本文主要是介绍Boosting和AdaBoost的可视化的清晰的解释,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
点击上方“AI公园”,关注公众号,选择加“星标“或“置顶”
前戏作者:Maël Fabien
编译:ronghuaiyang
可视化的方法,清楚的解释了Boosting和AdaBoost。
最近,在Kaggle竞赛和其他预测分析任务中,boosting技术正在兴起。我将尽可能清楚地解释boost和AdaBoost的概念。
在本文中,我们将讨论:
快速回顾bagging
bagging的限制
boosting的详细概念
boosting的计算效率
代码示例
I. Bagging的限制
接下来,考虑一个二元分类问题。我们要么把一个观测值归为0,要么归为1。这不是本文的目的,但是为了清晰起见,让我们回顾一下bagging的概念。
Bagging是一种代表“Bootstrap Aggregating”的技术。其实质是选取bootstrap样本,在每个样本上拟合一个分类器,并行训练模型。通常,在随机森林中,决策树是并行训练的。然后将所有分类器的结果平均成一个bagging分类器:
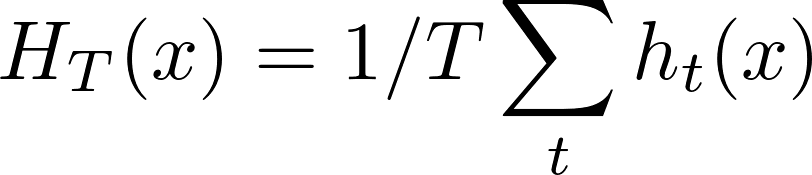
这个过程可以用下面的方法来说明。让我们考虑3个分类器,它们产生一个分类结果,可能是对的,也可能是错的。如果我们把这3个分类器的结果绘制出来,在某些区域,分类器是错误的。这些区域用红色表示。
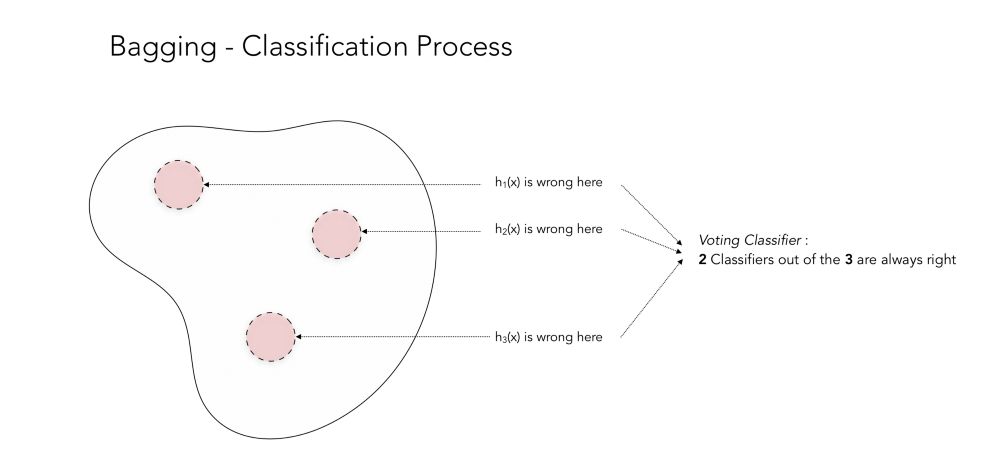
这个例子很好,因为当一个分类器是错误的,其他两个是正确的。通过投票分类器,你得到了很好的准确性!但是,正如你可能猜到的,在某些情况下,Bagging也不能正常工作,因为在相同的区域中,所有的分类器都是错误的。
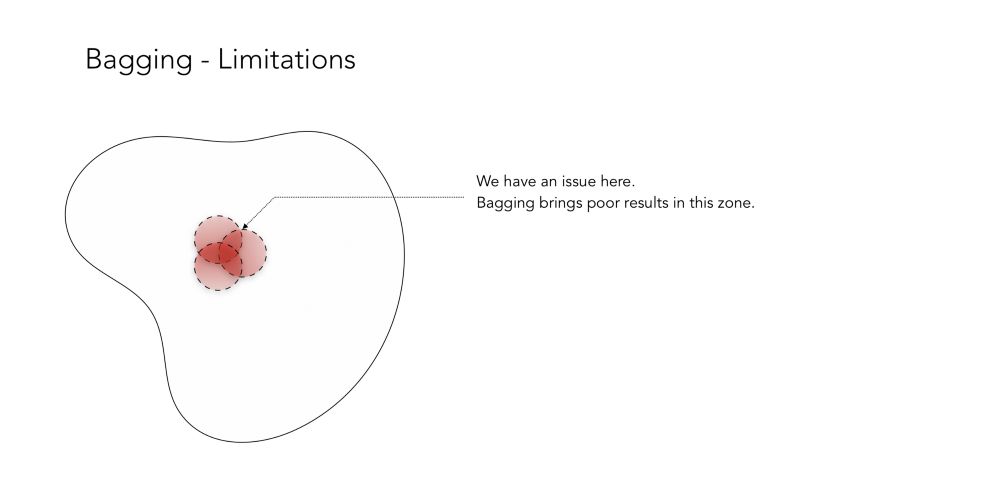
由于这个原因,Boosting背后的直觉如下:
与其训练并行模型,还不如按顺序训练模型
每个模型都应该关注前一个分类器表现不佳的地方
II. Boosting的介绍
a. 概念
上述直觉可以这样描述:
对模型h1进行整个数据集的训练
对h1表现不佳区域的数据做夸大来训练模型h2
对h1≠h2的区域的数据进行夸大来训练模型h3
...
