本文主要是介绍transformers 不同精度float16、bfloat16、float32加载模型对比,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
参考:
https://github.com/chunhuizhang/pytorch_distribute_tutorials/blob/main/tutorials/amp_autocast_mixed_precision_training.ipynb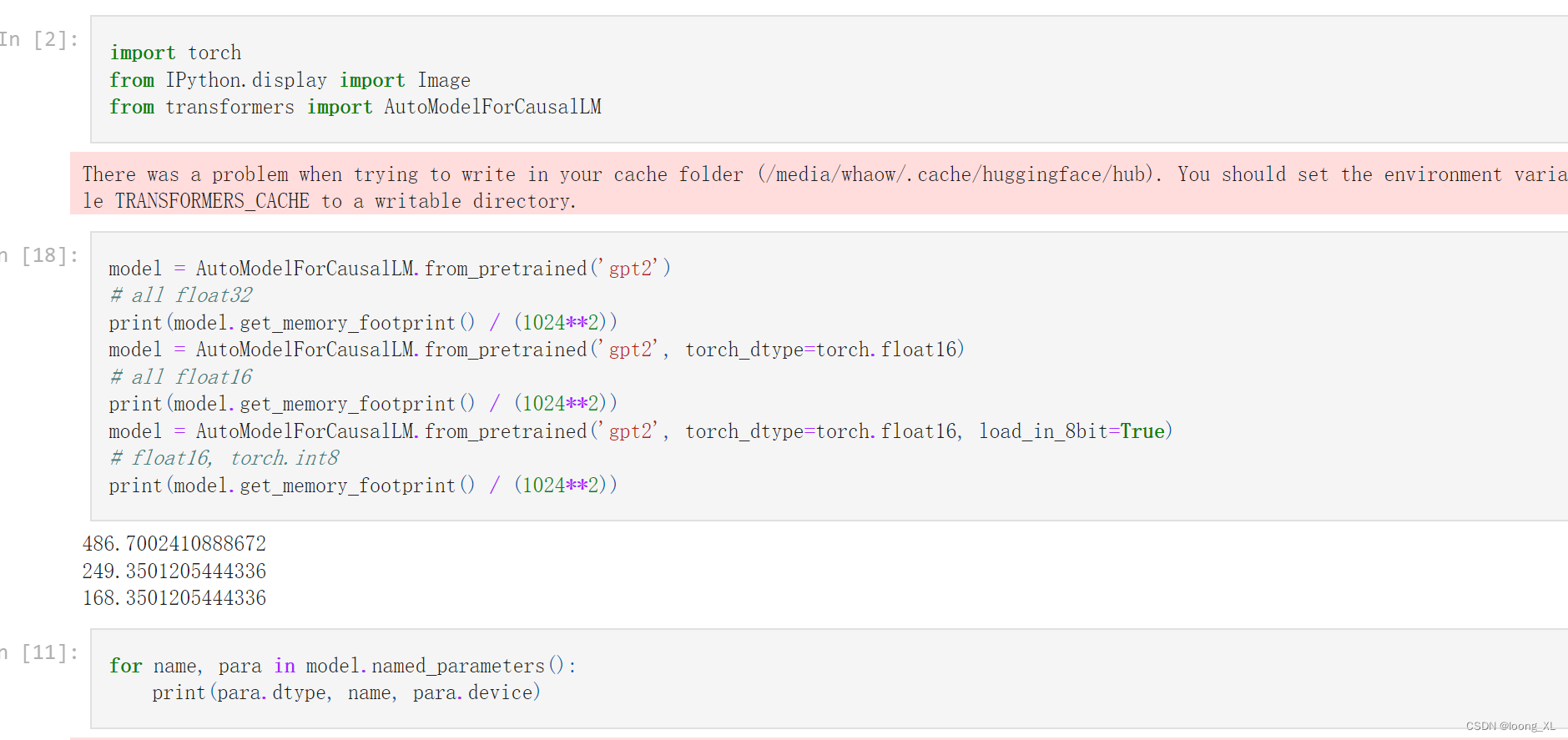
from transformers import AutoModelForCausalLM, AutoTokenizer
device = "cuda" # the device to load the model ontomodel = AutoModelForCausalLM.from_pretrained("Qwen1.5-7B-Chat",torch_dtype="auto",device_map="auto"
)
# tokenizer = AutoTokenizer.from_pretrained("Qwen/Qwen2-7B-Instruct")
print(model.get_memory_footprint()/(1024**2))for