本文主要是介绍【CVPR2024】面向StableDiffusion的编辑算法FreePromptEditing,提升图像编辑效果,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
近日,阿里云人工智能平台PAI与华南理工大学贾奎教授团队合作在深度学习顶级会议 CVPR2024 上发表 FPE(Free-Prompt-Editing) 算法,这是一种面向StableDiffusion的图像编辑算法。在这篇论文中,StableDiffusion可用于实现图像编辑的本质被挖掘,解释证明了基于StableDiffusion编辑的算法本质,并基于此设计了新的图像编辑算法,大幅度提升了图像编辑的效率。
论文:Bingyan Liu, Chengyu Wang, Tingfeng Cao, Kui Jia, Jun Huang. Towards Understanding Cross and Self-Attention in Stable Diffusion for Text-Guided Image Editing. CVPR 2024
背景
近年来,文本到图像合成(Text-to-Image Synthesis,TIS)模型如Stable Diffusion、DALL-E 2和Imagen,在将文本描述转换为视觉图像方面表现出色,引起了学术界和产业界的极大兴趣。这些模型通过在庞大的图像-文本对数据集(例如Laion)上进行训练,并集成了尖端技术如大规模预训练的语言模型、变分自编码器和扩散模型,能够生成逼真且细节丰富的图像。尤其是Stable Diffusion模型,它不仅在图像生成领域广受欢迎,还对开源社区做出了显著的贡献。除生成能力外,这些TIS模型还具备强大的图像编辑功能,深入研究并利用其基于文本提示的编辑潜能至关重要,因为它们能在保持图像高质量和自然感的前提下实现内容的变更。目前一些流行的Traing-free的图像编辑方法,如Prompt-to-Prompt(P2P),通过更换源提示中与目标编辑词相关的交叉注意力图来定位指示图像需要修改的区域,但引入源图像的交叉注意力图进行修改可能导致预期外的结果。