我们不需要并行对模型进行训练,而是按顺序对它们进行训练。这就是boosting的本质!
Boosting通过随着时间的推移调整错误度量来训练一系列性能较差的算法,称为弱学习器。弱学习器的错误率略低于50%,如下图所示:

b. 对误差加权
我们如何实现这样的分类器?通过在整个迭代中对误差加权!这将给以前分类器执行得不好的区域更多的权重。
让我们考虑二维图上的数据点。有些会被很好地分类,有些则不会。通常,在计算错误率时,每个错误的权重为1/n,其中n是要分类的数据点个数。
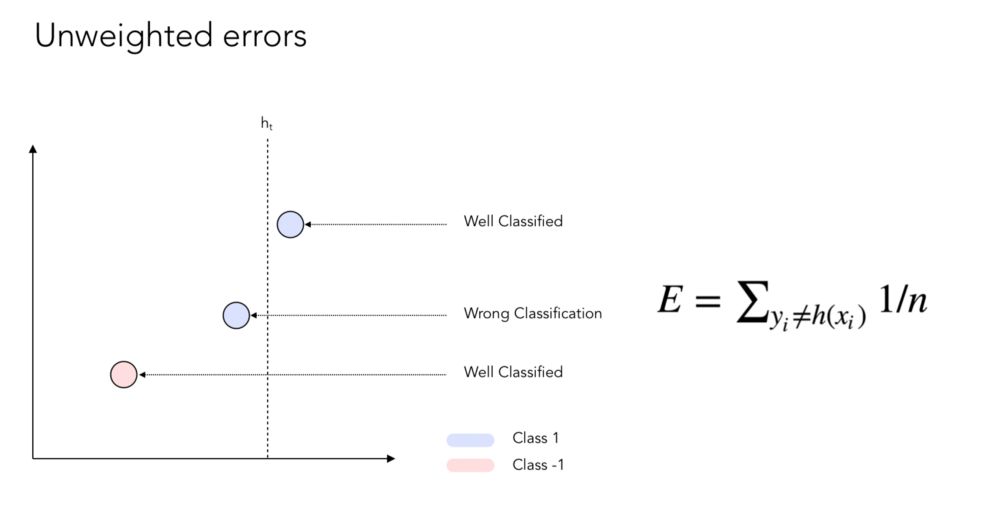
现在,如果我们对误差施加一些权重:
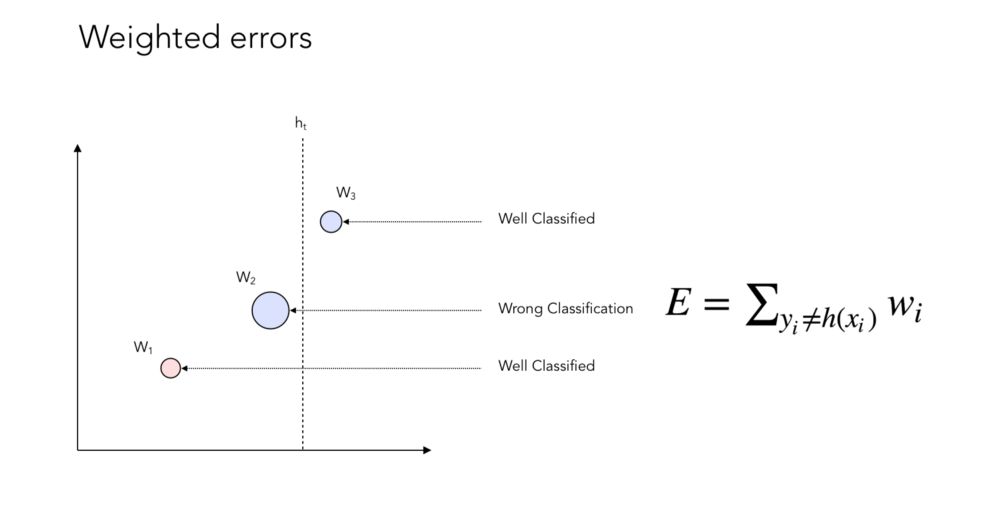
你现在可能会注意到,我们对没有很好分类的数据点给予了更多的权重。下面是加权过程的一个例子:

最后,我们希望构建一个强大的分类器,它可能是这样的:
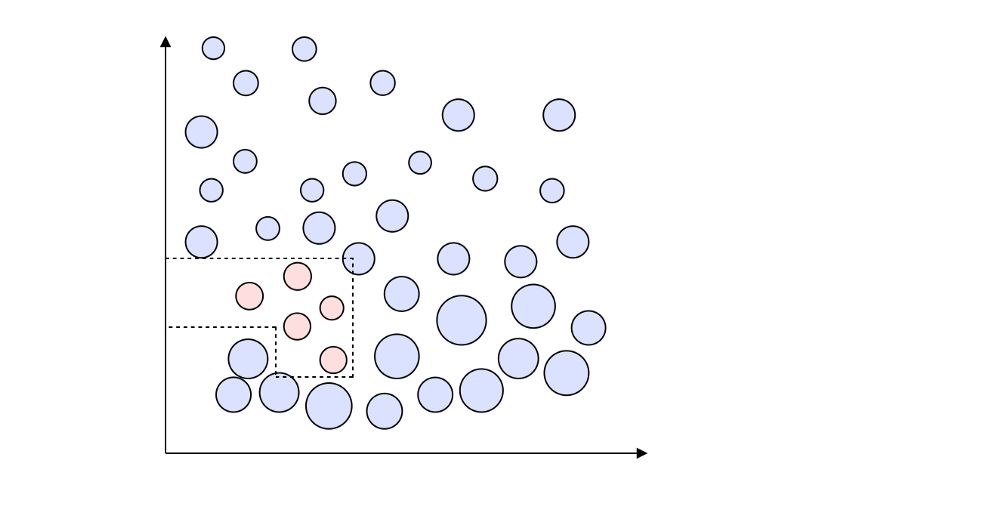
c. 树桩
你可能会问的一个问题是,一个强分类器需要实现多少个弱分类器才能正常工作?如何在每个步骤中选择每个分类器?
