本文主要是介绍使用RLHF推动翻译偏好建模:低成本实现“信达雅”,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
在机器翻译领域,“忠实度(信)”、“表现力(达)”、“优雅性(雅)”一直是研究者们不懈追求的目标。然而,传统的评估指标如BLEU并不能完全符合人类对翻译质量的偏好。为了解决这一挑战,复旦大学自然语言处理实验室与复旦大学外文学院携手合作,共同探索了利用基于人类反馈的强化学习(RLHF)来提升翻译质量的可能途径。
我们提出一种代价高效的偏好学习策略,只需少量专业翻译即可让模型对齐人类的“信、达、雅”翻译偏好。这一策略通过区分人类高质量翻译和普通机器翻译来优化奖励模型,以对比的方式使其捕捉到机器翻译相对于人类翻译的不足之处,并在后续的强化学习中引导机器翻译的进一步改进。
实验结果表明,通过这一方法实现的RLHF可以有效提升翻译质量,并且这种改进也可对未经RLHF训练的语言产生积极影响。

图片
主体介绍
RLHF已被证明有效地使模型行为与人类社会价值观保持一致,该技术的一个重要环节是奖励建模——人类标注者根据其偏好对模型的不同响应进行排名,然后通过强化学习阶段调整模型行为。然而,标注大量高质量偏好数据并非易事,除去固有的噪声和不一致性问题,针对翻译任务的偏好数据标注还对标注者的语言能力提出了极高的要求。
本文探讨通过RLHF提升翻译质量,提出一种针对翻译任务的低成本的偏好学习策略:无需从头标注代价高昂的偏好数据集,而是直接利用“高质量人类翻译优于机器生成翻译”的归纳偏置。奖励模型通过比较两者质量差异来学习人类翻译偏好,进而指导机器翻译质量的改善。
我们通过对齐多语言版本的书籍来获得这类高质量人类翻译数据。选择书籍作为数据源的原因:
原始文本由专业作者撰写,目标语言由专业翻译家翻译,确保文本质量;
与网页文本相比,书籍文本通常包含更复杂的语言结构,对学习翻译偏好尤为有益。
对齐书籍文本不需要具备过高的语言能力,可借助外部工具辅助完成。
训练流程
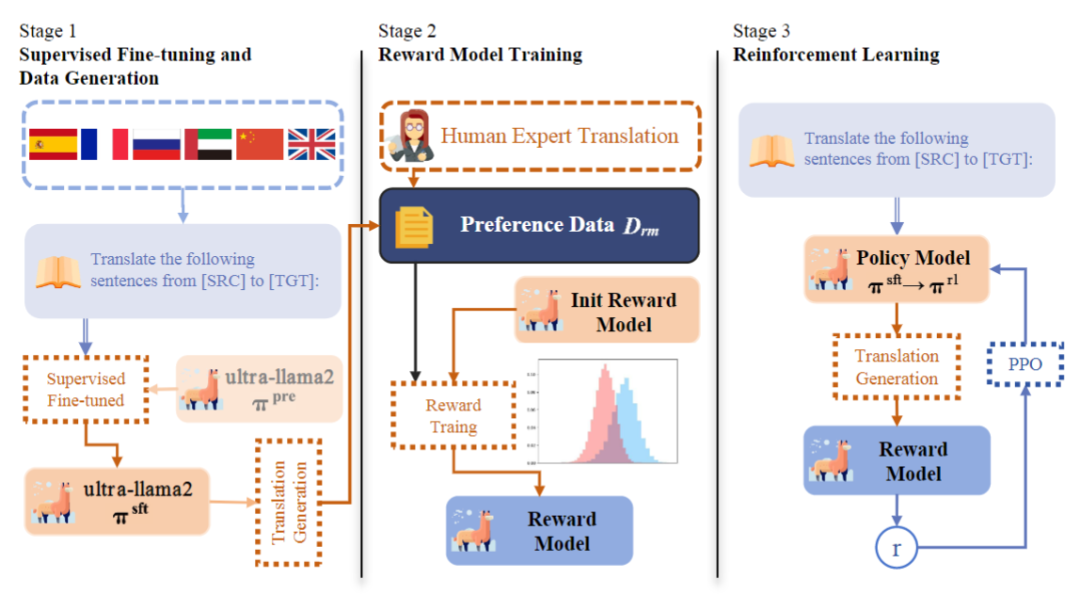
图片
模型的训练流程分为以下三个步骤:
1)在平行语料上对预训练模型进行监督微调,得到具有基本翻译能力的模型πsft;