同样,Plug-and-Play(PnP)方法在提取原始图像的空间特征和自注意力特征后,将这些特征注入到目标图像的生成过程中,但这种操作如果处理不当,同样可能导致不尽人意的结果。例如,如果在交叉注意力层上进行编辑,可能无法成功地将人类图像编辑成机器人形象,或者无法将汽车颜色更改为红色,这些案例中的失败可能归因于注意力层的不恰当处理。

图1. 图像编辑的失败案例以及我们提出的方法成功编辑的结果
虽然目前流行的图像编辑算法可以在一定程度上对图像进行编辑,但是这些方法对交叉和自注意力图的语义仍缺乏解释与探索。为了探索并解释扩散模型中注意力图的含义,在我们的论文中,我们提出了这样的一个疑问:文本条件扩散模型的注意力图是否仅仅是权重矩阵,是否还包含图像的特征信息? 为了回答这些问题,我们通过探针分析实验来探索注意力图。
Attention map 探针分析
我们探针实验的核心思想是: 如果分类器能够准确地对来自不同类别的注意力图进行分类,那么该注意力图就包含类别信息的有意义的特征表示。为了更直观地展示探针实验的效果,我们选择了颜色和动物类别的单词组成的文本,并提取出颜色和动物单词对应的交叉注意力图以及自注意层中的自注意力图作为元数据。其中,颜色类形容词使用的prompt模板为:"a/ancar"。动物类名词词使用的prompt模板为:"a/anstanding in the park". 此外我们,还构建了其他类型的模板进行实验,如"a/an<object>", "a photo of acar and a dog", "a man and acar"等复杂模板的实验,具体实验结果可以阅读我们的论文。
探针实验结果及结论
我们分别对不同层的交叉注意力图、自注意力图以及非编辑单词的交叉注意力图进行了探针实验分析,探针实验结果如下所示:
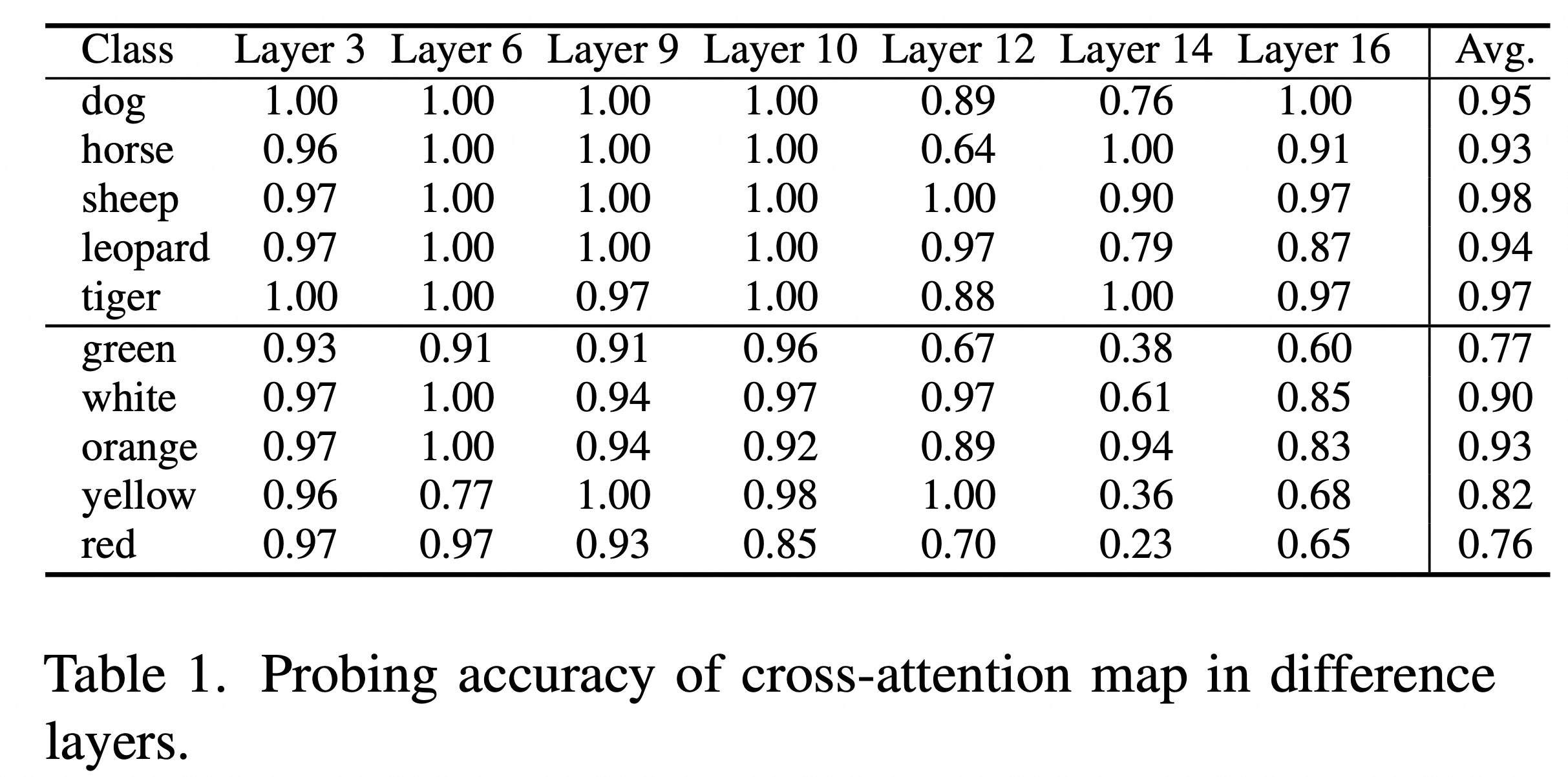
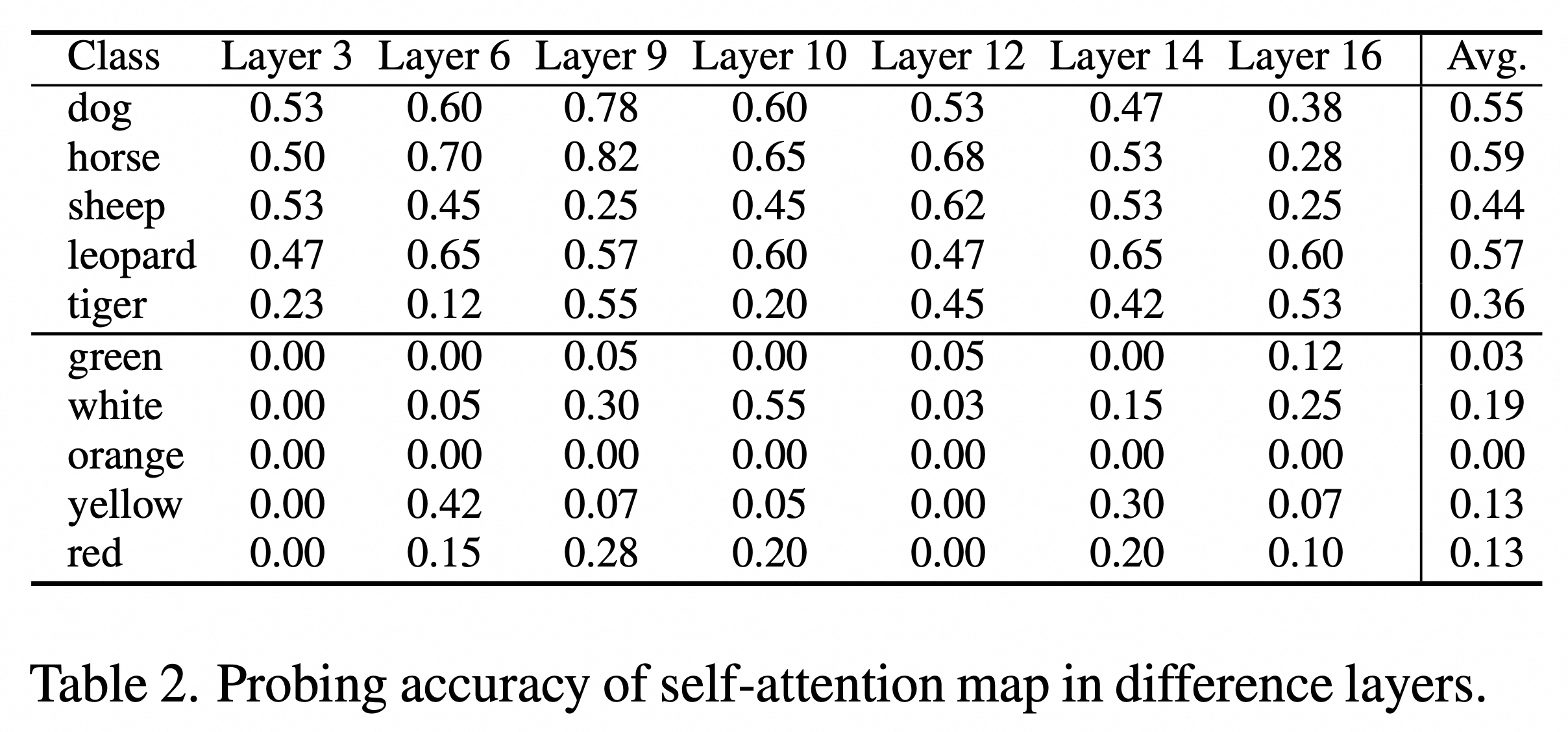
我们发现:(1)在扩散模型中编辑交叉注意力图对于图像编辑来说是可选的。替换或完善源和目标图像生成过程中的交叉注意力图是不必要的,并可能导致图像编辑失败。(2)交叉注意力图不仅是条件提示在生成图像对应位置的权重测量,也包含了条件标记的语义特征。因此,用源图像的交叉注意力图替换目标图像的图可能会产生意外的结果。(3)自注意力图对于TIE任务的成功至关重要,因为它们反映了图像特征之间的关联,并保留了图像的空间信息。以下是使用不同的注意力图执行图像编辑的实验结果。

