本文主要是介绍Apache Druid-时序数据库,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
- Apache Druid:是是一个集时间序列数据库、数据仓库和全文检索系统特点于一体的分析性数据平台,旨在对大型数据集进行快速的查询分析("OLAP"查询)。Druid最常被当做数据库来用以支持实时摄取、高性能查询和高稳定运行的应用场景,同时,Druid也通常被用来助力分析型应用的图形化界面,或者当做需要快速聚合的高并发后端API,Druid最适合应用于面向事件类型的数据。
- 特性
- 实时数据摄取:Druid能够实时地处理和索引数据,使其几乎可以立即查询。
- 高性能查询:Druid优化了查询性能,特别是对于聚合查询和数据切片,这在传统的关系型数据库中可能需要很长时间。
- 灵活的数据模型:Druid支持灵活的数据模型,允许用户定义数据的维度和度量,以适应不同的分析需求。
- 水平扩展:Druid设计为分布式系统,可以水平扩展以处理PB级别的数据。
- 高可用性:Druid的架构支持高可用性,通过复制数据和查询负载均衡来实现。
- 丰富的集成:Druid可以与多种数据源和数据管道工具集成,如Apache Kafka、Apache Hadoop等。
- 主要查询方式及参数说明
- Druid原生查询
- Druid SQL查询
- 主要参数
- queryType: 指定查询的类型,对于时间序列查询,这个值通常是 "timeseries"。
- dataSource: 指定查询的数据源名称,即要从哪个数据表或数据集进行查询。
- intervals: 定义查询的时间范围,可以是一个或多个时间区间。格式通常是 ISO 8601 格式,例如 "2019-01-01T00:00:00Z/2019-01-02T00:00:00Z"。
- granularity: 指定查询的粒度,可以是 "all"(表示整个数据集)、"hour"、"day"、"week"、"month"、"year" 或自定义的粒度。
- filter: 定义查询的过滤条件,可以是各种类型的过滤器,如选择器(selector)、布尔(boolean)等。
- aggregations: 定义聚合操作,用于对数据进行汇总计算。可以包含多个聚合,每个聚合都有自己的字段名、类型和名称。
- postAggregations: 定义在聚合之后执行的二次计算,用于对聚合结果进行进一步的处理。
- dimensions: 指定要返回的维度列,可以是维度的数组。
- metrics: 指定聚合操作的输出名称,通常与聚合操作中的 name 字段对应。
- orderBy: 指定结果的排序方式,可以是按照时间或特定维度排序。
- limitSpec: 定义结果集中返回的行数限制。
- context: 提供查询的上下文信息,可以包含各种设置,如超时时间、查询优先级等。
- having: 指定过滤聚合结果的条件,通常在聚合之后应用。
- intervalsOverride: 覆盖查询中定义的时间区间。
- descending: 指定是否按降序返回结果。
- 案例:
- {
- "queryType":"topN",
- "dataSource":"taxi_message",
- "dimension":"local",
- "threshold":2,
- "metric":"age",
- "granularity":"month",
- "aggregations":[
- {
- "type":"longMin",
- "name":"age",
- "fieldName":"age"
- }
- ],
- "filter":{"type":"selector","dimension":"sex","value":"女"},
- "intervals":["2021-06-07/2022-06-07"]
- }
- Druid 最开始的时候是不支持 SQL 查询的,原生查询是通过查询 Broker 提供的 http server 来实现的
- Druid API 接口及其作用
- 原生查询方式
- /druid/v2/pretty:JSON格式请求,返回JSON结果集
- SQL 查询接口:
- /druid/v2/sql:执行 SQL 查询,返回查询结果。
- 数据摄取(Ingestion)接口:
- /druid/indexer/v1/task: 提交数据摄取任务,用于将数据加载到 Druid 中。
- 数据源(DataSource)管理接口:
- /druid/coordinator/v1/datasources: 获取所有数据源的列表。
- /druid/coordinator/v1/datasources/{dataSource}: 获取指定数据源的详细信息。
- 任务管理接口:
- /druid/indexer/v1/task: 提交数据摄取任务。
- /druid/indexer/v1/supervisor: 管理数据摄取的监督器(Supervisor)任务。
- 查询历史(Query History)接口:
- /druid/query/history: 获取查询历史记录。
- 集群协调(Coordinator)接口:
- /druid/coordinator/v1/cluster: 获取集群状态信息。
- /druid/coordinator/v1/leader: 获取当前集群的领导者节点。
- 数据节点(Data Node)接口:
- /druid/dataNode/v1: 获取数据节点的状态信息。
- 历史节点(Historical Node)接口:
- /druid/historical/v1: 获取历史节点的状态信息。
- 实时节点(Realtime Node)接口:
- /druid/v2/datasources/{dataSource}/intervals: 获取实时数据源的活跃时间区间。
- 配置管理接口:
- /druid/indexer/v1/worker: 获取工作节点的配置信息。
- 监控和状态接口:
- /druid/broker/v1: 获取 Broker 节点的状态信息。
- /druid/overlord/v1: 获取 Overlord 节点的状态信息。
- 元数据存储接口:
- /druid/metadata/v1: 与元数据存储交互,例如获取或更新表的元数据。
- 任务状态接口:
- /druid/indexer/v1/task/{taskId}: 获取特定任务的状态和结果。
- 原生查询方式
- 开发人员须知的概念
- 数据源:
- 段的生命周期管理包括创建、发布和可用性检查。新创建的段首先由MiddleManager生成并标记为未提交(uncommitted),此时数据已经可以被查询。随着时间的推移,段会被提交并发布到深度存储,变为不可变(immutable),并由Historical进程进行管理。Coordinator负责监控新的段,并指导Historical加载这些段以提供服务
- 数据源中的数据被组织成多个段(Segment),每个段代表一个时间区间的数据。例如,如果数据源按天分区,那么每个chunk将代表一天的数据。每个段内部,数据被优化存储,包括列式存储、使用位图索引进行索引等,这些都是为了加快查询速度而设计的。
- 数据源在Druid中的作用类似于传统数据库中的表。每个数据源包含特定时间段的数据,并且可以按事件分区,也可以根据需要按其他属性进一步分区。这种分区机制使得Druid能够有效地管理和查询大量数据。
- 索引:
- Druid支持多种索引类型,包括全文搜索索引、嵌套索引和主键索引。这些索引类型可以单独使用或组合使用,以满足不同的查询需求。
- 索引在Druid中是可选的,但如果正确使用,可以显著提高查询性能。例如,主键索引可以加速表扫描,而全文搜索索引则支持高效的文本搜索。
- 索引的创建和管理是通过Druid提供的工具和API进行的,开发人员需要熟悉这些工具来优化他们的数据查询。
- 查询语言:
- Druid的原生查询语言提供了一种高效且灵活的方式来处理复杂的分析查询。这种语言支持各种操作,如时间序列分析、聚合和过滤。
- 学习Druid的查询语言对于充分利用其分析能力至关重要。虽然起初可能是挑战性的,但掌握它可以极大地增强数据处理的能力。
- 数据摄取:
- Druid设计用于处理实时数据摄取,这意味着它能够快速接收并处理流数据。这对于需要快速响应数据变化的应用来说非常重要。
- 数据摄取的过程可以通过Druid的管理界面或API进行配置,开发人员需要了解这些选项以确保数据的正确和高效流入。
- 安全性:
- Druid支持基于角色的访问控制,这允许管理员为不同的用户和应用程序分配不同的权限级别。
- 开发人员需要了解如何配置这些权限,以确保数据的安全性和合规性。
- 数据源:
- 参考链接
- 快速开始 · ApacheDruid中文技术文档
- 对比
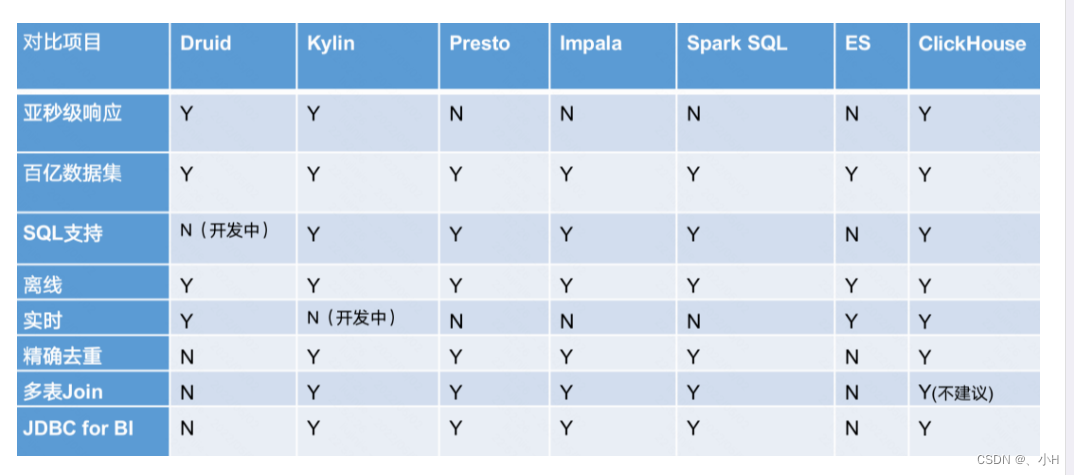
这篇关于Apache Druid-时序数据库的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






