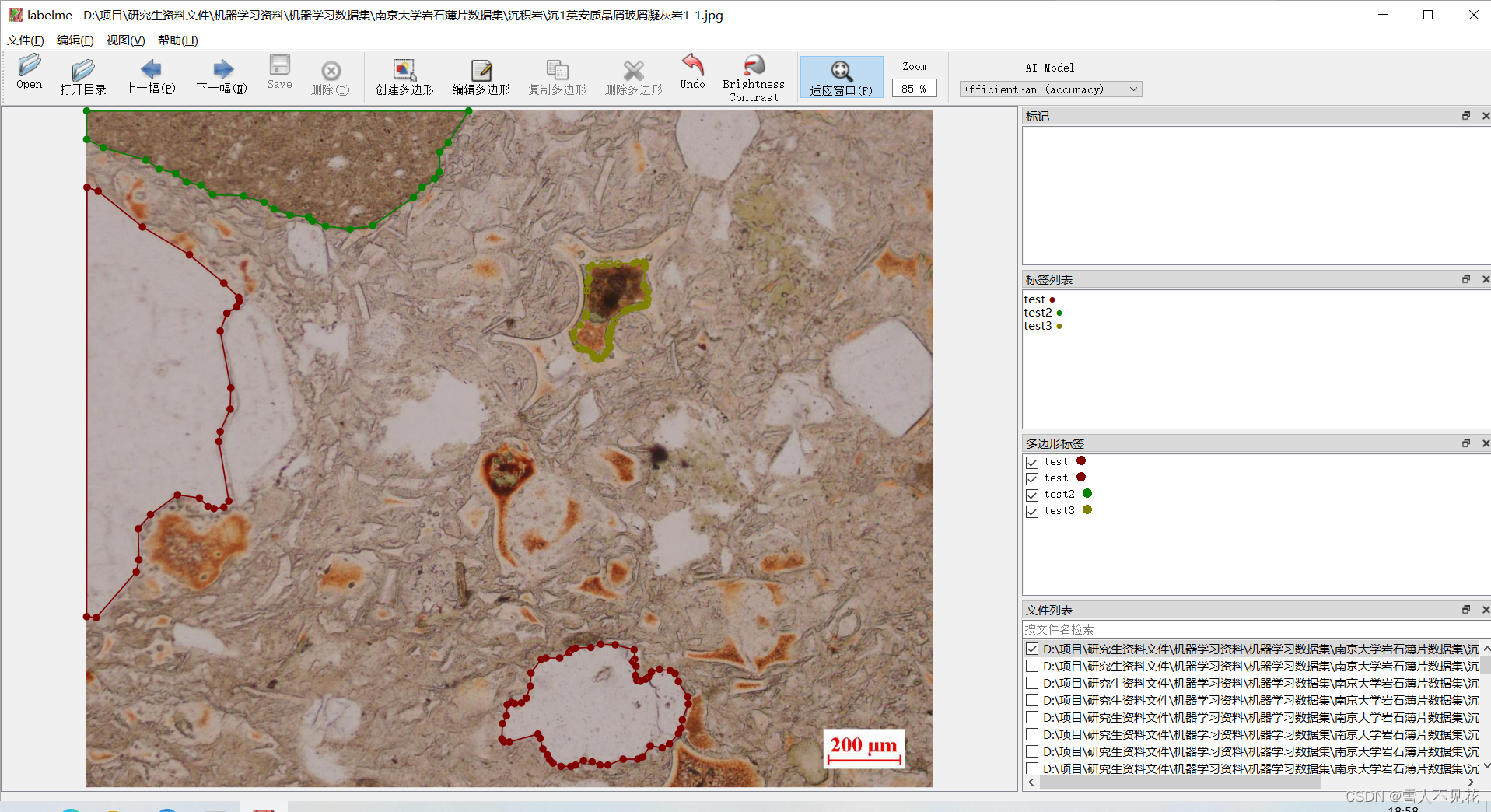
4.5 撤销标注点
若标注点打错,则可以选择单击右键,选择撤销最后的控制点,来撤销上一个操作
4.6 若ai辅助标注不合理,也可以选择"创建多边形"来进行数据标注
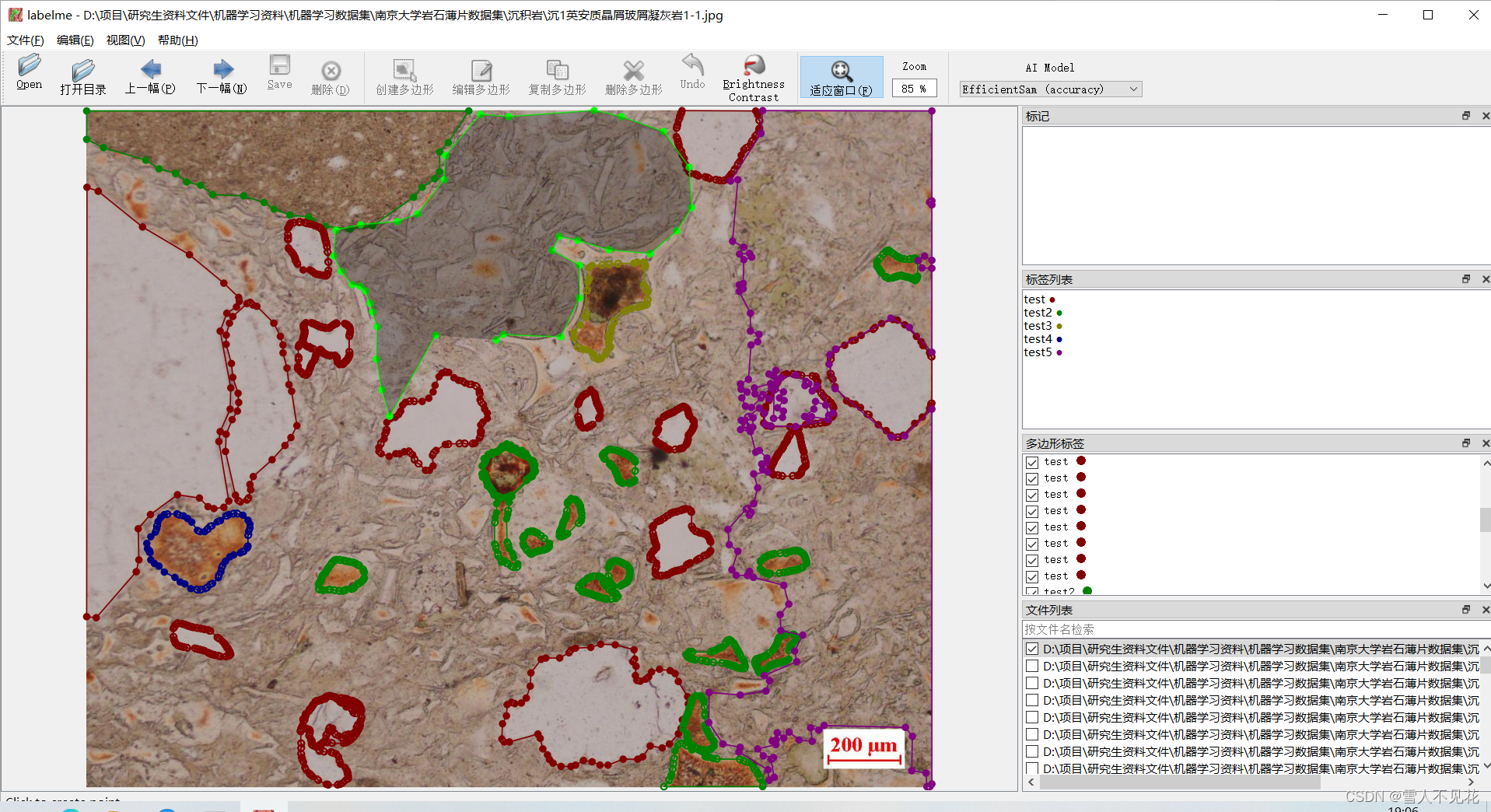
4.7 注意
1.若ai标注区域不合理,则需要人工手动调整,确保标注的准确性
2.一定要确保标注内容覆盖全图,不可以有漏标区域