图2. 不同扩散模型的注意力层上对交叉注意力图和自注意力图进行替换的图像编辑实验结果

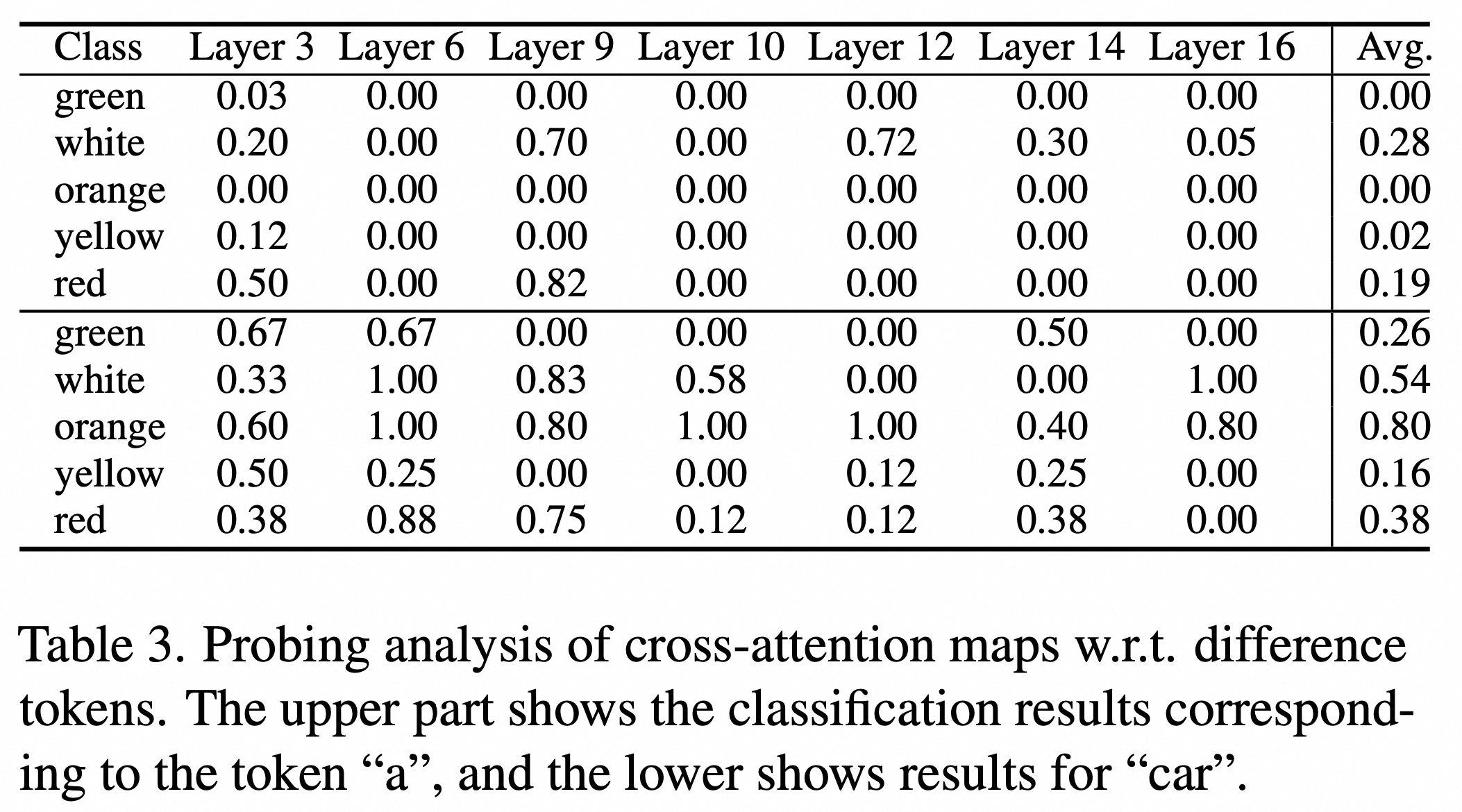
图3. 编辑提示中替换不同token的 交叉注意图的结果。
“-”是一个减号。- “a” 表示减去 "a“ 对应的交叉注意力图。图2上半部分展示了在不同交叉注意力层进行单词替换(如“rabbit”和“coral”)后的编辑结果,当所有交叉注意力层的图都被替换时,结果最不理想。相对而言,保持交叉注意力图不变时,能得到更加准确的编辑效果。图2下半部分则展示了在不同自注意力层上进行操作的实验结果。当在目标图像生成过程中替换源图像所有层的自注意力图时,所生成的图像确实保留了原始图像的结构信息,但会导致编辑目的完全失败。相反,如果完全不替换自注意力图,最终得到的图像将与直接根据目标提示生成的图像一致。作为一种折中,选择替换第4层至第14层的自注意力图,这种方法能够在保证编辑成功的同时,尽可能保留原始图像的结构信息。图3也验证了即使是替换与非编辑单词对应的交叉注意力图,也可能导致编辑失败,突显出在图像编辑中注意力图操作的复杂性和微妙性。
算法架构
基于探针实验的结果,我们优化了目前流行的图像编辑算发,我们提出了一种更直接、更稳定、更高效的方法,称为Free-Prompt-Editing(FPE)。FPE核心思想是将源图像的空间布局和内容与目标文本提示合成的语义信息相结合,合成所需的目标图像。FPE源图像和目标图像之间的去噪过程中,在扩散模型的注意力层 4 至 14 中采用了自注意力替换机制。对于合成图像编辑,FPE在扩散去噪过程中用源图像的自注意力图替换目标图像的自注意力图。 在对真实图像编辑时,FPE首先通过使用DDIM-inversion操作来获得重建真实图像所需的潜在特征。 随后,在编辑过程中,我们在目标图像的生成过程中替换真实图像的自注意力图。FPE能够完成TIE任务的原因如下: 1)交叉注意力机制有利于合成图像和目标提示的融合,甚至可以让目标提示和图像自动对齐 无需引入源提示的交叉注意力图;2)自注意力图包含源图像的空间布局和形状细节,自注意力机制允许将结构信息从源图像注入到生成的目标图像中。算法框架及伪代码如下:

图4. Free-Prompt-Editing 在对合成图像进行编辑的过程示意图

图 5:Free-Prompt-Editing 在合成图像编辑和真实图像编辑场景下的伪代码
实验结果
图6展示了FPE的编辑结果,它成功地转换了原始图像的各种属性、风格、场景和类别。

图 6:Free-Prompt-Editing 编辑结果示例
图7呈现了FPE技术应用于基于稳定扩散算法的其他定制模型中的编辑效果。观察这些成果,我们可以发现FPE技术能够高效地适用于各种扩散模型。它不仅成功实现了性别转换,把女孩变为男孩,还能够调整人物的年龄,使男孩呈现出10岁或80岁的特征;此外,它还能修改发型、变换头发色彩、替换背景乃至进行类别上的转变。

图 7:Free-Prompt-Editing 编辑结果示例
图8对比展示了FPE与其他一些SOTA图像编辑技术的效果。无论是对真实照片还是合成图像,FPE均展现出了高效的编辑能力。在所有的案例中,FPE都能够实现与描述提示高度一致的精细编辑,同时最大限度地保留了原图的结构细节。

图 8:Free-Prompt-Editing 与其他编辑方法的对比
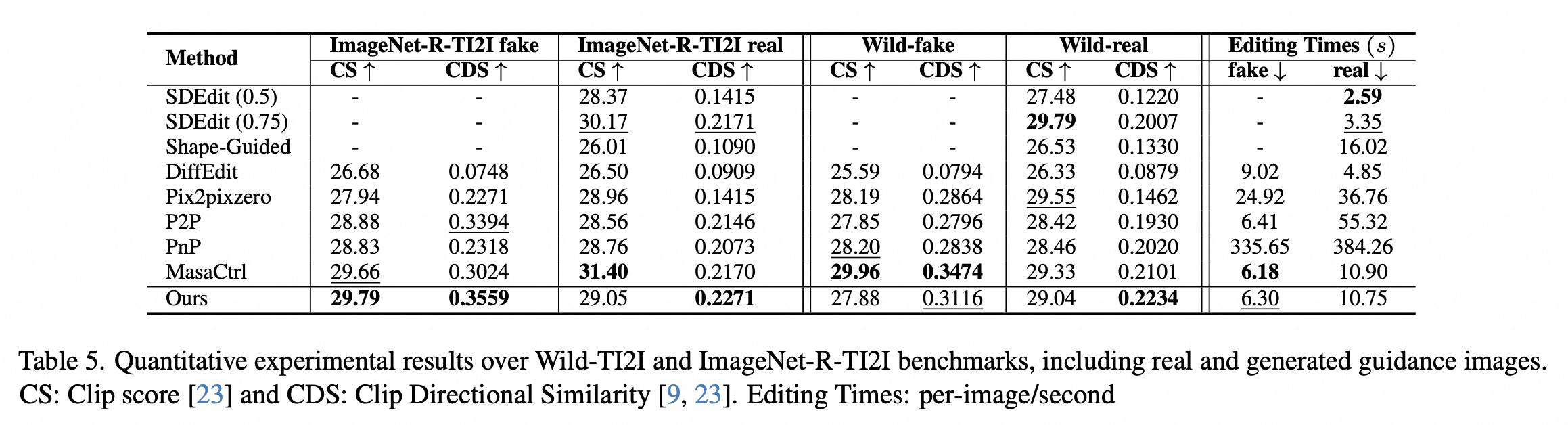
下表展示了不同编辑算法在 Wild-TI2I 和 ImageNet-R-TI2I 基准上的定量实验结果。可以看出,我们的方法在 CDS 指标方面明显优于所有其他方法,这表明我们的方法能够很好地保留原始图像的空间结构,并根据目标提示的要求进行编辑,产生了良好的结果。 同时,我们的方法在时间消耗和有效性之间实现了良好的平衡。
更多的实验结果及讨论,欢迎阅读论文:Towards Understanding Cross and Self-Attention in Stable Diffusion for Text-Guided Image Editing。目前 Free-Prompt-Editing 已经在 EasyNLP(EasyNLP/diffusion/FreePromptEditing at master · alibaba/EasyNLP · GitHub)开源。欢迎广大用户试用!
