本文主要是介绍一文理清OCR的前世今生,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
AI应用开发相关目录
本专栏包括AI应用开发相关内容分享,包括不限于AI算法部署实施细节、AI应用后端分析服务相关概念及开发技巧、AI应用后端应用服务相关概念及开发技巧、AI应用前端实现路径及开发技巧
适用于具备一定算法及Python使用基础的人群
- AI应用开发流程概述
- Visual Studio Code及Remote Development插件远程开发
- git开源项目的一些问题及镜像解决办法
- python实现UDP报文通信
- python实现日志生成及定期清理
- Linux终端命令Screen常见用法
- python实现redis数据存储
- python字符串转字典
- python实现文本向量化及文本相似度计算
- python对MySQL数据的常见使用
- 一文总结python的异常数据处理示例
- 基于selenium和bs4的通用数据采集技术(附代码)
- 基于python的知识图谱技术
- 一文理清python学习路径
- Linux、Git、Docker常用指令
- linux和windows系统下的python环境迁移
- linux下python服务定时(自)启动
- windows下基于python语言的TTS开发
- python opencv实现图像分割
- python使用API实现word文档翻译
- yolo-world:”目标检测届大模型“
- 爬虫进阶:多线程爬虫
- python使用modbustcp协议与PLC进行简单通信
- ChatTTS:开源语音合成项目
- sqlite性能考量及使用(附可视化操作软件)
- 拓扑数据的关键点识别算法
- python脚本将视频抽帧为图像数据集
- 图文RAG组件:360LayoutAnalysis中文论文及研报图像分析
- Ubuntu服务器的GitLab部署
- 无痛接入图像生成风格迁移能力:GAN生成对抗网络
- 一文理清OCR的前世今生
文章目录
- AI应用开发相关目录
- 简介
- 技术架构
- 技术变迁
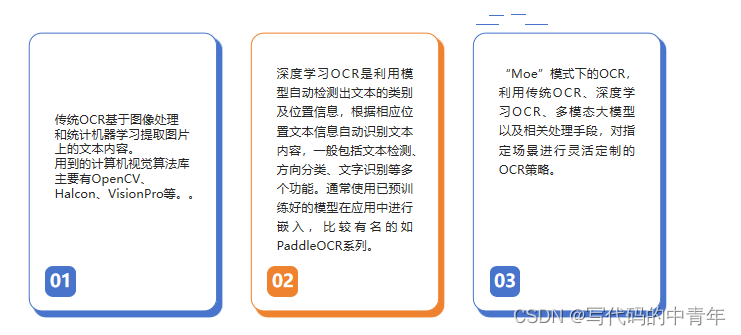
- 阶段1:基于图像处理和统计机器学习的OCR
- 该阶段下,OCR特点:
- 阶段2:基于深度学习的OCR
- 阶段2下的OCR特点:
- 阶段3:基于多模态大模型的OCR
简介
什么是OCR?
计算机文字识别,光学字符识别,英文全称Optical Charater Recognition,简称OCR.
是利用光学技术和计算机技术把印刷在或者写在图纸上的文字以文本形式提取出来,并转换成一种计算机能够接受、人又可以理解的格式的技术。OCR技术是实现文字快速录入的一项关键技术。在信息社会时代,每天会产生大量的票据、表单、证件数据,这些数据要电子化,需要利用OCR技术进行提取录入。
简而言之,OCR其本质是一种信息提取手段,也是一种工作提效方法。
技术架构

图像预处理:这一步骤主要是对输入的图像进行优化,以便更好地进行文字检测和识别。预处理可能包括以下步骤:
二值化:将图像转换为黑白两种颜色,便于后续处理。
降噪:去除图像中的噪声,如随机点、划痕等。
校正:对图像进行倾斜校正,使其文字行水平或垂直。
归一化:统一图像的尺寸和分辨率,便于后续算法处理。
文字检测:这一步骤是在预处理后的图像中定位文字区域。文字检测的方法有很多,包括:
基于连通区域的方法:通过分析图像中的连通区域来寻找文字。
基于特征的方法:利用文字的笔画、角点等特征进行检测。
基于深度学习的方法:使用卷积神经网络(CNN)等深度学习模型进行文字区域的检测。
文字识别:在检测到文字区域之后,需要对区域内的文字进行识别。文字识别的方法主要有两种:
基于规则的方法:通过分析文字的笔画结构和排列规则进行识别。
基于深度学习的方法:使用循环神经网络(RNN)、卷积神经网络(CNN)或结合这两种网络的模型进行文字识别。
后处理:在文字识别之后,可能需要进行一些后处理步骤来提高识别结果的准确性。后处理可能包括:
校对:利用语言模型和规则对识别结果进行校对和纠正。
格式化:将识别出的文本按照原文的格式进行排版。
结构化:提取文本中的关键信息,如标题、段落、表格等,并进行结构化处理。
技术变迁
OCR技术主要包括图像预处理、文字检测、文字识别以及后处理等几个关键环节。
而OCR技术的历史变迁,也集中于此,其中文字检测和文字识别两个环境变化最为明显。
阶段1:基于图像处理和统计机器学习的OCR