答案就在所谓树桩的定义中!树桩定义了一个1级决策树。主要的想法是,在每一步,我们要找到最好的树桩,也就是最好的数据分割,使整体误差最小化。你可以把树桩看作一个测试,在这个测试中,假设在一边的所有东西都属于第一类,而在另一边的所有东西都属于第0类。
树桩有很多可能的组合。让我们看看在这个简单的例子中有多少种组合?让我们花一分钟数一数。

答案是……12 !这看起来可能有点奇怪,但其实很容易理解。

我们可以做12个可能的“测试”。每条分割线边上的“2”简单地表示了这样一个事实:一边的所有点都可以是属于类0或类1的点。因此,有两个测试嵌入其中。
在每次迭代t中,我们将选择分割数据最好的弱分类器ht,最大限度地降低整体错误率。回想一下,错误率是一个经过修改的错误率版本,它考虑到了前面介绍的内容。
d. 寻找最优分割
如上所述,在每个迭代t中,通过识别最佳弱分类器ht,通常是一棵有1个节点和2个叶子(一个树桩)的决策树,找到最佳分割。假设我们试图预测一个想借钱的人是以后会不会还钱:
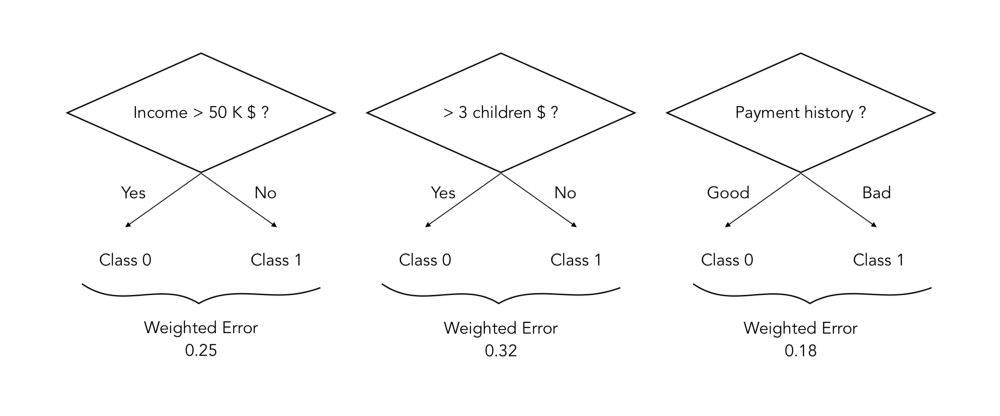
在这种情况下,t时刻的最佳分割是在Payment history的树桩,因为这种分割的加权误差是最小的。
需要注意,在实践中,像这样的决策树分类器可以比简单的树桩更深入。这将是一个超参数。
e. 分类器组合
下一个逻辑步骤是将分类器组合成符号分类器,根据一个点将站在边界的哪一侧,它将被分类为0或1。可以这样实现:
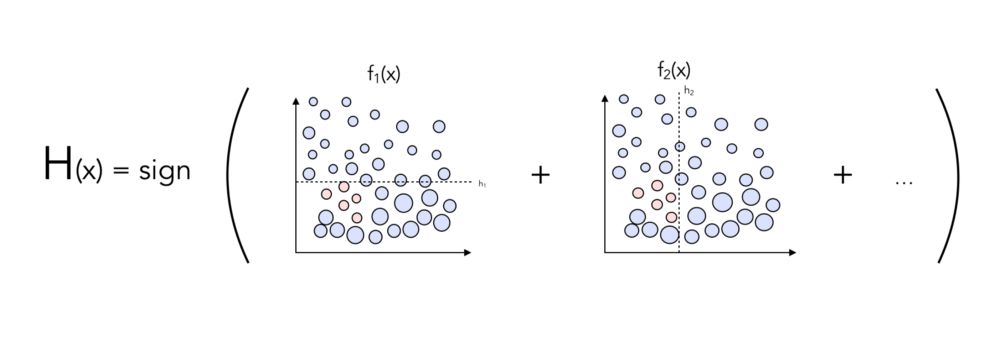
你认为有什么方法可以潜在地改进分类器吗?
通过在每个分类器上添加权重,避免对不同的分类器赋予相同的重要性。
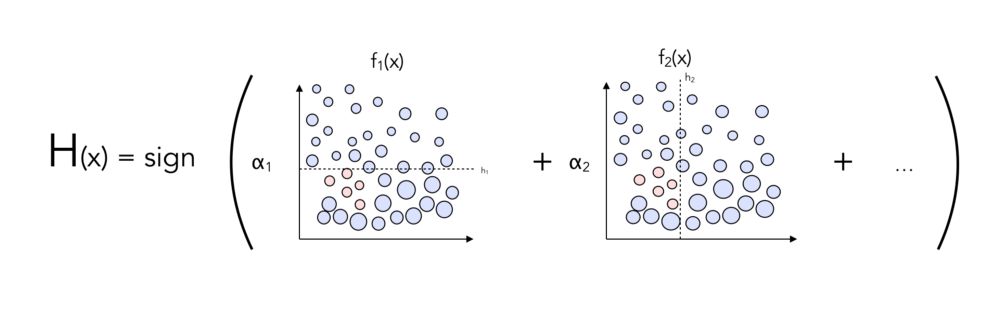
f. 把上面的内容打个包
让我们用一个到目前为止已经介绍过的伪代码来总结一下。

要记住的关键因素是:
Z是一个常数,它的作用是使权值标准化,使它们加起来等于1 !