参考文献
-
Rombach R, Blattmann A, Lorenz D, et al. High-resolution image synthesis with latent diffusion models[C]//Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. 2022: 10684-10695.
-
Hertz A, Mokady R, Tenenbaum J, et al. Prompt-to-prompt image editing with cross attention control[J]. arXiv preprint arXiv:2208.01626, 2022.
-
Brooks T, Holynski A, Efros A A. Instructpix2pix: Learning to follow image editing instructions[C]//Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 2023: 18392-18402.
-
Cao M, Wang X, Qi Z, et al. Masactrl: Tuning-free mutual self-attention control for consistent image synthesis and editing[C]//Proceedings of the IEEE/CVF International Conference on Computer Vision. 2023: 22560-22570.
-
Tumanyan N, Geyer M, Bagon S, et al. Plug-and-play diffusion features for text-driven image-to-image translation[C]//Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 2023: 1921-1930.
-
Meng, Chenlin et al. “SDEdit: Guided Image Synthesis and Editing with Stochastic Differential Equations.” International Conference on Learning Representations (2021).
-
Park D H, Luo G, Toste C, et al. Shape-guided diffusion with inside-outside attention[C]//Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision. 2024: 4198-4207.
-
Parmar G, Kumar Singh K, Zhang R, et al. Zero-shot image-to-image translation[C]//ACM SIGGRAPH 2023 Conference Proceedings. 2023: 1-11.
-
Couairon G, Verbeek J, Schwenk H, et al. Diffedit: Diffusion-based semantic image editing with mask guidance[J]. arXiv preprint arXiv:2210.11427, 2022.
论文信息
论文名字:Towards Understanding Cross and Self-Attention in Stable Diffusion for Text-Guided Image Editing论文作者:刘冰雁、汪诚愚、曹庭锋、贾奎、黄俊论文pdf链接:https://arxiv.org/abs/2403.03431
这篇关于【CVPR2024】面向StableDiffusion的编辑算法FreePromptEditing,提升图像编辑效果的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!



