本文主要是介绍HAC-TextRank算法进行关键语句提取,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
AI应用开发相关目录
本专栏包括AI应用开发相关内容分享,包括不限于AI算法部署实施细节、AI应用后端分析服务相关概念及开发技巧、AI应用后端应用服务相关概念及开发技巧、AI应用前端实现路径及开发技巧
适用于具备一定算法及Python使用基础的人群
- AI应用开发流程概述
- Visual Studio Code及Remote Development插件远程开发
- git开源项目的一些问题及镜像解决办法
- python实现UDP报文通信
- python实现日志生成及定期清理
- Linux终端命令Screen常见用法
- python实现redis数据存储
- python字符串转字典
- python实现文本向量化及文本相似度计算
- python对MySQL数据的常见使用
- 一文总结python的异常数据处理示例
- 基于selenium和bs4的通用数据采集技术(附代码)
- 基于python的知识图谱技术
- 一文理清python学习路径
- Linux、Git、Docker常用指令
- linux和windows系统下的python环境迁移
- linux下python服务定时(自)启动
- windows下基于python语言的TTS开发
- python opencv实现图像分割
- python使用API实现word文档翻译
- yolo-world:”目标检测届大模型“
- 爬虫进阶:多线程爬虫
- python使用modbustcp协议与PLC进行简单通信
- ChatTTS:开源语音合成项目
- sqlite性能考量及使用(附可视化操作软件)
- 拓扑数据的关键点识别算法
- python脚本将视频抽帧为图像数据集
- 图文RAG组件:360LayoutAnalysis中文论文及研报图像分析
- Ubuntu服务器的GitLab部署
- 无痛接入图像生成风格迁移能力:GAN生成对抗网络
- 一文理清OCR的前世今生
- labelme使用笔记
- HAC-TextRank算法进行关键语句提取
文章目录
- AI应用开发相关目录
- 简介
- 技术细节
简介
该算法是我研究生毕业设计的一个创新点,在当时背景下是很好的研究成果,但随着大模型的推出,传统的NLP研究创新基本被革新了。这里分享出来是因为该创新的有一定的启发思路,希望在今后大模型或其他AI领域的开发中有开发者能用到。
TextRank算法是一种基于图排序的文本挖掘算法,主要用于文本摘要和关键词提取。它是基于PageRank算法的原理,通过将文本内容构建成一个图模型,然后利用图的节点之间的连接关系来计算每个节点的权重,进而提取出重要的句子或关键词。
TextRank算法的主要步骤如下:
- 分词和预处理:将文本进行分词处理,去除停用词,得到一系列的单词或短语。
- 构建图模型:根据文本内容构建一个图模型,其中节点代表单词或短语,边代表单词或短语之间的关联关系。通常,这种关联关系可以通过共现关系(即两个单词在一定的窗口大小内共同出现)来定义。
- 计算节点权重:使用TextRank算法迭代计算图中每个节点的权重,权重高的节点代表其在文本中的重要程度也高。
- 选择重要节点:根据节点的权重,选择权重最高的句子或关键词作为文本摘要或关键词。
TextRank算法的一个优点是它不依赖于外部知识库或预先训练的模型,可以适用于多种语言和领域。然而,它也有局限性,例如,它无法理解单词的深层含义,也无法捕捉到长距离的语义关系。
总体来说,TextRank是一种简单有效的文本挖掘算法,广泛应用于自然语言处理领域。
HAC-TextRank 算法通过预先聚类操作解决了语义相近语句被重复提取的问题,降低了信息提取过程中数据特征的混乱程度,且对于不同文本其提取结果由聚类评估指标确定提取信息数目,增强了算法对具体数据的针对性。此外,相较于传统算法,HAC-TextRank算法在面对长篇幅文本时,其计算量由乘性转为加性,可通过对数个小邻接矩阵的计算替代巨型邻接矩阵计算,其执行效率大幅提高。
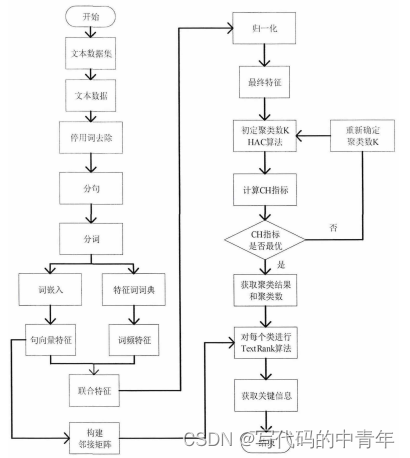

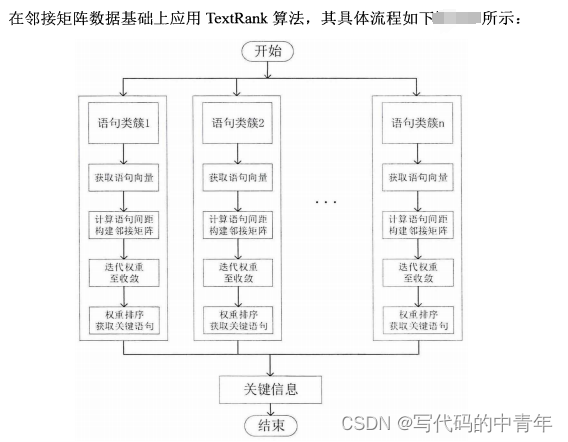
技术细节
当年源码已经找不到了,现在分步骤给出示例吧。
HAC:
import numpy as np
from sklearn.cluster import AgglomerativeClustering
from sklearn.datasets import make_blobs
from scipy.cluster.hierarchy import dendrogram, linkage
import matplotlib.pyplot as plt# 生成模拟数据