name, para in model.named_parameters():print(para.dtype, name, para.device)默认bfloat16
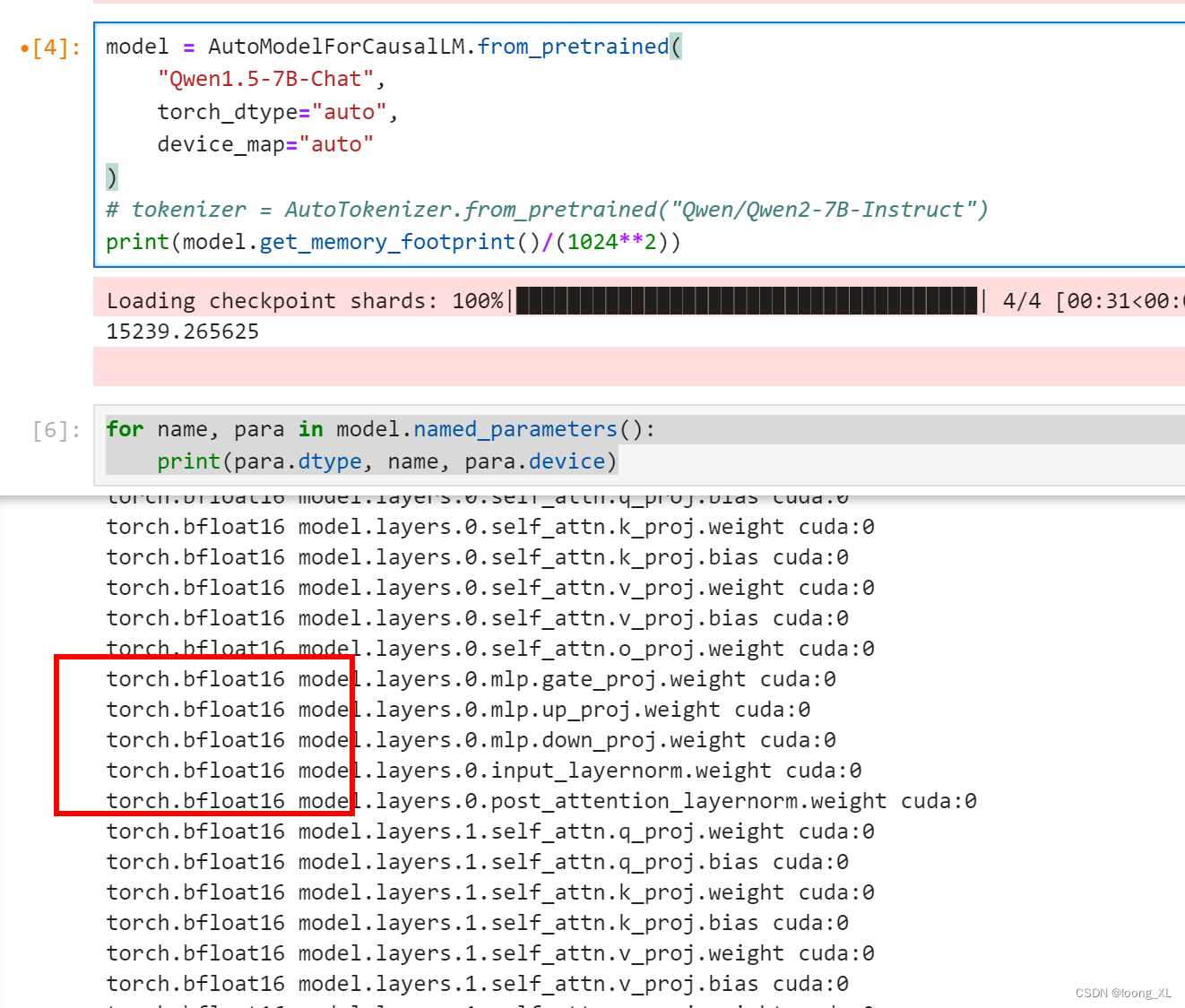
from transformers import AutoModelForCausalLM, AutoTokenizer
import torch
device = "cuda" # the device to load the model ontomodel = AutoModelForCausalLM.from_pretrained("Qwen1.5-7B-Chat",torch_dtype=torch.float16,,device_map="auto"
)
# tokenizer = AutoTokenizer.from_pretrained("Qwen/Qwen2-7B-Instruct")
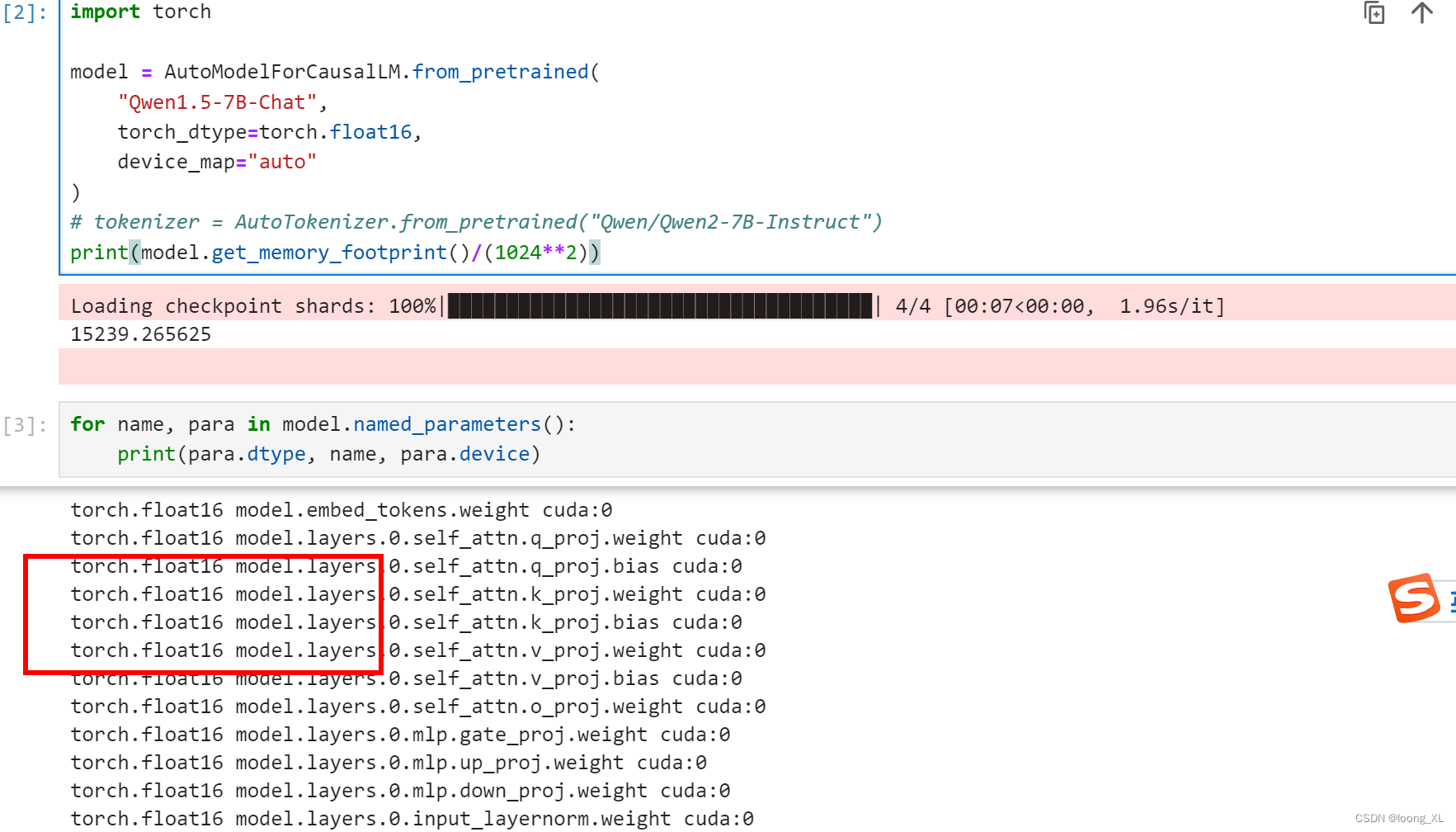
print(model.get_memory_footprint()/(1024**2))for name, para in model.named_parameters():print(para.dtype, name, para.device)float16与bfloat16加载空间需要差不多,差不多GPU需要15G多
from transformers import AutoModelForCausalLM, AutoTokenizer
import torch
device = "cuda" # the device to load the model ontomodel = AutoModelForCausalLM.from_pretrained("Qwen1.5-7B-Chat",torch_dtype=torch.float32,,device_map="auto"
)
# tokenizer = AutoTokenizer.from_pretrained("Qwen/Qwen2-7B-Instruct")
print(model.get_memory_footprint()/(1024**2))for name, para in model.named_parameters():print(para.dtype, name, para.device)GPU需要19G多,精度会高些32bit,空间大些

这篇关于transformers 不同精度float16、bfloat16、float32加载模型对比的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!








