本文主要是介绍RAG实操教程langchain+Milvus向量数据库创建你的本地知识库 二,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
Miluvs 向量数据库
关于 Milvui 可以参考我的前两篇文章
- • 一篇文章带你学会向量数据库Milvus(一)[1]
- • 一篇文章带你学会向量数据库Milvus(二)[2]
下面我们安装 pymilvus 库
pip install --upgrade --quiet pymilvus
如果你使用的不是 Miluvs 数据库,那也没关系,langchain 已经给我们分装了几十种向量数据库,你选择你需要的数据库即可。本文中我们是系列教程中一篇,所以我们使用 Miluvs 向量库。
Embedding model
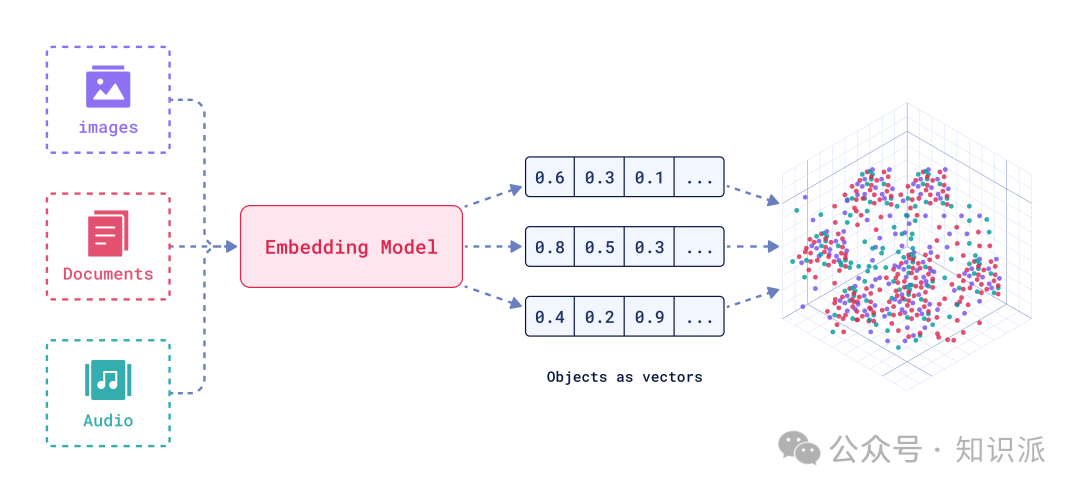
这里需要明确的两个功能是:
- •
embedding Model所做中工作就是将image、Document、Audio等信息向量化. - •
vectorBD负责保存多维向量
我这里使用 AzureOpenAIEmbeddings 是个收费的模型。有开源的 embedding Model可以部署在本地使用,如果你的机器性能足够好。如果要本地部署可以参考 docker 部署 llama2 模型 。
这里我使用 AzureOpenAIEmbeddings, 相关配置我放到了 .env 文件中,并使用 dotenv 加载。
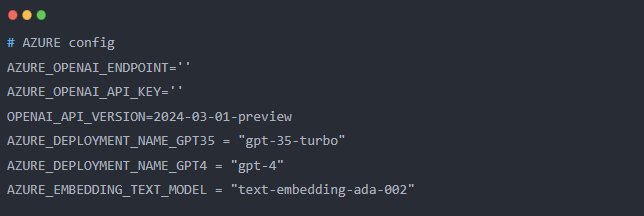
这里各位可以依据自己的情况设定即可。
向量化+存储
上面已经说明了向量库以及embedding model的关系。我们直接使用 langchain提供的工具连完成 embedding 和store。
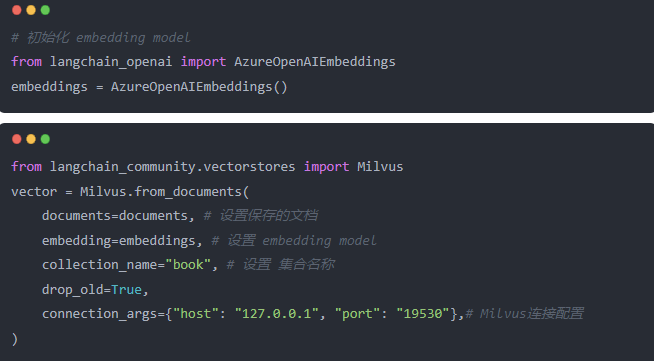