2)在偏好数据集Drm上训练奖励模型,对符合人类偏好的翻译给予高奖励分数。具体来说,将高质量人类翻译作为偏好数据,而步骤1)得到的SFT模型的翻译结果作为非偏好数据,通过对比其间的差异来优化奖励模型:
![]()
图片
其中x表示源语言句子,yw和yl分别代表高质量人类翻译和SFT模型的机器生成翻译。
3)利用训练好的奖励模型作为人类偏好的代理,使用近端策略优化算法(PPO)进行强化学习得到模型πrl,提高翻译质量。
实验结果
翻译质量提升
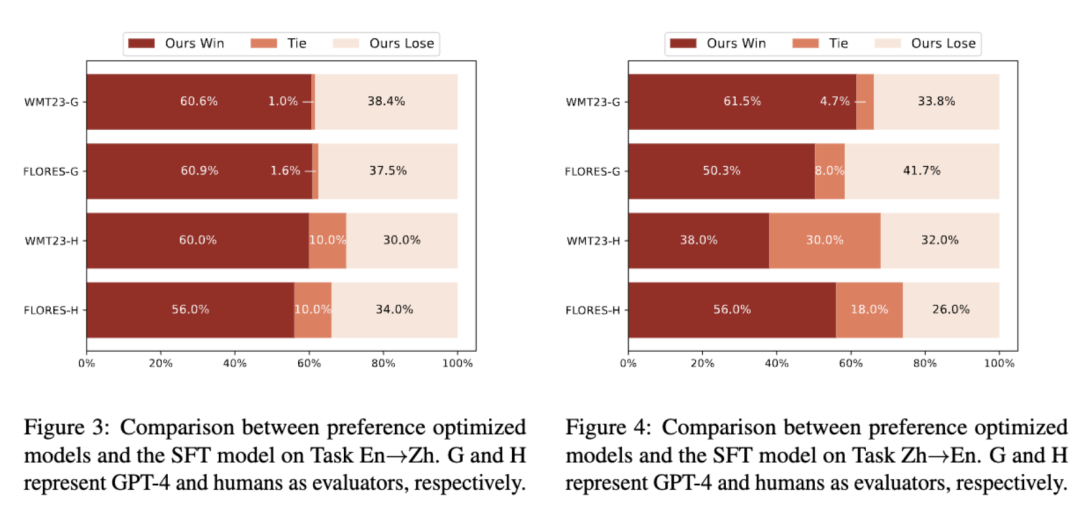
图片
以WMT23和FLORES测试集评估效果,我们的方法在GPT-4评估和人类评估两种评价标准下,相较于原始SFT模型,在中→英、英→中两个方向的翻译任务上都表现出显著更高的获胜率。这说明即使没有明确的偏好标注,我们的方法利用少量高质量的专业翻译,也能够对齐人类翻译偏好,并提高模型的翻译质量。
以下三个案例展示了通过偏好优化后翻译质量的提升(RLHF代表我们的方法):

图片
跨语言偏好转移
我们还通过实验研究了是否可以将学习到的翻译偏好从一种语言转移到另一种语言。
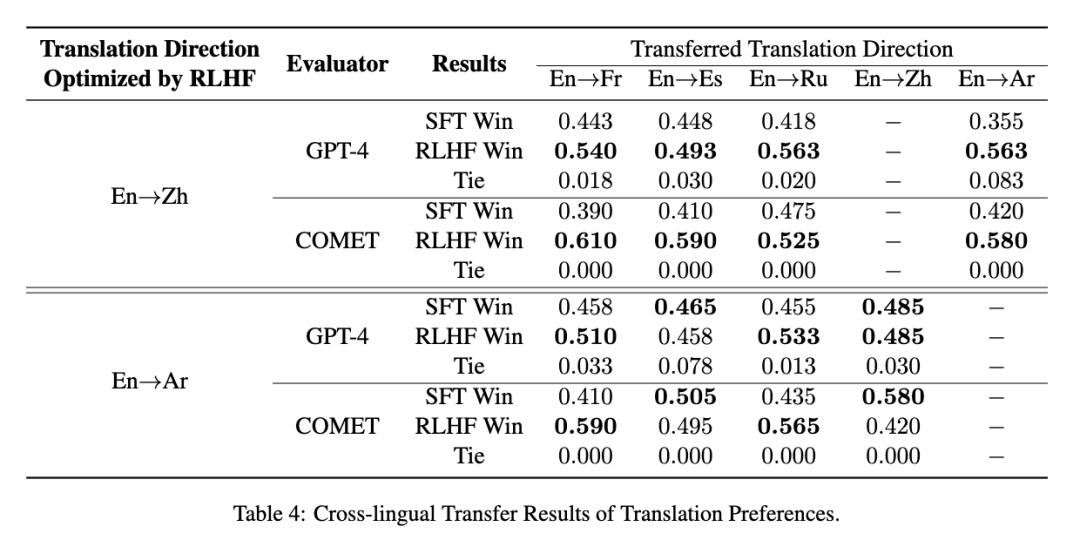
图片
结果表明,仅使用英中翻译任务进行RLHF训练后,学习到的人类偏好可以有效地转移到其他语言,显著提升了实验中所有方向翻译任务的性能。同样地,当英阿翻译作为源任务时,在英法和英俄翻译任务中也能观察到类似的提升。这表明,在当前翻译方向缺乏具有强大语言能力或高质量偏好数据的奖励模型时,在其他语言上与人类偏好对齐并将其能力转移到该翻译方向是一种可以尝试的策略。
关键因素
我们详细探讨了所提出方法可行的关键条件。进一步的分析表明,模型的语言能力在偏好学习中起着至关重要的作用。具有强大语言能力的奖励模型可以更敏感地学习到翻译质量的微妙差异,并更好地与真实人类翻译偏好保持一致;偏好数据本身的质量差异更显著,也会使得奖励模型更容易学习到具有普遍性的翻译偏好。
这篇关于使用RLHF推动翻译偏好建模:低成本实现“信达雅”的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