αt是权值,我们给每个分类器都分配一个权值
做完了!这个算法叫做AdaBoost。这是需要理解的最重要的算法,以便充分理解所有的boosting方法。
III. 计算
Boosting算法训练起来相当快,这很好。但是既然我们考虑了所有可能的残差并且递归地计算指数,为什么训练起来这么快呢?
这就是神奇之处。如果我们选择正确αt和Z,每一步权重的变化可以简化为:

这是一个非常有力的结果,它与权重应该随迭代变化的说法并不矛盾,因为分类不好的训练样本的数量下降了,而它们的总权重仍然是0.5 !
不需要计算Z
没有α
没有指数
还有另一个技巧:任何试图分割两个分类良好的数据点的分类器都不会是最优的。甚至不需要计算它。
IV. 开始编程!
现在,我们将通过一个简单的手写数字识别示例快速了解如何在Python中使用AdaBoost。
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
from sklearn.ensemble import AdaBoostClassifier
from sklearn.tree import DecisionTreeClassifier
from sklearn.metrics import accuracy_score
from sklearn.model_selection import cross_val_score
from sklearn.model_selection import cross_val_predict
from sklearn.model_selection import train_test_split
from sklearn.model_selection import learning_curve
from sklearn.datasets import load_digits我们现在加载数据:
dataset = load_digits()
X = dataset['data']
y = dataset['target']X为长度为64的数组,这些数组只是拉平的8x8图像。该数据集的目的是识别手写数字。让我们来看看一个给定的手写数字:
plt.imshow(X[4].reshape(8,8))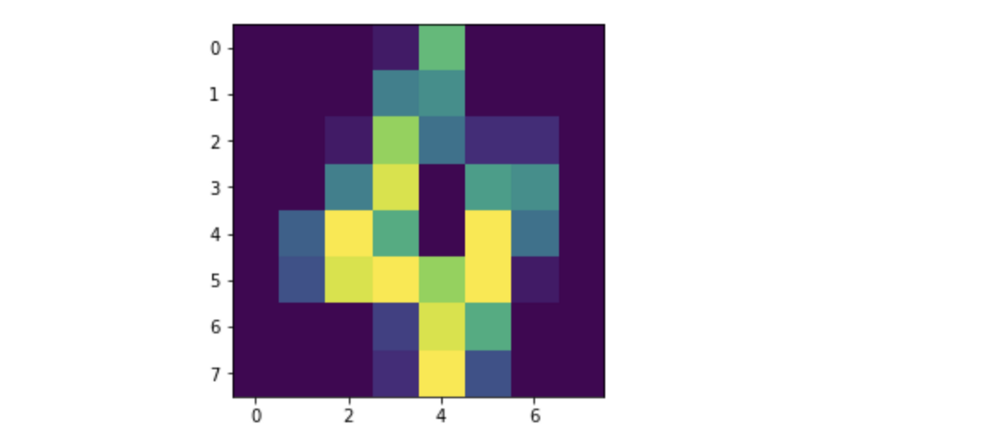
如果我们坚持使用深度为1(树桩)的决策树分类器,下面是如何实现AdaBoost分类器:
reg_ada = AdaBoostClassifier(DecisionTreeClassifier(max_depth=1))
scores_ada = cross_val_score(reg_ada, X, y, cv=6)
scores_ada.mean()而且应该达到26%左右,这在很大程度上是可以改善的。其中一个关键参数是序列决策树分类器的深度。决策树的深度如何提高精度?
score = []
for depth in [1,2,10] : reg_ada = AdaBoostClassifier(DecisionTreeClassifier(max_depth=depth)) scores_ada = cross_val_score(reg_ada, X, y, cv=6) score.append(scores_ada.mean())在这个简单的例子中,深度为10时,得分最高,准确率为95.8%。
IV. 总结
人们已经讨论过 AdaBoost 是否会过拟合。最近,它被证明在某些时候会过拟合,人们应该意识到这一点。AdaBoost也可以作为一种回归算法使用。
AdaBoost在人脸检测中被广泛用于评估视频中是否有人脸。我将很快就这个话题再写一篇文章!在以后的文章中,我们还将介绍梯度增强:)
 — END—
— END— 英文原文:https://towardsdatascience.com/boosting-and-adaboost-clearly-explained-856e21152d3e

请长按或扫描二维码关注本公众号
喜欢的话,请给我个好看吧!![]()
这篇关于Boosting和AdaBoost的可视化的清晰的解释的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!




