本文主要是介绍MPI并行计算关键点讲解及使用入门,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
MPI(Message Passing Interface)是并行计算领域的一个关键标准,它定义了一套用于在多个计算节点间进行高效消息传递和数据交换的通信协议和库。在高性能计算(HPC)领域,MPI尤为重要,特别是在处理大规模科学计算、模拟和数据分析等复杂任务时。
MPI关键点讲解
-
分布式内存模型
MPI基于分布式内存模型,每个计算节点(可能是独立的计算机或处理器)拥有其独立的内存空间。通过消息传递,节点间能够进行有效的通信和协作,这与共享内存模型形成了鲜明对比。 -
灵活的通信机制
MPI提供了一系列通信原语,包括点对点通信(如发送和接收消息)、集合通信(如广播、散射、聚集等)以及同步操作等。这些原语赋予程序员对数据传输和处理顺序的精确控制,从而确保并行程序的正确性和高效性。 -
进程管理
MPI程序由多个并发执行的进程组成,这些进程可以在不同的计算节点上运行。MPI库为这些进程提供了创建、销毁、同步和通信的管理机制,确保整个程序能够协调一致地运行。 -
基于消息传递的编程模型
MPI编程模型基于消息传递机制,通常使用C、C++或Fortran等语言进行编写。程序员需要显式地定义并行任务、消息传递操作和进程间的同步。 -
性能优化
在大规模并行计算中,MPI程序的性能优化至关重要。这包括减少通信开销、合理设计并行算法、选择合适的数据分布方式以及充分利用硬件特性(如多核处理器、高速网络等)。 -
强大的调试和分析工具
面对MPI程序的复杂性,强大的调试和性能分析工具是必不可少的。常见的工具包括MPI调试器(如TotalView、DDT)、性能分析工具(如Scalasca、TAU)以及集群管理和监控工具(如Slurm、Ganglia)等。 -
出色的扩展性和容错性
MPI支持在大规模集群中扩展,能够高效利用数千甚至数百万个计算节点。同时,MPI库还提供了一定的容错机制,确保程序在硬件故障或通信错误面前能够保持稳定运行或进行恢复。
MPI不仅在科学计算领域有着广泛的应用,还逐渐在工业界和学术界的大数据分析、机器学习模型训练等领域展现出了其强大的并行计算能力和灵活性。
嵌入式Linux如何应用MPI
在Linux系统上,有多种MPI软件包可供选择,它们均实现了MPI标准并提供了丰富的功能和性能优化。以望获实时Linux系统为例,我们推荐使用MPICH。
1.MPICH简介
MPICH是一个开源的、高性能的MPI实现,专注于可移植性和性能优化。它支持多种操作系统和架构,包括Linux、Windows、Mac OS X等,并支持多种通信库。MPICH提供了丰富的API和工具,适用于各种规模的并行计算任务。
这些MPI软件包都提供了丰富的功能和工具,以便开发和优化大规模并行应用程序。选择合适的MPI实现通常取决于你的硬件环境、应用程序的特性以及性能需求。在Linux环境下,这些MPI软件包通常可以通过发行版的软件仓库或官方网站下载和安装。
2. 在望获实时Linux系统上安装MPICH
dnf install mpich -y
dnf install mpich-dev -y
执行 mpichversion 查看版本

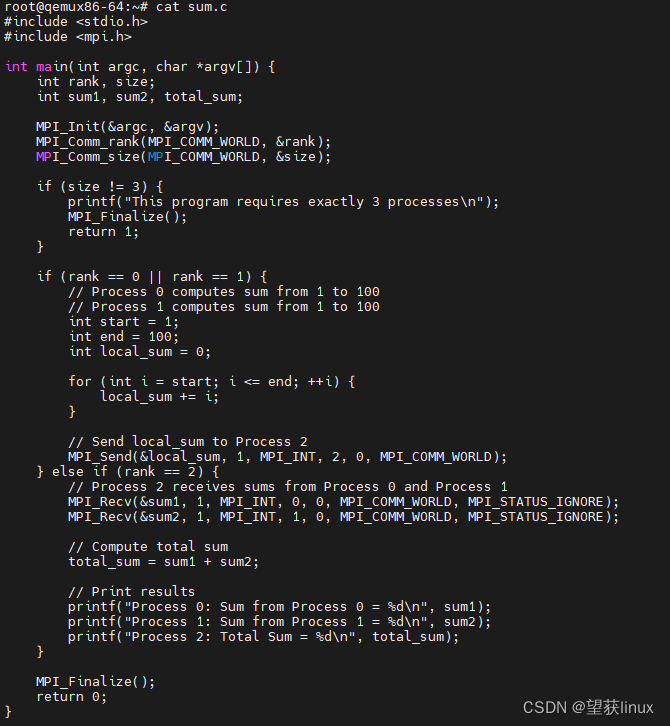
3. 一个并行计算的例子
假设有一个简单的任务:将两个范围(0到100)的数字相加,并将结果汇总。我们可以使用三个进程来完成这个任务:两个进程分别计算各自范围内的和,第三个进程则负责接收这两个和并将它们相加。
代码示例(sum_mpi.c)
#include <stdio.h>
#include <mpi.h>
int main(int argc, char *argv[]) {
int rank, size;
int sum1, sum2, total_sum;
MPI_Init(&argc, &argv);
MPI_Comm_rank(MPI_COMM_WORLD, &rank);
MPI_Comm_size(MPI_COMM_WORLD, &size);
if (size != 3) {
printf("This program requires exactly 3 processes\n");
MPI_Finalize();
return 1;
}
if (rank == 0 || rank == 1) {
// Process 0 computes sum from 1 to 100
// Process 1 computes sum from 1 to 100
int start = 1;
int end = 100;
int local_sum = 0;
for (int i = start; i <= end; ++i) {
local_sum += i;
}
// Send local_sum to Process 2
MPI_Send(&local_sum, 1, MPI_INT, 2, 0, MPI_COMM_WORLD);
} else if (rank == 2) {
// Process 2 receives sums from Process 0 and Process 1
MPI_Recv(&sum1, 1, MPI_INT, 0, 0, MPI_COMM_WORLD, MPI_STATUS_IGNORE);
MPI_Recv(&sum2, 1, MPI_INT, 1, 0, MPI_COMM_WORLD, MPI_STATUS_IGNORE);
// Compute total sum
total_sum = sum1 + sum2;
// Print results
printf("Process 0: Sum from Process 0 = %d\n", sum1);
printf("Process 1: Sum from Process 1 = %d\n", sum2);
printf("Process 2: Total Sum = %d\n", total_sum);
}
MPI_Finalize();
return 0;
}
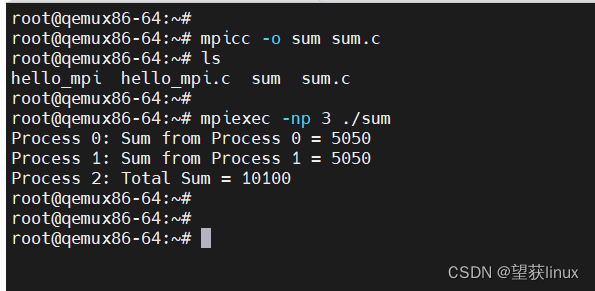
编译和运行:
mpicc -o sum_mpi sum_mpi.c
mpiexec -np 3 ./sum_mpi
输出结果:
Process 0: Sum from Process 0 = 5050
Process 1: Sum from Process 1 = 5050
Process 2: Total Sum = 10100
这篇关于MPI并行计算关键点讲解及使用入门的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






