本文主要是介绍MySQL limit子句用法及优化(Limit Clause Optimization),希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
在MySQL中,如果只想获取select查询结果的一部分,可以使用limit子句来限制返回记录的数量,limit在获取到满足条件的数据量时即会立刻终止SQL的执行。相比于返回所有数据然后丢弃一部分,执行效率会更高。
文章目录
- 一、limit子句用法示例
- 1.1 基本用法
- 1.2 limit和order by
- 1.2.1 排序瓶颈优化
- 二、limit分页优化
- 2.1 延迟关联
- 2.2 转换为位置查询
- 2.3 记录偏移位置
一、limit子句用法示例
limit子句通常放在select查询的最后,语法是limit [offset,] rowcount :
- limit m,n 返回偏移量为m之后的n条数据,即先获取m+n条记录,然后丢弃前面的m条,返回之后的n条记录
- limit n 返回开头的n条数据,相当于limit 0, n
1.1 基本用法
新建一张测试表并填充几条数据:
create table test(
id int auto_increment primary key,
name varchar(32),
salary decimal(10,2));insert into test values(null, 'aaa',1000),(null, 'bbb',2000),(null, 'ccc',3000),(null, 'ddd',4000),(null, 'eee',5000),(null, 'fff',6000),(null, 'ggg',7000),(null, 'hhh',8000),(null, 'iii',9000);
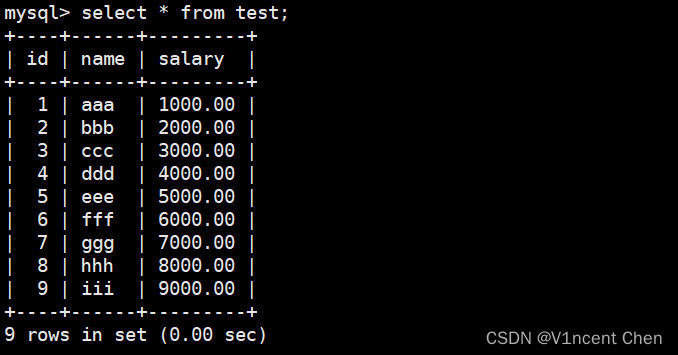
limit 0会立刻返回一个空结果集,它通常用来检测SQL语法是否正确或者快速获取结果集的字段属性。limit n用来返回最先获取的n条记录,找到足够的记录时SQL就会停止执行并返回结果:
select * from test limit 3;
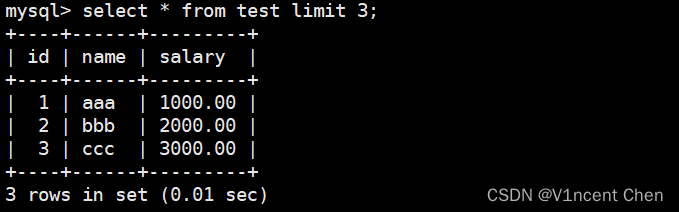
采用limit m,n的形式,就是跳过前面的m条记录,返回之后的n条记录:
select * from test limit 3,3;
如果只是想跳过开头的m条记录,只需要给n一个足够大的数字即可,例如跳过开头100条记录:limit 100, 9999999999
1.2 limit和order by
如果order by子句和limit子句同时出现,那么MySQL会先对结果进行排序,对排序后的结果集应用limit子句。例如查询工资最高的3个人(按salary列倒序排列后取前3条记录):
select * from test order by salary desc limit 3;
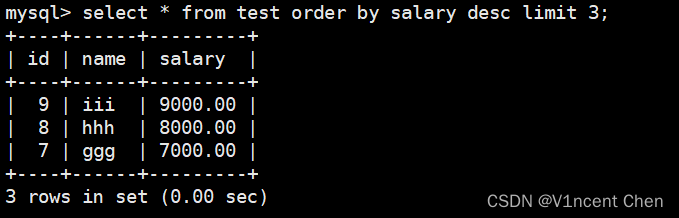
如果排序的列存在重复数据,例如本例返回3条数据,但是3,4,5条记录的salary列都是相同的(它们都可以排在第三),这时返回的结果集是不确定的,查询时需注意。
1.2.1 排序瓶颈优化
与order by子句配合使用时,虽然limit子句最终获取的结果集可能很小,但需要先对所有的数据进行排序,如果这个数据量很大,那么排序操作就会成为性能瓶颈。
如果你发现limit子句加上order by之后语句执行很慢,可以尝试通过在排序列上增加索引来消除这个排序操作。由于示例表很小,优化器倾向于走全表扫描,这里找一张更大的表test1来演示,表中约有2万多条数据。观察添加索引前后的执行计划:
explain select * from test1 order by salary desc limit 3;