该阶段中,预处理手段包括:
图像低照度处理、图像倾斜校正、文字倾斜校正、文字扭曲校正等等内容,其解决方法包括图像二值化、最小面积矩形轮廓查询、霍夫线变换、比例缩放等技术。

文字检测则可以通过投影法实现分割实现。

文字识别则可通过图像匹配。
该阶段下,OCR特点:
1.文字提取时,面对不同的需求,需要专门设计不同的算法加以解决。
2.文字提取时,要完成需求,提取步骤较多,步骤间耦合性强,整体算法鲁棒性差。
3.文字提取时,其效果较差,精度低。
4.文字提取后,结果需进行大量后处理,如结果的拼接、格式化等。
5.算法具备高度可解释性。
阶段2:基于深度学习的OCR
其中预处理可通过GAN等生成对抗网络进行图像清晰度复原等工作。
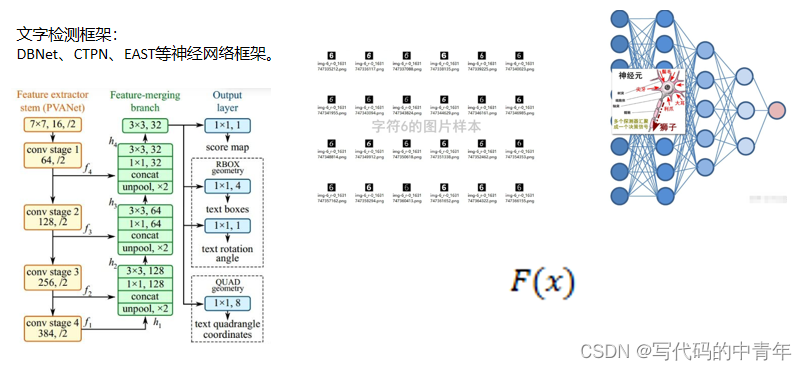