5. 标注完成
本图片标注完成后,ctrl+s进行保存,之后进行下一幅图片的标注,
直到本文件夹的图片全部标注完成
图片被标注后,文件前会存在对勾。图片全部标注完成后,关闭labelme图形界面。
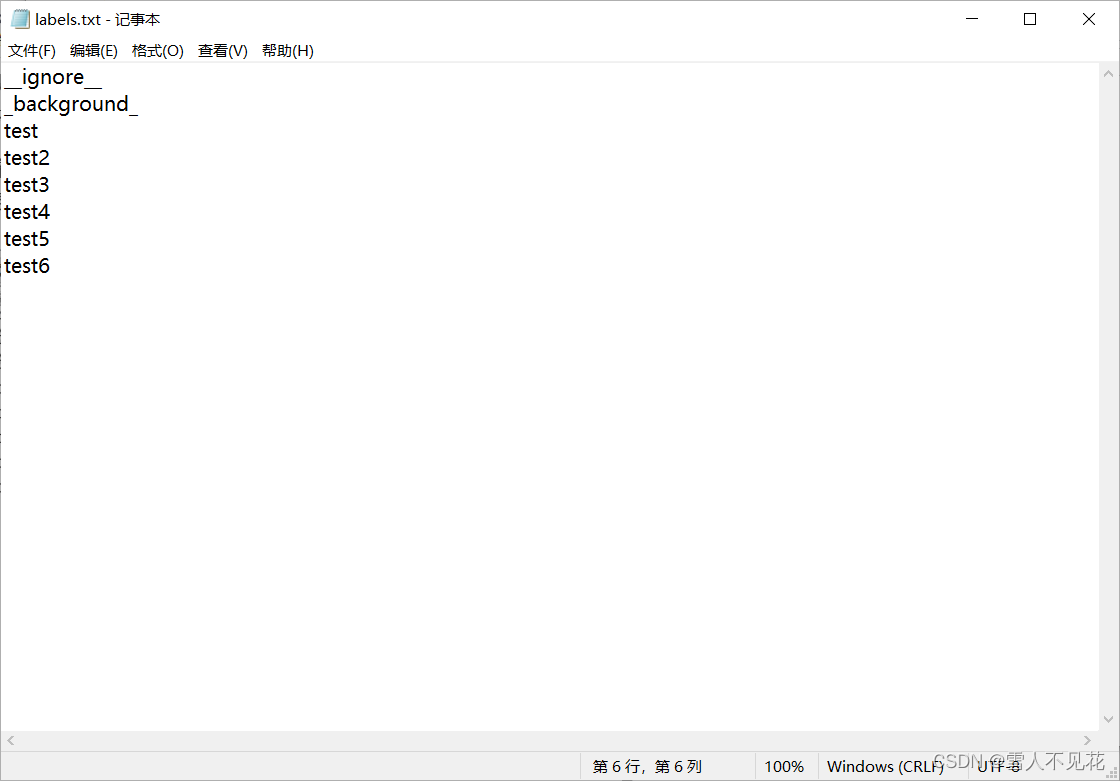
6. 修改labels.txt文件
在标注过程中,若是新加入的标签,则应该将其添加到labels.txt文件中
该txt文件为手动创建,文件存放在与标注图像文件夹同级的目录下,详见7.1