执行完成上面的代码,我们就将pdf中文档内容保存到 vector_db 中。
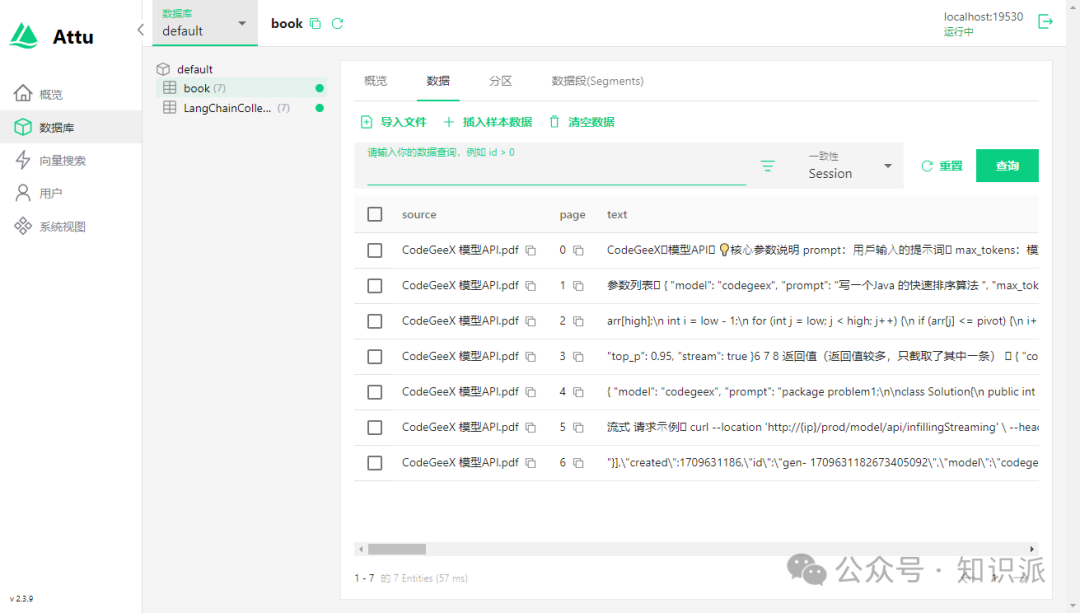
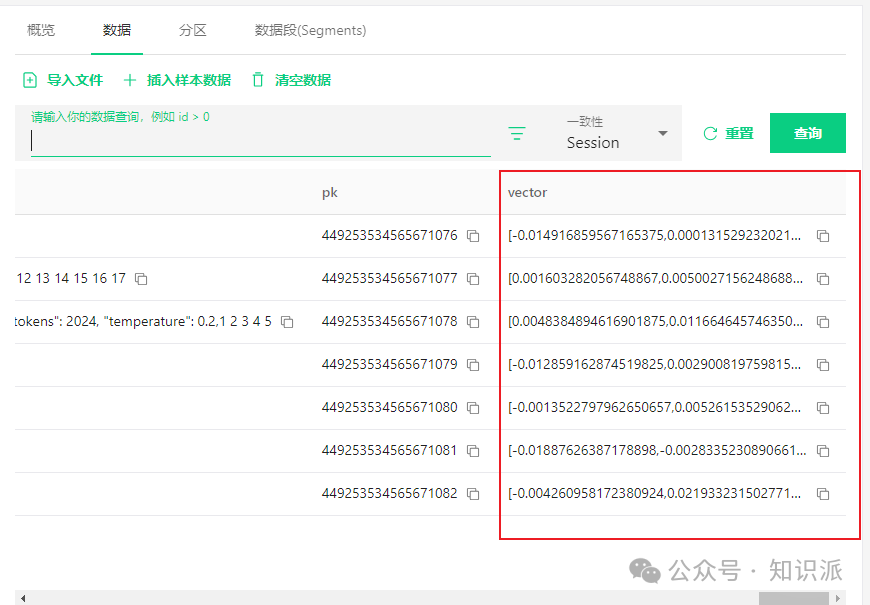
字段 vector 就是保存的多维向量。
Milvus search
虽然现在我们还没有使用 LLM 的任何能力,但是我们已经可以使用 vector 的搜索功能了。
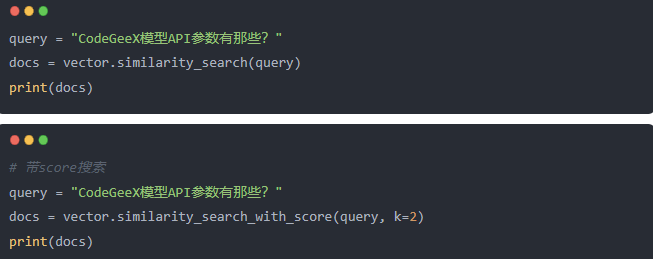
similarity_search 与 similarity_search_with_score 的区别就是 similarity_search_with_score搜索出来会带有一个 score 分值的字段,某些情况下这个 score 很有用。
langchain 不仅仅提供了基础的搜索能力,还有其他的搜索方法,感兴趣的可以去研究下。
RAG Chat
准备工作我们已经就绪,接下来我们使用langchain 构建我们的chat。
既然是聊天也就是我们跟模型的一问一答的形式来体现。这两年LLM的出现,关于 LLM 的知识里面我们估计最熟悉就是角色设定了。
- • 什么是角色设定:下面 OpenAI 给出的回答:
在大型语言模型(LLM)中,角色设定指的是为AI助手创建一个特定的人格或身份。这个设定包括AI助手的说话风格、知识领域、价值观、行为方式等各个方面。通过这些设定,AI助手可以扮演不同的角色,比如专业的客服、风趣幽默的聊天对象,或是特定领域的专家顾问。
角色设定可以让AI助手的回答更加符合特定的场景和用户的期望。比如一个扮演医生的AI助手,会用专业术语解释病情,给出严谨的建议;而一个扮演朋友的AI助手,会用轻松的语气聊天,给出生活化的提示。
此外,角色设定还可以帮助限定AI助手的行为边界,避免其做出不恰当或有害的回应。设定明确的角色定位,有助于AI助手更好地理解自己的身份和职责,从而提供更加合适和有帮助的回答。
