本文主要是介绍【Gradio】如何设置 Gradio 数据框的样式,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
简介
数据可视化是数据分析和机器学习的关键方面。Gradio DataFrame 组件是一种流行的方式,在网络应用程序中显示表格数据(特别是以 pandas DataFrame 对象的形式)。
本文将探讨 Gradio 的最新增强功能,这些功能允许用户整合 pandas 的样式选项,例如为 DataFrame 组件添加颜色,或设置数字的显示精度。
让我们开始吧!
先决条件:我们将在示例中使用 gradio.Blocks 类。如果您还不熟悉它,可以先阅读 Blocks 指南。另外,请确保您使用的是 Gradio 的最新版本: pip install --upgrade gradio 。
概览
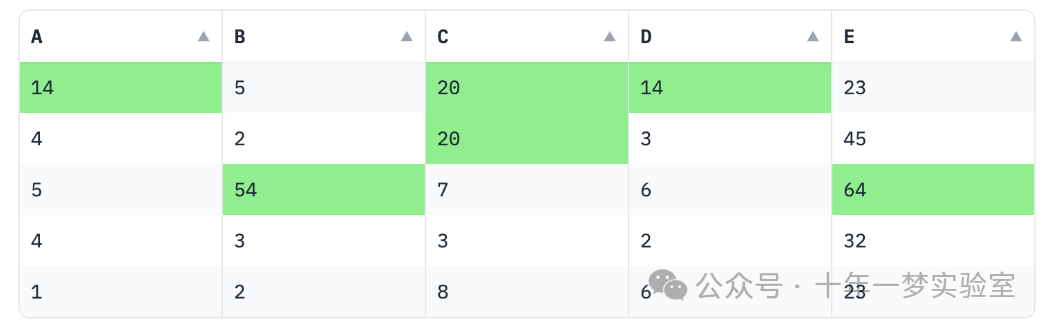
Gradio DataFrame 组件现在支持来自 pandas 类的 Styler 类型的值。这使我们能够重用 Styler 类的丰富现有 API 和文档,而不是自己发明一种新的样式格式。以下是一个完整示例的外观:
# 导入pandas和gradio库
import pandas as pd
import gradio as gr# 创建一个样本数据框
df = pd.DataFrame({"A" : [14, 4, 5, 4, 1], "B" : [5, 2, 54, 3, 2], "C" : [20, 20, 7, 3, 8], "D" : [14, 3, 6, 2, 6], "E" : [23, 45, 64, 32, 23]
}) # 使用样式对数据框进行处理,高亮每列的最大值,高亮颜色为浅绿色
styler = df.style.highlight_max(color = 'lightgreen', axis = 0)# 在Gradio交互界面上展示经过样式处理的数据框
with gr.Blocks() as demo:gr.DataFrame(styler)# 启动Gradio界面
demo.launch()Styler 类可以用来对数据框应用条件格式和样式,使它们更具视觉吸引力和可解释性。您可以突出显示某些值,应用渐变,甚至使用自定义 CSS 来样式化 DataFrame。Styler 对象应用于 DataFrame,并返回一个具有相关样式属性的新对象,然后可以直接预览,或在 Gradio 界面中动态渲染。
要了解更多关于 Styler 对象的信息,请阅读官方文档:https://pandas.pydata.org/docs/user_guide/style.html
字体颜色
除了突出显示单元格,您可能还想为单元格内的特定文本上色。以下是如何更改某些列的文本颜色:
# 导入pandas和gradio库
import pandas as pd
import gradio as gr# 创建一个样本数据框
df = pd.DataFrame({"A" : [14, 4, 5, 4, 1], "B" : [5, 2, 54, 3, 2], "C" : [20, 20, 7, 3, 8], "D" : [14, 3, 6, 2, 6], "E" : [23, 45, 64, 32, 23]
}) # 写一个函数来修改文本颜色
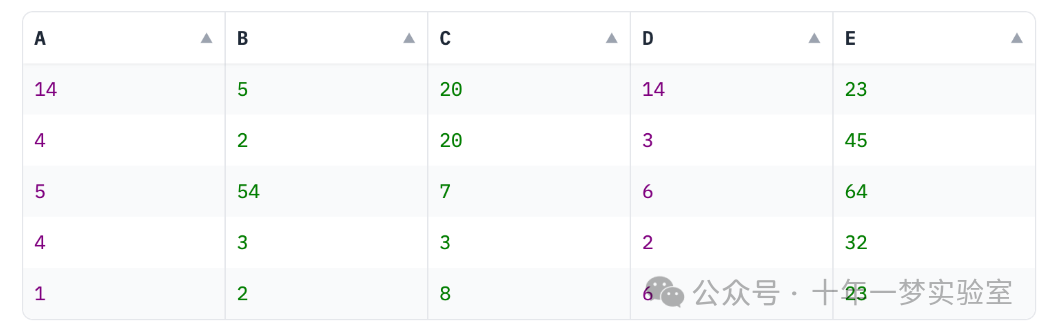