7. 将标注结果可视化
标注完成后,可以将标注结果的json文件批量转换为图像,用来作为图像标签
注意:以下命令需要根据自己的实际文件路径进行修改
7.1 首先,将python代码文件、标签名称与标注的图像文件夹放入同一级目录
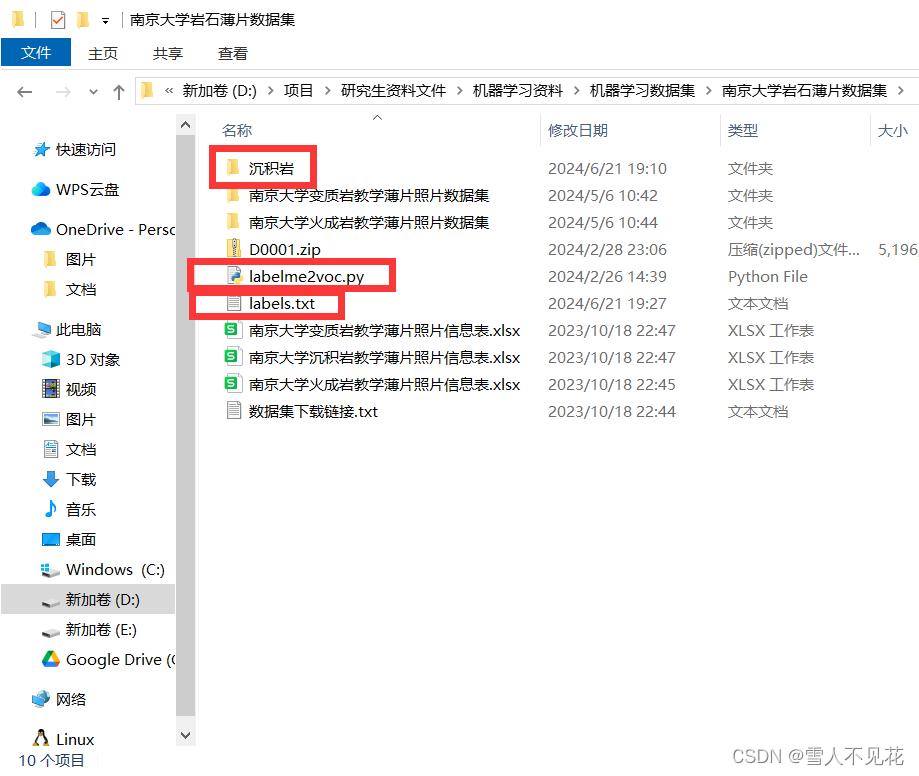
7.2 在命令行窗口进入到标注文件夹下
进入文件夹后执行转换
python labelme2voc.py images_name target_name --labels labels.txt