文字检测和文字识别通用可以通过深度学习算法进行实现,不再依赖简单的图像学和统计算法。
其中最具代表性的是百度飞桨平台推出的OCR模型。
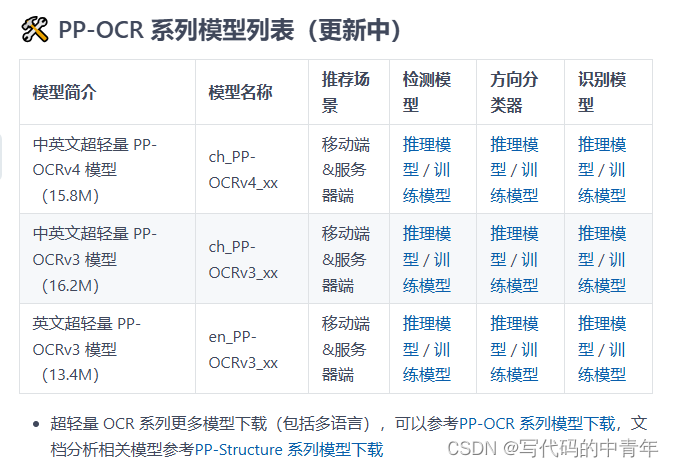
其模型功能涵盖了文字检测、方向检测、内容提取三项。
此外,飞桨针对具体场景,如数码管、表单、表格等数据更是研究了数码管专项识别、版面识别、文本超分等内容。
阶段2下的OCR特点:
1.文字提取时,采用深度学习技术完成文字检测和识别,依赖神经网络完成对图像特征的提取。
2.文字提取时,其效果较强,精度较高,具备一定的鲁棒性。
3.文字提取后,结果需进行大量后处理,如结果的拼接、格式化等。
4.算法具备高度一定的解释性。
阶段3:基于多模态大模型的OCR
该阶段内容我曾在往期博客中多次提到,本次进行总结。
https://blog.csdn.net/qq_43128256/article/details/139685113
https://blog.csdn.net/qq_43128256/article/details/138574623
https://blog.csdn.net/qq_43128256/article/details/138163078
https://blog.csdn.net/qq_43128256/article/details/138337768
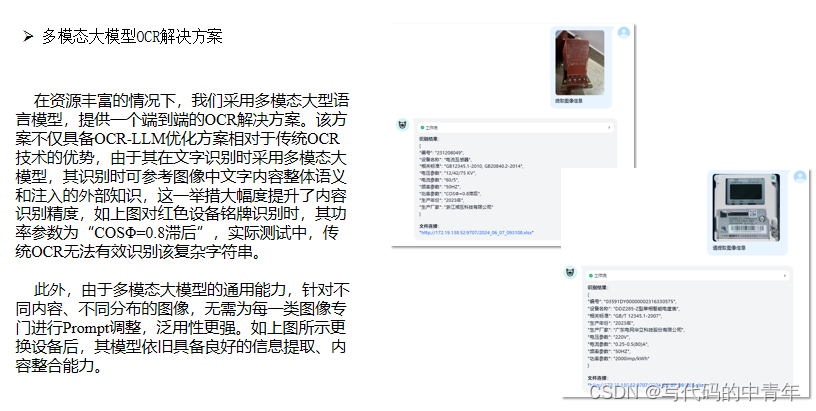
传统OCR采用深度学习模型通过文字检测、方向检测、文字识别的步骤完成文字的抽取工作,在应用落地上的困难,从效果上存在一定缺陷,本案例如右图所示,以PaddleOCR开源模型为例,总结表述如下:
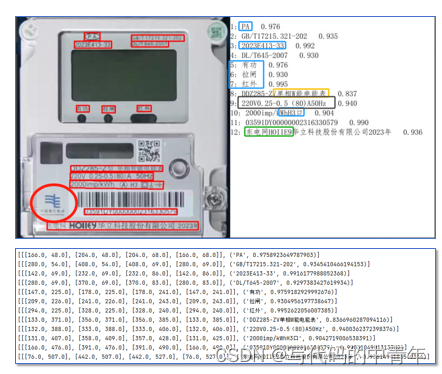
1.检测能力不足,如上图圆圈信息未能识别。
2.识别精度不足,如上图橙框内容,为误识内容。
3.冗余信息较多,如上图蓝框内容,50%无意义内容。
4.结果分布紊乱,如上图黑框内容,各参数无有效区分,且掺入了误识内容;此外结果整体与无意义内容错落分布,可用性较差。
5.智能化水平低,如上图绿框内容,传统模式无语义理解和逻辑推理能力,对于“广东电网”的广字无补全能力。
大模型OCR方案的主要创新点包括:
(1)灵活的OCR赋能分治方案:在不同资源场景下,采用不同的赋能方式。资源受限时,采用传统识别模式配合通用大语言模型能力实现信息的智能提取;否则,利用多模态大模型将信息识别、内容分析、格式整合等步骤一站式完成。
(2)多类型图像的Agent识别策略:LLM的引入Agent策略,可使模型面向不同类型图像时可自主决定使用不同的工具进行处理,这种端到端优化但有定制化优点的策略,可在拓充OCR泛用性的同时保持系统性能。
(3)复杂图像的鲁棒性识别:面对复杂的图像,传统OCR识别能力不足,识别错误率高,识别结果分布杂乱。LLM能够理解复杂的语言结构和图像语义,为LLM进行知识注入可有效提高OCR在复杂场景下的识别准确率。
(4)碎片化结果的格式化整合:传统OCR的识别结果往往是结果碎片化的,可用性低。LLM通过上下文理解和语义分析可改善OCR的后处理流程,提高文本的连贯性和可用性。
(5)多语言和多字体支持:LLM在多语言和多字体上的训练和应用,为OCR技术提供了更广泛的语言和字体支持,有助于实现更广泛的应用场景,具备更强的实用性。
(6)交互式OCR:LLM的生成能力可以用于提供交互式OCR结果,提高用户体验。
这篇关于一文理清OCR的前世今生的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






