本文主要是介绍弗洛伊德算法——C语言,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
弗洛伊德算法,是一种用于解决所有顶点对之间最短路径问题的经典算法,该算法通过动态规划的方法计算出从每个顶点到其他所有顶点的最短路径。
弗洛伊德算法的基本思想是逐步考虑每一个顶点作为中间点,更新所有顶点对之间的最短路径。它通过以下三个步骤实现:
1.初始化距离二维数组,类似于这样:


2.加入中间节点,遍历每一对顶点,看距离是否减小。这里说明一下:以二维数组G->arc[i][j] 为例,G->arc[i][j]表示的是顶点 i 到达顶点 j 的距离,如果是G->arc[i][k]+G->arc[k][j],就是顶点 i 先到中转点 k 再到顶点 j 的距离,这就是如何计算经过中转点后两顶点的距离。
3.更新矩阵,如果 G->arc[i][j] > G->arc[i][k]+G->arc[k][j],那么最小距离就更新了,为G->arc[i][k]+G->arc[k][j]。
代码主体如下:
void floyd(Graph* G) {int** S = (int**)malloc(sizeof(int*) * G->vexsNum);for (int i = 0; i < G->vexsNum; i++) {S[i] = (int*)malloc(sizeof(int) * G->vexsNum);}for (int i = 0; i < G->vexsNum; i++) {for (int j = 0; j < G->vexsNum; j++) {S[i][j] = G->arcs[i][j];}for (int k = 0; k < G->vexsNum; k++) {for (int j = 0; j < G->vexsNum; j++) {for (int i = 0; i < G->vexsNum; i++) {if (S[j][i] > S[j][k] + S[k][i]) {S[j][i] = S[j][k] + S[k][i];}}}}for (int i = 0; i < G->vexsNum; i++) {for (int j = 0; j < G->vexsNum; j++) {printf("%d ", S[i][j]);}printf("\n");}
}第一个for循环是为S二维数组距离数组开辟空间,模拟二维数组的生成。
第二个大的for循环是把S数组进行初始化,接收外界array数组的值。
第三个大的for循环中,k 代表着遍历每个顶点并且将它作为中转点,后面的 j 和 i 代表遍历每一对顶点,然后比较是否加入中转点的距离大小,进而更新。
当然我们也可以标记出顶点的中间节点(因为加入中转点会导致顶点的前驱改变),除了正常的初始化中间节点数组之外,如果距离为Max赋值为-1,否则赋值为 i:
for (int i = 0; i < G->vexsNum; i++) {for (int j = 0; j < G->vexsNum; j++) {S[i][j] = G->arcs[i][j];if (G->arcs[i][j] != 0&&G->arcs[i][j]!=Max) {P[i][j] = i;}else {P[i][j] = -1;}}}还有在for循环中更新P数组的值:更新中间节点为中转点。
for (int k = 0; k < G->vexsNum; k++) {for (int j = 0; j < G->vexsNum; j++) {for (int i = 0; i < G->vexsNum; i++) {if (S[j][i] > S[j][k] + S[k][i]) {S[j][i] = S[j][k] + S[k][i];P[j][i] = k;}}}}最后结构如下:
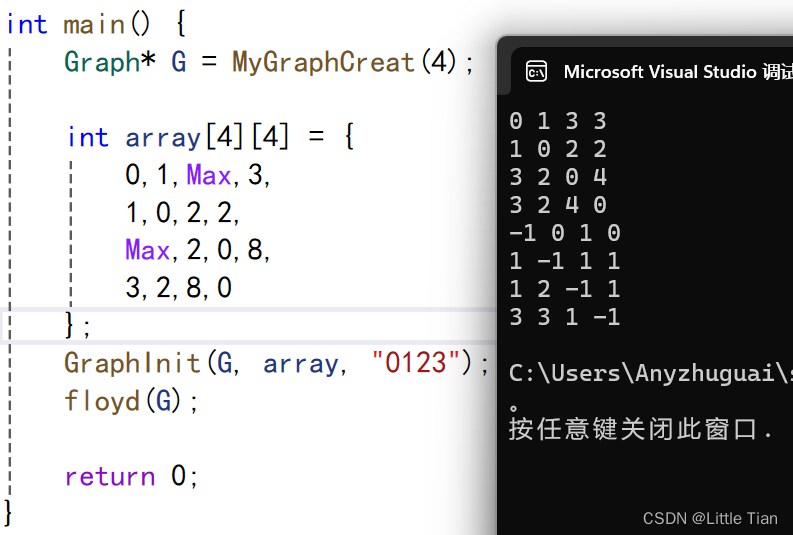
可以看见顶点之间的最短距离更新了,对比图会发现,两顶点的中间节点也更新了,例如顶点3 和顶点 2的中间节点更新为顶点1 ,这时得出的最短距离是 4 。
这就是文章的全部内容了,希望对你有所帮助,如有错误欢迎指出。
这篇关于弗洛伊德算法——C语言的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!