其中 :
images_name 是标注图片路径,即原始图片与json所在文件夹
target_name 是要将结果保存的文件夹的名称
labels.txt 是存储标签名称
此处的命令需要根据自己实际的文件路径进行修
比如我的命令是
cd D:\项目\研究生资料文件\机器学习资料\机器学习数据集\南京大学岩石薄片数据集
D:
python labelme2voc.py 沉积岩 target_name --labels labels.txt
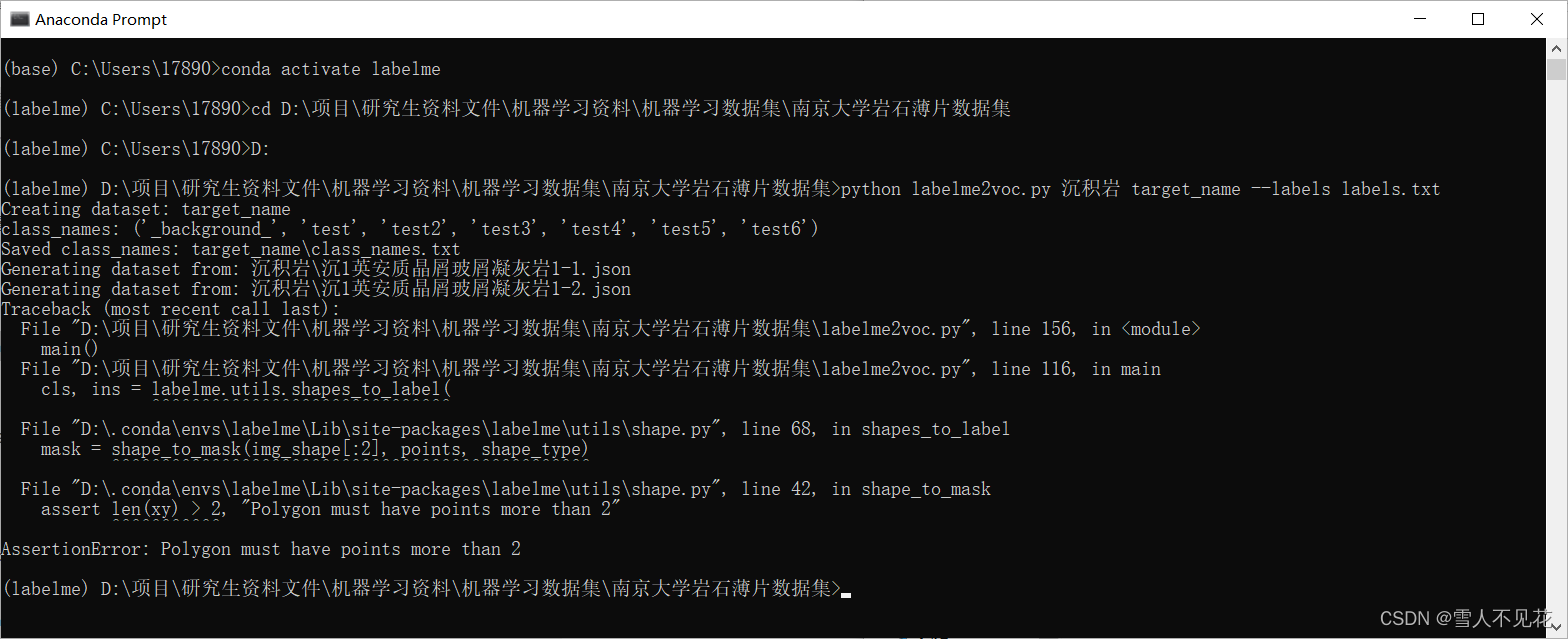
8. 完成json转图片
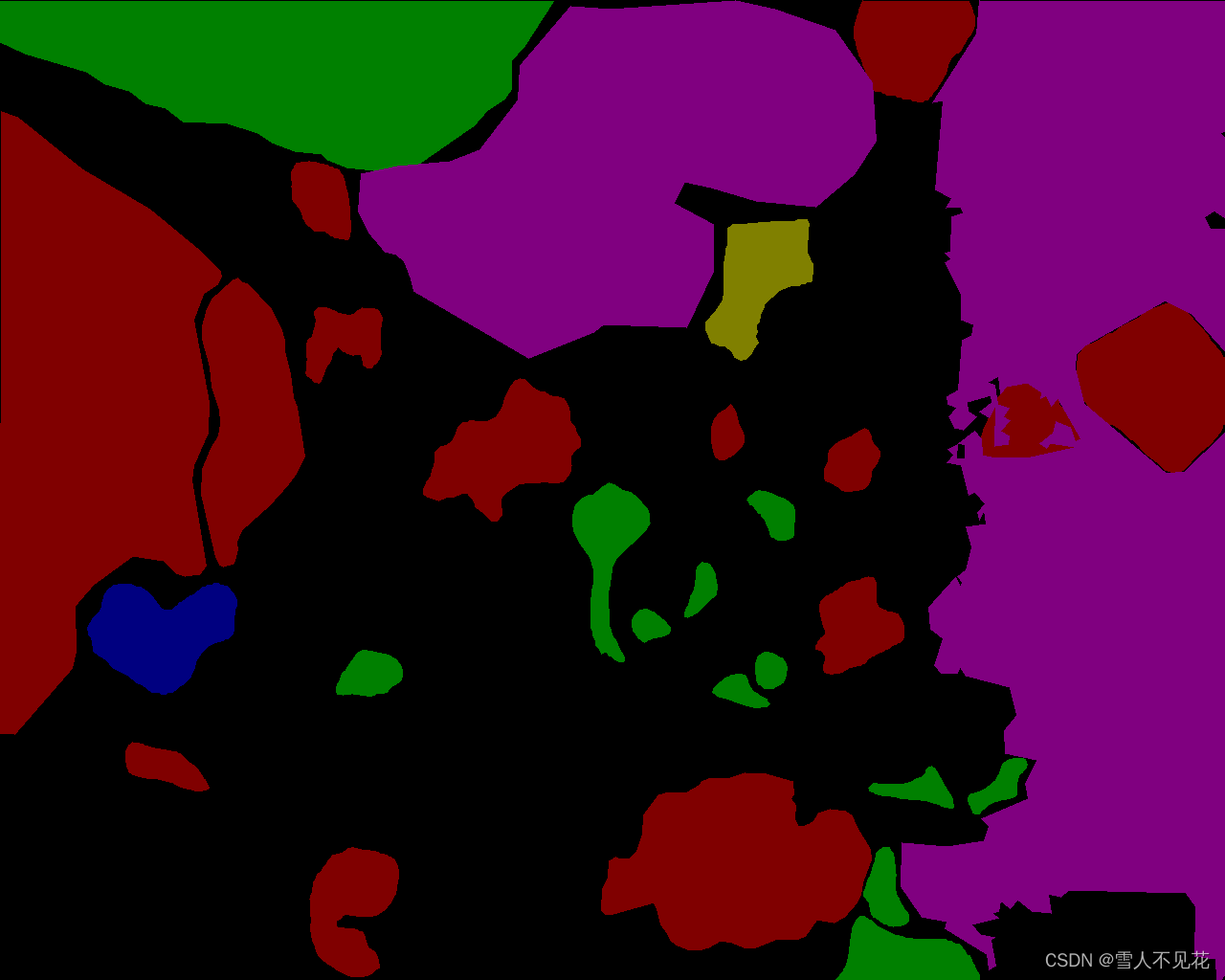
注意,下面这个例子中,标签并没有全部覆盖,说明这是一个不好的标签。
语义分割标签文件:
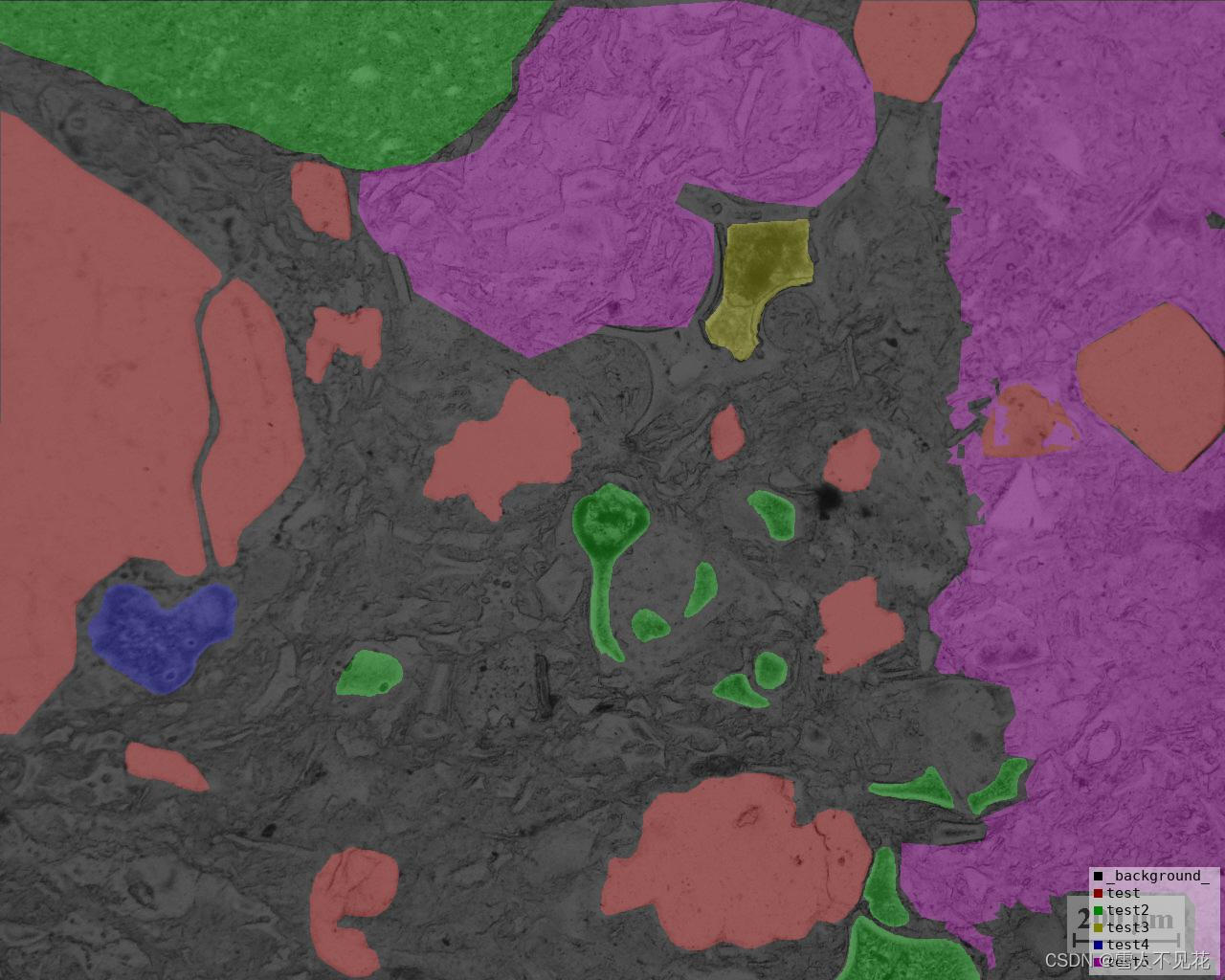
标签与原始图像展示
9. 全部命令总结
打开anaconda
conda activate labelme
labelme
#标注完成后再继续执行下列命令
cd D:\项目\研究生资料文件\机器学习资料\机器学习数据集\南京大学岩石薄片数据集
D:
python labelme2voc.py 沉积岩 target_name --labels labels.txt这篇关于labelme 标注岩石薄片数据集流程的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