def highlight_cols(x): # 首先复制输入的数据框df = x.copy() # 将所有元素的颜色设为紫色df.loc[:, :] = 'color: purple'# 将'B', 'C', 'E'列的元素颜色设为绿色df[['B', 'C', 'E']] = 'color: green'# 返回被修改颜色的数据框return df # 应用上述颜色修改函数
s = df.style.apply(highlight_cols, axis = None)# 在Gradio交互界面上展示上述处理过的数据框
with gr.Blocks() as demo:gr.DataFrame(s)# 启动Gradio界面
demo.launch()这段代码使用Gradio UI创建了一个可交互界面,将一个处理过的Pandas DataFrame展示出来。这个处理过的DataFrame改变了列'B', 'C', 'E'的文本颜色,对于数据分析和展示来说,这种突出显示关键列的方式可以帮助分析者更好地关注和理解数据。
在这个脚本中,我们定义了一个自定义函数 highlight_cols,它将所有单元格的文本颜色更改为紫色,但对 B、C 和 E 列使用绿色进行了覆盖。它看起来是这样的:
显示精度
有时候,你处理的数据可能会有很长的浮点数,你可能只想显示固定数量的小数位数以简化显示。pandas 的 Styler 对象允许你格式化显示的数字精度。以下是如何做到这一点的方法:
# 导入pandas和gradio库
import pandas as pd
import gradio as gr# 创建一个包含浮点数的样本数据框
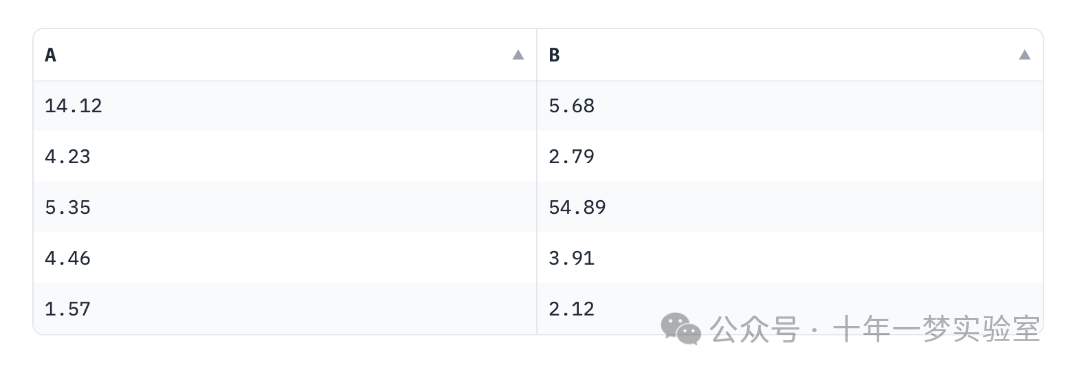
df = pd.DataFrame({"A" : [14.12345, 4.23456, 5.34567, 4.45678, 1.56789], "B" : [5.67891, 2.78912, 54.89123, 3.91234, 2.12345], # ... 其他列
}) # 将数字的精度设置为2位小数
s = df.style.format("{:.2f}")# 在Gradio交互界面中展示这个处理过的数据框
with gr.Blocks() as demo:gr.DataFrame(s)# 启动Gradio界面
demo.launch()在这个脚本中,Styler 对象的 format 方法被用来将数字的精度设置为两位小数。现在看起来清爽多了:
关于交互性的注意事项
需要记住的一点是,gradio DataFrame 组件在非交互式(即“静态”模式)时只接受 Styler 对象。如果 DataFrame 组件是交互式的,那么样式信息将被忽略,相反会显示原始表格值。
DataFrame 组件默认是非交互式的,除非它被用作事件的输入。在这种情况下,您可以通过设置 interactive 属性来强制组件为非交互式,如下所示:
c = gr.DataFrame(styler, interactive=False)结论 🎉
这只是使用 gradio.DataFrame 组件与 Styler 类来自 pandas 的可能性的一点体验。尝试一下,告诉我们你的想法!
这篇关于【Gradio】如何设置 Gradio 数据框的样式的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!