create index idx_salary on test1(salary);
explain select * from test1 order by salary desc limit 3;
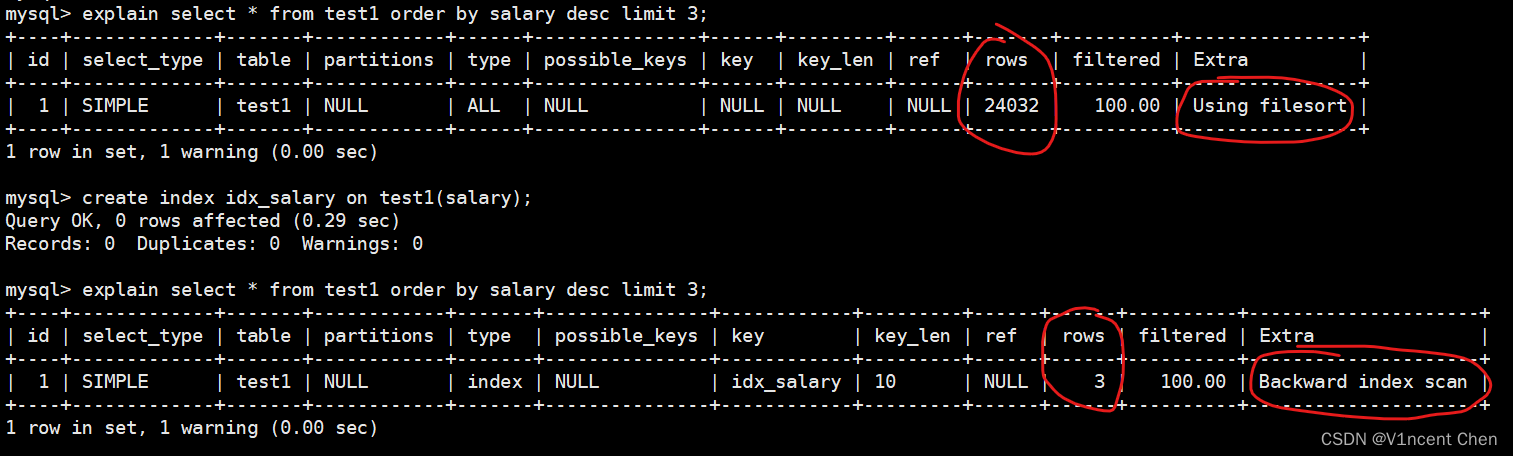
可以看到索引反向扫描替代了原来的排序操作,同时扫描的行数量从24032降低到了3。
二、limit分页优化
limit子句最常用场景就是数据分页,通过变更偏移量来对数据进行分页展示。例如第一页显示100条数据,limit子句就是limit 0,100。第二页是limit 100,100,第三页是limit 200,100…. 但是当页数非常大时,limit m,n 中被丢弃的m条数据可能成为性能瓶颈。
由于前m条数据(偏移量)是最终需要的丢弃的,它们的内容我们并不关心,因此优化的思路就是"避免查询前m条数据的内容"。
2.1 延迟关联
为了避免查询偏移量m条数据的内容,我们可以先通过索引获取的n条数据的偏移量/主键(而不是对全量数据进行排序),然后通过主键直接获取n条数据的内容。这种策略叫做"延迟关联"。
例如查询:
select * from test1 order by salary desc limit 10000,100;
通过延迟关联可以改写为:
select salary from test1
join ( select id from test1 order by salary desc limit 10000,100) d on d.id=test1.id;
如果salary列上有索引,那么获取id是不需要回表的,通过索引就可以获取n条数据的主键,随后再与主表关联,通过主键取出这n条数据内容。虽然SQL看起来稍微复杂了,但是它绕过了获取前m条数据内容这个步骤,当m值比较大时,性能提升是很明显的。
2.2 转换为位置查询
这种策略是根据排序条件预先计算每行记录的顺序编号并加上索引,例如在表中新增一列position(或者单独新增一张顺序表也可以),保存的是每一行位置顺序。这相当于分页排序已经预先执行了,而偏移操作就被转换成了索引范围扫描。
例如查询:
select * from test1 order by salary desc limit 10000,100;
通过位置查询可以改写为:
select * from test1 where position between 10001 and 10100;
position列是根据order by salary desc条件预先维护好的每一列的顺序编号,此后每次分页查询都不需要计算偏移量,而是被转换成了索引范围扫描(Index Range Scan)。
2.3 记录偏移位置
记录偏移位置的方法,就是当排序列存在顺序的情况下,每次查询后将其最后的值记录下来,然后作为下一次SQL查询的过滤条件。
假设首次查询如下(id列单调递增):
select * from test1 order by id limit 9900,100;
假设上面查询返回结果集的最大id为123456,程序可以将这个值单独记录下来,那么SQL:
select * from test1 order by id limit 10000,100;
就可以改写为:
select * from test1 where id>123456 order by id limit 100;
通过条件where id>123456就可以过滤掉前m条数据,但这种方法的缺陷就是它只能一页一页的顺序往后翻,不能跳转翻页,对比上面2种方法不够灵活。
这篇关于MySQL limit子句用法及优化(Limit Clause Optimization)的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







