本文主要是介绍破除“数据孤岛”新策略:Data Fabric(数据编织)和逻辑数据平台,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
今天,我们已经进入到一个数据爆发的时代,仅 2022 年,我国数据产量就高达 8.1ZB,同比增长 22.7%,数据产量位居世界第二。数据作为新型生产资料,是企业数智化运营的基础,已快速融入到生产、分配、流通、开发、应用、服务等各环节之中,深刻改变着企业的生产方式、管理方式和经营模式。通过数据驱动,能够帮助企业不断提高业务决策效率和质量,适应快速变化的商业环境,构建新质生产力。
然而,伴随数据产生、收集、存储和消费的速度和规模不断扩大,传统的数据管理架构、数据仓库等策略已经跟不上新时代的需求,导致了一个个“数据孤岛”的产生,严重阻碍了企业数智化进程。例如:随着业务发展,数据基础设施与组织架构持续演进,形成多层级、多地域的离散数据架构;大数据技术持续升级换代和 AI 技术的发展,使企业内存在不同代际的计算、引擎与大数据技术架构;大型企业中,不同的业务单元或部门可能根据自身需求独立发展,形成了各自为政的数据管理体系;考虑到数据的敏感性和隐私性,一些组织和部门担心敏感数据泄露或被滥用,只在独立的系统中存储和处理一些关键数据等。
可以说,“数据孤岛”的存在,直接导致企业的数据共享、流通、交换和集成变得愈加困难,这显然难以适应越来越多的业务端“看数、用数”、以数据驱动决策的需求。只有让数据更高效、更便捷、更低成本地流向更需要的地方,让多源异构的优质数据在业务场景中整合集成,帮助业务人员快速决策,才能真正释放数据价值,助力商业成功。此外由于不同部门或系统之间使用不同的数据源、数据格式等,导致数据冗杂、重复,造成资源浪费,也增加了企业的数据存储和管理成本。
为解决“数据孤岛”问题,企业往往选择构建一个统一的数据湖仓,或者数据中台,通过 ETL 等技术手段,以实现数据的集中存储、管理和消费。但这种方式过于依赖人工作业,远远跟不上企业看数、用数的需求。
在此背景下,Data Fabric(数据编织)数据管理理念兴起,将自动化能力添加到整个数据管理中,通过数据虚拟化技术构建统一的逻辑数据视图,优化跨源异构数据的发现与访问,使数据管理工作量减少 70% 并加快价值实现速度,打破企业内部的“数据孤岛”,最大化释放数据价值。
作为国内 Data Fabric(数据编织)数据管理架构理念的实践者和引领者,Aloudata 大应科技开创性地提出了“NoETL”理念,旨在以“自动化”代替人工 ETL,系统性地提升数据管理与数据价值挖掘的效能。