总的来说,角色设定让AI助手的对话更加自然和人性化,让用户获得更好的使用体验。同时它也是引导AI助手行为、确保其安全可控的重要手段。
在 chat中我们同样也需要以及简单的 prompt:
template = """You are an assistant for question-answering tasks. Use the following pieces of retrieved context to answer the question. If you don't know the answer, just say that you don't know. Question: {question} Context: {context} Answer:
"""
这个prompt中很明显我们设定了两个变量 question, context。
question:这个会在后面被替换为用户的输入,也就是用户的问题。
context: 这个变量我们在后面会替换为向量检索出来的内容。
请思考下:我们最后提供给LLm的内容只是用户的问题呢还是问题连带内容一起给到LLM?
chat chain
基于上面的内容我们基本的工作已经完成,下面就是我们基于 langchain构建chat。
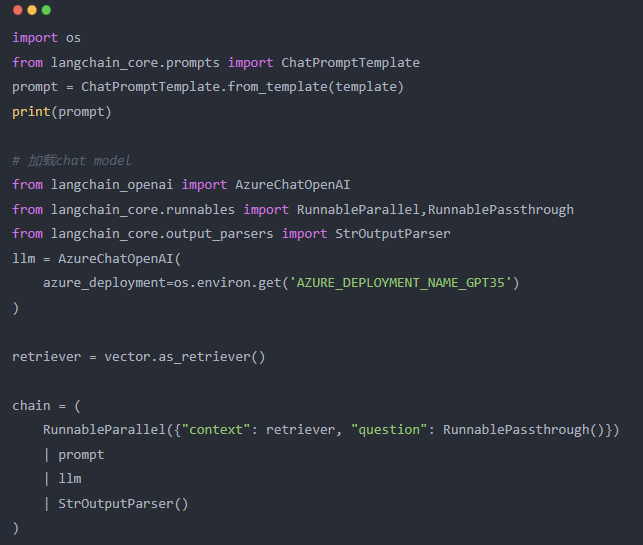
对于初学者可能有个问题就是:为什么这里有个 AzureChatOpenAI() 的实例 llm 。
这是个好问题,对于初学者会被各种 LLM 搞晕😵💫。
- •
AzureOpenAIEmbeddings()这是一个负责将文本向化话的model。 - •
AzureChatOpenAI()是一个chat模型。负责聊天的 model。
基于 langchain 的链式调用构建 chat
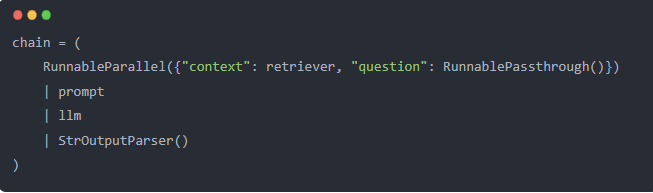
这里看到 prompt中的两个变量context, question 会被替换。
为什么我们要写变量在 prompt中?
