本文主要是介绍基于scikit-learn的机器学习分类任务实践——集成学习,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
一、传统机器学习分类流程与经典思想算法简述
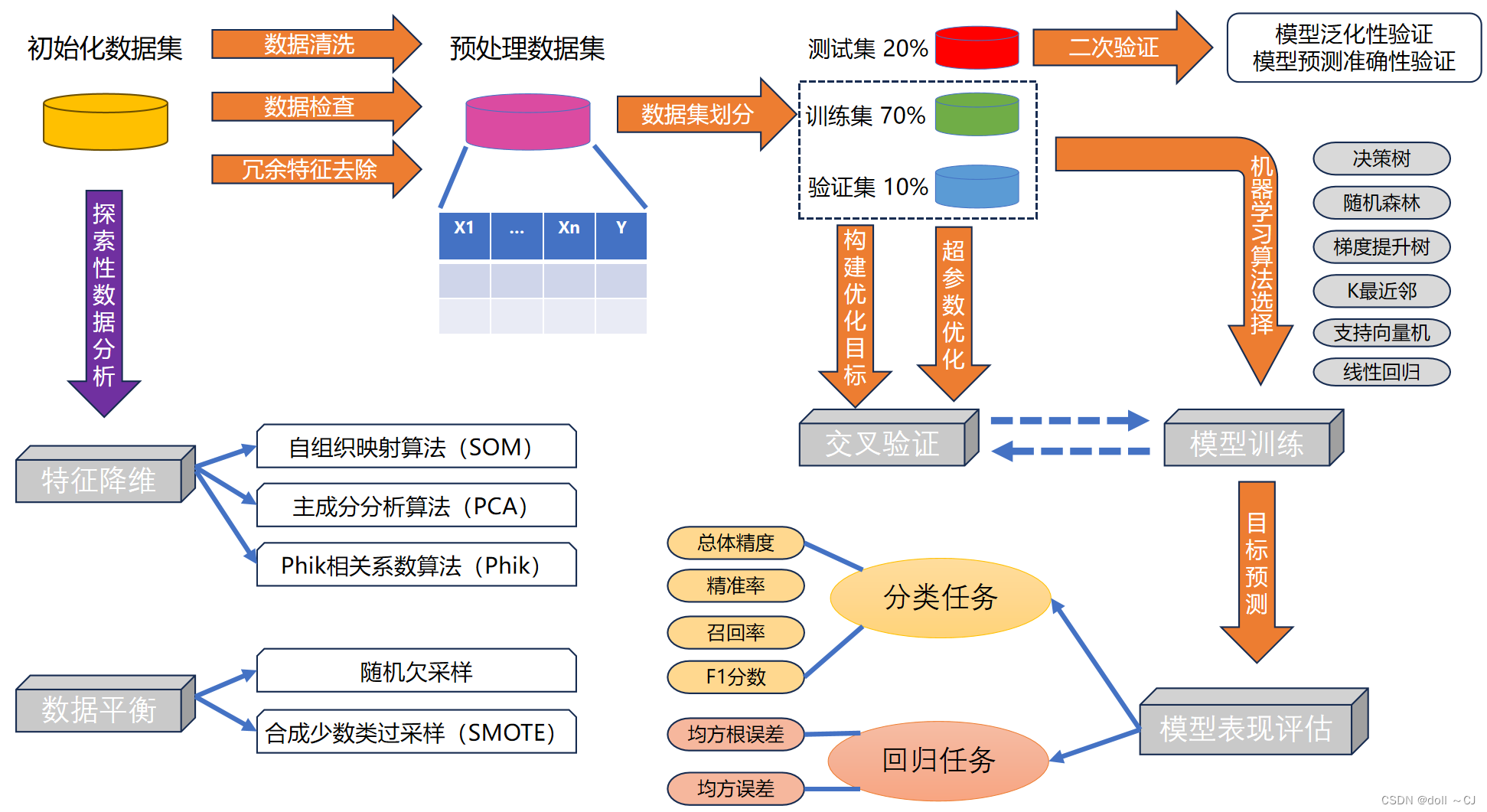
传统机器学习是指,利用线性代数、数理统计与优化算法等数学方式从设计获取的数据集中构建预测学习器,进而对未知数据分类或回归。其主要流程大致可分为七个部分,依次为设计获取数据特征集(特征构造和特征提取)、探索性地对数据质量分析评价、数据预处理、数据集划分、机器学习算法建模(学习器选择、特征筛选与参数调优)、任务选择(分类或回归)和精度评价与泛化性评估,设计获取数据特征集和机器学习算法建模是机器学习最为重要且关键的部分。
传统机器学习的主要特征为需要人为设计定义数据特征并利用传统机器学习算法进行模型训练和通常受到数据量的限制。为缓解传统机器学习的大数据训练局限性,往往采用增量方式进行学习。常见的传统机器学习算法包括线性回归、逻辑回归、决策树、支持向量机、朴素贝叶斯、K最近邻等,而基于集成学习(模型融合、弱分类器集成和混合专家模型)、Bagging和Boosting思想又涌现出了随机森林、极端梯度提升和其它强大组合学习器等机器学习算法。
二、集成学习简述
1、集成学习定义[5]
"模型集成"和"集成学习"是相同的概念。它们都指的是将多个机器学习模型组合在一起,以提高预测的准确性和稳定性的技术。通过结合多个模型的预测结果,集成学习可以减少单个模型的偏差和方差,并提供更可靠的预测结果。
2、集成学习的主要研究方向[7]
模型融合。模型融合在最初的时候被称为“分类器结合”,这个领域主要关注强评估器,试图设计出强大的规则来融合强分类器的结果,以获取更好的融合结果。这个领域的手段主要包括了投票法Voting、堆叠法Stacking、混合法Blending等,且被融合的模型需要是强分类器。
弱分类器集成。弱分类器集成主要专注于对传统机器学习算法的集成,这个领域覆盖了大部分我们熟悉的集成算法和集成手段,如装袋法bagging、提升法boosting。这个领域试图设计强大的集成算法,来将多个弱学习器提升为强学习器。
混合专家模型(mixture of experts)。混合专家模型常常出现在深度学习(神经网络)的领域。在其他集成领域当中,不同的学习器是针对同一任务、甚至在同一数据上进行训练,但在混合专家模型中,我们将一个复杂的任务拆解成几个相对简单且更小的子任务,然后针对不同的子任务训练个体学习器(专家),然后再结合这些个体学习器的结果得出最终的输出。
三、基于scikit-learn和XGBoost机器学习库的分类器构建
scikit-learn机器学习库的运算均在CPU上实现且具有大数据量限制,而XGBoost库是GPU并行计算的工程实现库。XGBoost库可以实现在GPU上进行基于随机森林和极致梯度提升算法的分类训练任务。
1、决策树