X, y = make_blobs(n_samples=300, centers=4, cluster_std=0.60, random_state=0)# 使用AgglomerativeClustering进行层次聚类
# affinity='euclidean' 表示使用欧氏距离作为相似度度量
# linkage='ward' 表示使用Ward方法作为链接准则
# distance_threshold=0 表示根据距离阈值来停止合并,这里需要根据实际情况调整阈值
cluster = AgglomerativeClustering(linkage='ward', affinity='euclidean', distance_threshold=0, n_clusters=None)# 拟合数据
cluster.fit(X)# 使用scipy的linkage函数来计算簇之间的链接
# 这里使用和AgglomerativeClustering中相同的链接准则和距离度量
Z = linkage(X, 'ward')# 绘制树状图
plt.figure(figsize=(10, 5))
dendrogram(Z, labels=cluster.labels_, leaf_rotation=90)
plt.title("Hierarchical Clustering Dendrogram")
plt.xlabel("Data point index")
plt.ylabel("Distance")
plt.show()
TextRank:
from sentence_transformers.util import cos_sim
from sentence_transformers import SentenceTransformer as SBertimport numpy as np
from scipy.spatial.distance import cosine
from sklearn.metrics.pairwise import cosine_similaritymodel = SBert(r"C:\Users\12258\Desktop\hy-zwllm\evaluate\paraphrase-multilingual-MiniLM-L12-v2")
print('paraphrase-multilingual-MiniLM-L12-v2','load success.')sentences = ['Qwen-VL 是阿里云研发的大规模视觉语言模型','Qwen-VL 可以以图像、文本、检测框作为输入,并以文本和检测框作为输出','Qwen-VL 系列模型的特点包括:多语言对话模型:天然支持英文、中文等多语言对话,端到端支持图片里中英双语的长文本识别;多图交错对话:支持多图输入和比较,指定图片问答,多图文学创作等','开放域目标定位:通过中文开放域语言表达进行检测框标注;细粒度识别和理解:448分辨率可以提升细粒度的文字识别、文档问答和检测框标注。']
embeddings = [model.encode(sentence) for sentence in sentences]# 将句向量列表转换为numpy数组
sentence_vectors = np.array(embeddings)# 使用余弦相似度计算邻接矩阵
# cosine_similarity会返回一个矩阵,其中每个元素(i, j)表示第i个句向量和第j个句向量之间的余弦相似度
adjacency_matrix = 1 - cosine_similarity(sentence_vectors)def pagerank(M, num_iterations: int = 100, d: float = 0.85):"""PageRank算法实现参数:M -- 转移概率矩阵num_iterations -- 迭代次数d -- 阻尼系数,通常设为0.85返回:R -- PageRank值"""# 节点数量N = M.shape[1]# 初始化PageRank值,设为均匀分布R = np.ones(N) / N# 创建阻尼矩阵M_hat = (d * M + (1 - d) / N)# 迭代计算PageRankfor i in range(num_iterations):R = M_hat @ Rreturn Rif __name__ == "__main__":# 示例的链接矩阵,这里非常简单,实际情况会更复杂M = np.array(adjacency_matrix)# 计算PageRankR = pagerank(M)# 输出结果print("PageRank值:", R)
输出:
PageRank值:
[2.45610080e+09 2.00254951e+09 1.99260292e+09 2.06282920e+09]
模型认为首句更为关键。
这篇关于HAC-TextRank算法进行关键语句提取的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!