- • 工程化:我们在做LLM相关的工作最重要的就是
prompt工程。这也是个重要的话题后面再说。 - • 灵活:
测试
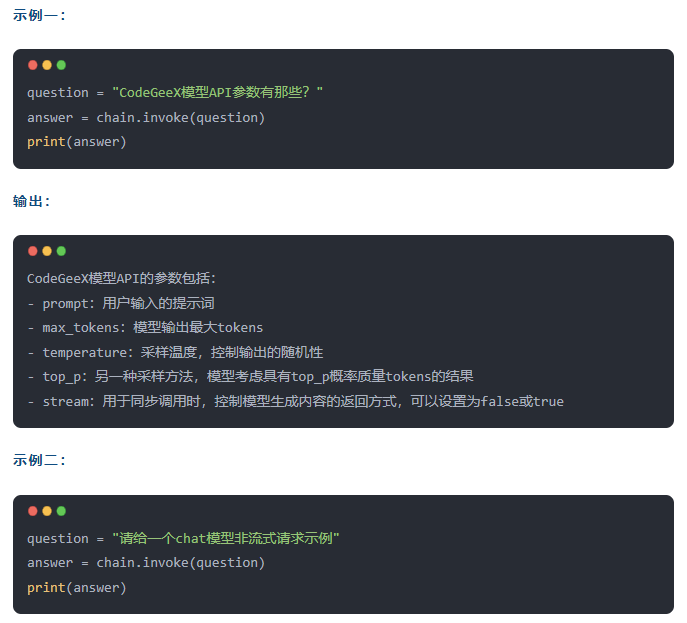
输出:
流式请求示例:
curl --location 'http://{ip}/prod/model/api/infillingStreaming' \
--header 'Content-Type: application/json' \
--data '{"model": "codegeex", "prompt": "package problem1;\nclass Solution{\n public int \nremoveDuplicates(int[] nums) {\n int cnt = 1;\n for (int i = 1; \ni < nums.length; ++i)\n if (nums[i] != nums[i - 1]) {\n \n nums[cnt] = nums[i];\n ++cnt;\n }\n return \ncnt;\n }\\n}", "max_tokens": 1024, "temperature": 0.2, "top_p": 0.95, "stream": true
}'
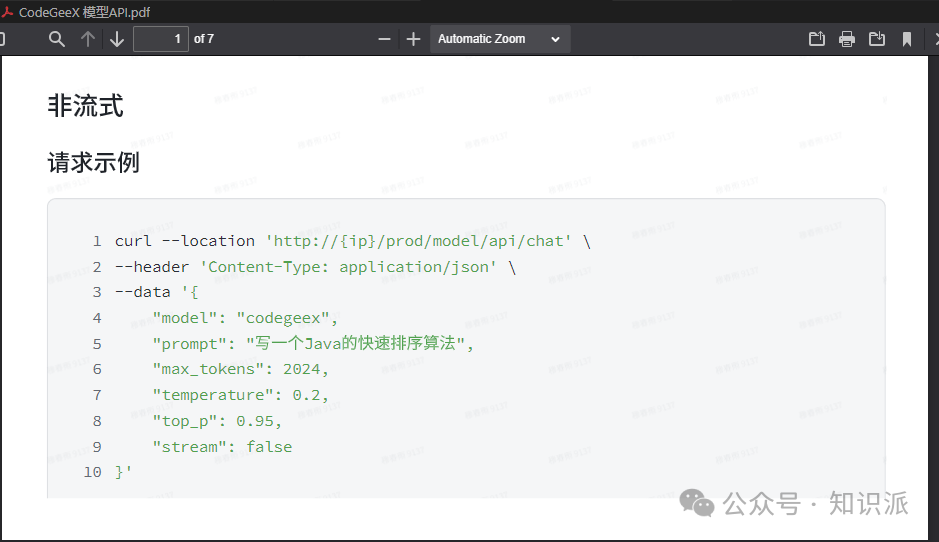
对比pdf中的内容,很明显这个结果就是对的:
总结:
本文主要是 Milvus 向量数据实战总结。
- • LLM 痛点以及解决方案
- • RAG 是什么,为什么选用RAG。
- •
langchain文档加载器,embedding model,chat model - • 文档拆分的注意点,
embedding model,chat model区别。 - • chat 示例代码。
如何学习AI大模型?
作为一名热心肠的互联网老兵,我决定把宝贵的AI知识分享给大家。 至于能学习到多少就看你的学习毅力和能力了 。我已将重要的AI大模型资料包括AI大模型入门学习思维导图、精品AI大模型学习书籍手册、视频教程、实战学习等录播视频免费分享出来。
这份完整版的大模型 AI 学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】

一、全套AGI大模型学习路线
AI大模型时代的学习之旅:从基础到前沿,掌握人工智能的核心技能!

二、640套AI大模型报告合集
这套包含640份报告的合集,涵盖了AI大模型的理论研究、技术实现、行业应用等多个方面。无论您是科研人员、工程师,还是对AI大模型感兴趣的爱好者,这套报告合集都将为您提供宝贵的信息和启示。

三、AI大模型经典PDF籍
随着人工智能技术的飞速发展,AI大模型已经成为了当今科技领域的一大热点。这些大型预训练模型,如GPT-3、BERT、XLNet等,以其强大的语言理解和生成能力,正在改变我们对人工智能的认识。 那以下这些PDF籍就是非常不错的学习资源。

四、AI大模型商业化落地方案

作为普通人,入局大模型时代需要持续学习和实践,不断提高自己的技能和认知水平,同时也需要有责任感和伦理意识,为人工智能的健康发展贡献力量。
这篇关于RAG实操教程langchain+Milvus向量数据库创建你的本地知识库 二的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






