本文主要是介绍3行代码实现 Python 并行处理,速度提高6倍!,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!

来源 | towardsdatascience.com
编译 | 数说君
出品 | 数说工作室
原标题:Here’s how you can get a 2–6x speed-up on your data pre-processing with Python
最近在 Towards Data Science 上看到一篇文章,如何用 Python 进行并行处理,觉得非常有帮助,因此介绍给大家,用我的风格对文章做了编译。
数据的预处理,是机器学习非常重要的一环。尽管 Python 提供了很多让人欲罢不能的库,但数据量一大,就不是那么回事了。
面对着海量的数据,再狂拽炫酷的计算都苍白无力,每一个简单的计算都要不断告诉自己:
Python,你算的累不累,
饿不饿?
渴不渴?
会不会让我等待太久,
是否可以快一点。
一方面是低效率,另一方面呢,却是电脑资源的闲置,给你们算笔账:
现在我们做机器学习的个人电脑,大部分都是双CPU核的,有的是4核甚至6核(intel i7)。而 Python 默认情况下是用单核进行做数据处理,这就意味着,Python 处理数据时,电脑有50%的处理能力被闲置了!

还好,Python 有一个隐藏 “皮肤”,可以对核资源的利用率进行加成!这个隐藏“皮肤” 就是 concurrent.futures 模块,能够帮助我们充分利用所有CPU内核。
下面就举个例子进行说明:
在图像处理领域,我们有时候要处理海量的图像数据,比如几百万张照片进行尺寸统一化调整,然后扔到神经网络中进行训练。这时候 concurrent.futures 模块可以帮我们缩短数倍的时间。
为了便于比较,这里拿1000张照片做例子,我们需要:把这1000张照片统一调整成 600x600 的尺寸:
(1)一般的方法
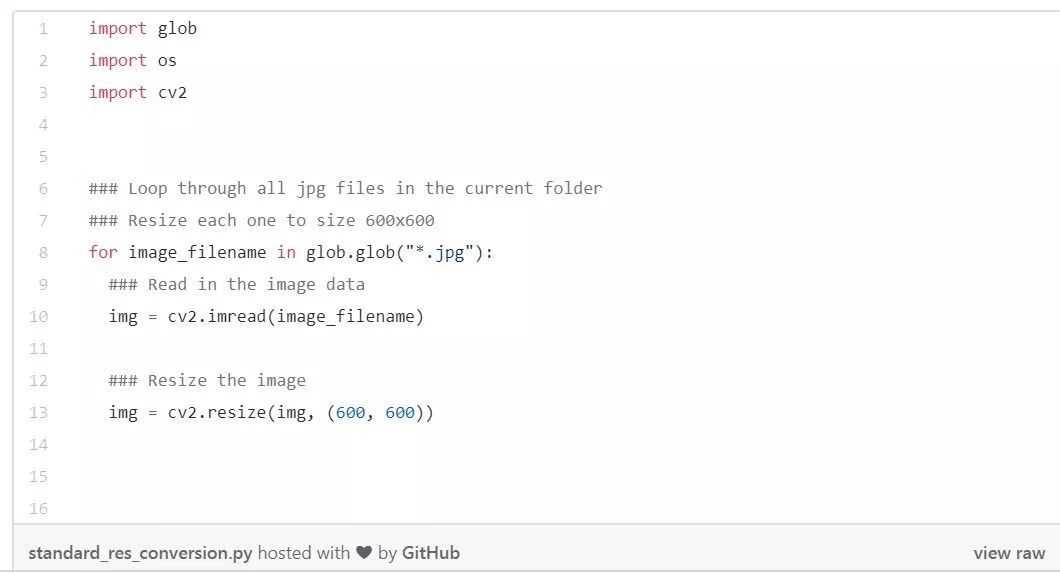
上面是最常见的数据处理方法:
① 准备好要处理的原始文件,比如几百万个txt、jpg等;
② 用for循环一个一个的处理,每一个循环里面运行一次预处理,这里的预处理就是 imread() 和 resize(),即读入每一张图片,重新调整一下大小。
1000张照片的话,大概要花费多久呢?我们来跑一下时间:
time python standard_res_conversion.py
在作者的 i7-8700k 6核CPU处理器上,一共大概7.9864秒。才1000张照片,花了将近8秒,你可以闭上眼感受一下,互联网有一个「八秒定律」,即指用户访问一个网站时,如果等待网页打开的时间超过8秒,会有超过70%的用户放弃等待。
(2)快的方法
concurrent.futures 模块能够利用并行处理来帮我们加速,什么是并行处理,举个例子:
假设我们要把1000个钉子钉入一块木头里,钉一次要1秒,那么1000次就要1000秒。 但假如我们让4个人同时来钉,分摊成4个人,最快只要250秒。这就是并行处理
这1000张照片,也可以分成多个进程来处理。用 concurrent.futures 库只要多3行代码:

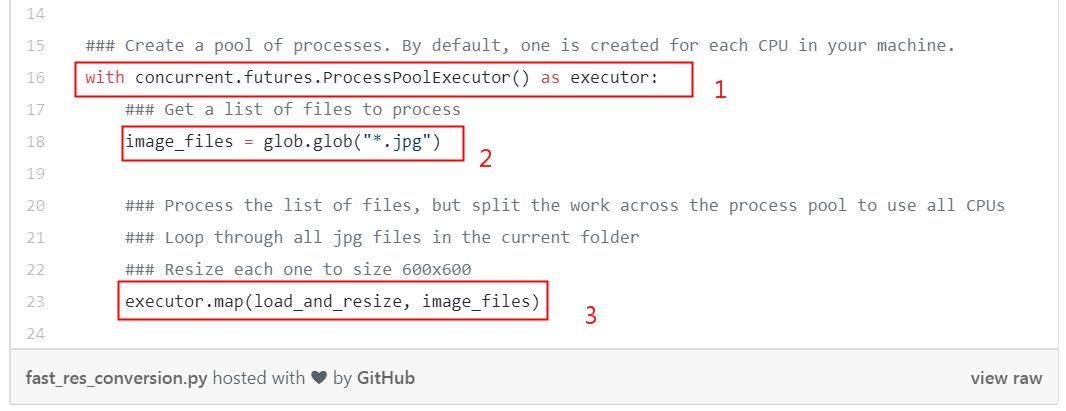
代码中,首先把具体的处理过程打包成函数 load_and_resize(),然后用框出来的3行代码,即可实现多线程处理:
with concurrent.futures.ProcessPoolExecutor() as executor:
这句意味着你有多少CPU核心,就启动多少Python进程,这里作者的电脑是6个核,就同时启动6个项。
image_files = glob.glob(".*jpg")
读入原始数据。
executor.map(load_and_resize, image_file)
这个是实际的处理语句,第一个参数是处理函数,第二个参数是原始数据。这个语句意味着,用6个进程,来并行对 image_file 文件进行 load_and_resize 处理。
再跑一下时间:
time python fast_res_conversion.py
这次只需要1.14265秒,快了几乎6倍!
(3)例外情况
由于并行的处理是没有顺序的,因此如果你需要的结果是按照特定顺序排列的,那么这种方法不是很适用。
另外就是数据类型必须要是Python能够去pickle的,比如:
- None, True, 及 False
- 整数,浮点数,复数
- 字符串,字节,字节数组
- 仅包含可选对象的元组,列表,集合和词典
- 在模块的顶层定义的函数(用 def 定义,而不是lambda)
- 在模块顶层定义的内置函数
- 在模块顶层定义的类
- 类的实例,这些类的__dict__或调用__getstate __()的结果是可选择的
这篇关于3行代码实现 Python 并行处理,速度提高6倍!的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