为帮助企业解决“数据孤岛”问题,Aloudata 打造了国内首个 Data Fabric 逻辑数据平台—— Aloudata AIR,通过自研的数据虚拟化技术和 AI 增强自适应物化加速,可帮助企业轻松实现多源异构数据的逻辑集成和智能查询下推,并通过全局数据目录和统一数据服务为下游用户与应用提供统一的数据发现与访问入口,解决由“数据孤岛”带来的全局数据查找难、跨源联邦查询难和集中安全治理等问题,支持业务灵活开展数据分析工作。
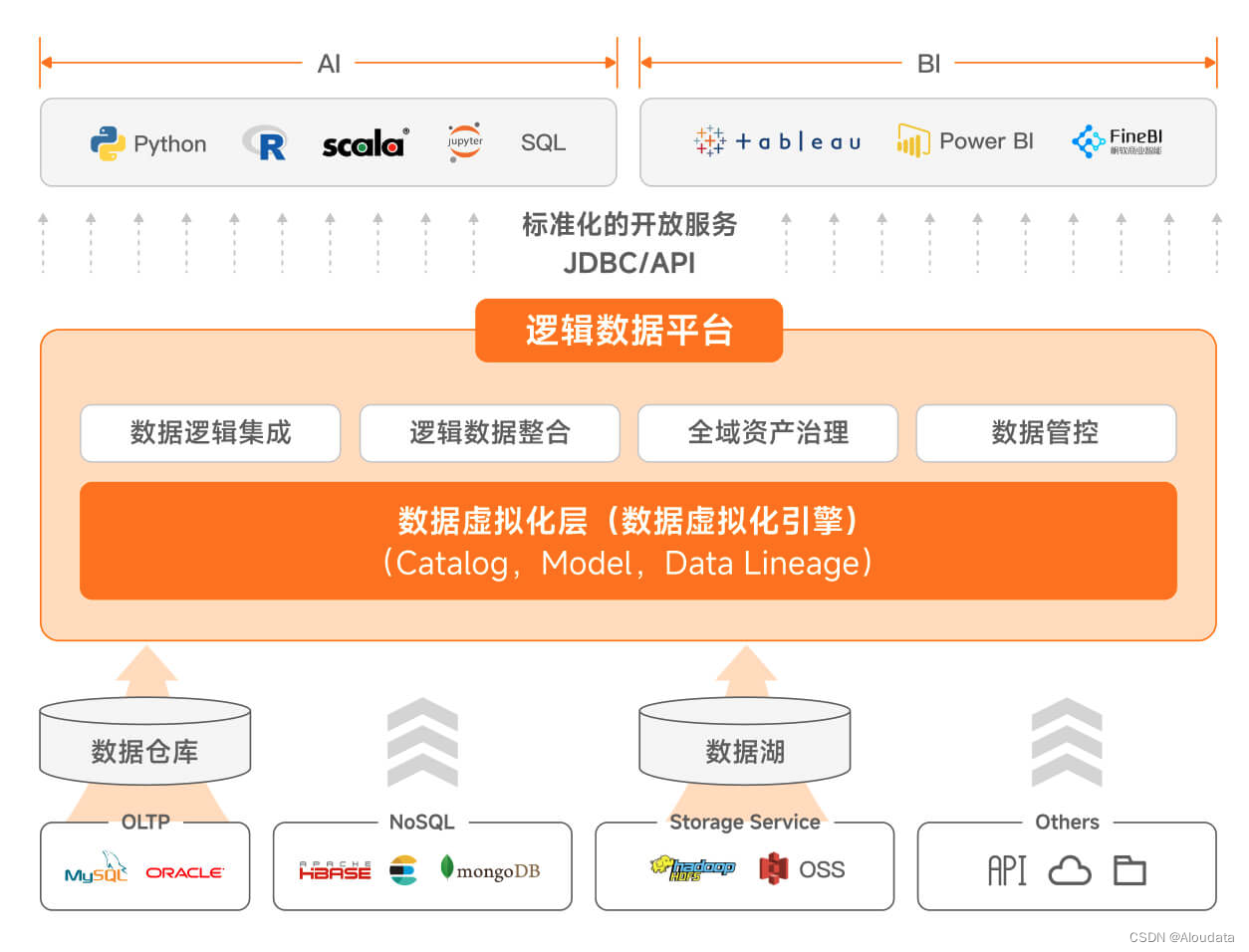
- 秒级数据集成:数据源接入即可实时查询;无物理数据同步,数据可实时保鲜;无需维护大量贴源层的数据同步任务,显著节省存算成本,同时避免数据权责转移带来的数据归属及数据质量等维护问题。
- 统一数据服务与全域资产管理:构建全域数据资产视图与目录;统一数据查询和访问入口;统一企业全部数据的权限管控、审计与数据脱敏。
- 自动化数据加工:自动生成 ETL 作业和作业回收,存算成本节约 50%+,人工作业量下降 70%+;智能查询下推与自适应的查询加速确保大规模数据加工性能;支持任意层级视图嵌套和任意 SQL 复杂度的视图加速和命中改写。
- 便捷化数据消费:一套 SQL 语法实现数据集成、逻辑整合和数据消费全链路取数和用数场景;面向业务,屏蔽不同引擎的技术差异与复杂性;需求交付效率 10 倍提升。
- 基础设施开放兼容:内置或复用已有计算引擎;逻辑数据平台层同底层引擎解耦;逻辑数据平台层同底层引擎解耦,支持企业未来透明升级新的大数据引擎及解决方案,例如基础设施升级(替换任意数据湖或数仓方案)场景下,屏蔽给上层业务带来的影响。
目前,Aloudata AIR 逻辑数据平台已在极高复杂度的数据生产和消费环境中落地应用,帮助首创证券轻松实现全域数据的集成整合,数据分析人员不再受“数据孤岛”限制,通过逻辑化集成整合,零数据搬运轻松实现 10+ 个不同数据源的快速、准确融合,并利用自适应查询加速能力,1 秒查询响应率达 95%,存算成本节约 70% 以上。
如果您最近正遇到“数据孤岛”困局,或者计划考虑通过统一数据服务平面屏蔽底层引擎的差异性,提升业务用数效率,不妨先了解下 Aloudata AIR 逻辑数据平台,或许能为您带来新的思路。
这篇关于破除“数据孤岛”新策略:Data Fabric(数据编织)和逻辑数据平台的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