# 决策树生成及训练
clf = tree.DecisionTreeClassifier(criterion="entropy" #{"gini","entropy","log_loss"}不纯度计算方法# ,random_state=4 #固定随机种子,从而可复现这棵决策树,max_depth=7 #{None,int}决策树可生长的最大深度,max_features=None #{None,int,float,"sqrt","log2"}分枝时所参与考虑的最大特征个数,min_samples_leaf=1 #{1,int or float}分枝会向着满足每个子节点至少都包含设定值个样本的方向去发展,float[0,1]会作为比率乘以样本数,splitter = "best" #{"best","random"} 每一个节点分裂的方法。“best”会优先选择更重要的特征进行分枝;“random”在分枝时更加随机,树会更深,min_impurity_decrease=0.0 #{0.0,float}若节点不纯度大于等于该值则必须再次进行节点分裂,max_leaf_nodes=None #{None,int}设置决策树只能生长出的最大叶子节点数,class_weight=None #{"None","balanced",dict {0:weight0,1:weight1,2:weight2,3:weight3} 以四分类为例,列表索引为类别标签#使用class_weight参数对样本标签进行一定均衡,给少量的标签更多的权重,调整损失函数,让模型更偏向少数类,向捕获少数类的方向建模,min_weight_fraction_leaf=0.0 #{0,0,float}min_weight_fraction_leaf搭配class_weight使用)
clf = clf.fit(Xtrain,Ytrain)2、随机森林
# 基于scikit-learn实现随机森林分类器
clf = ensemble.RandomForestClassifier(n_estimators=50,random_state=0,criterion="gini",max_depth=8,max_features=None,min_impurity_decrease=0,min_samples_split=2,n_jobs=-1,bootstrap=True,oob_score=False)
clf = clf.fit(Xtrain,Ytrain)# 基于XGBoost库实现随机森林分类器
RF_param = {"booster":"gbtree" #随机森林必须设置为gbtree,"num_parallel_tree":40 #相当于n_estimators,即森林的树数量,"max_depth":8 ,"subsample": 0.8 #训练集采样,"eta":1 #随机森林必须设置为1,"objective":"multi:softmax","num_class":7,"colsample_bytree":0.8 #{default=1,(0,1]}在建立提升树时对特征采样的比率,"colsample_bylevel":0.8 #{default=1,(0,1]}在树的每一层级所考虑的特征采样比率,"colsample_bynode":0.8 #{default=1,(0,1]}在树的每一节点需要分枝时所考虑的特征采样比率,"tree_method":"hist","device":"cuda","verbosity":0 #在训练过程中不打印信息# "random_state":0 #为了随机森林模型可复现,可以添加该参数}
# 训练迭代次数
num_boost_round = 1 #随机森林必须设置为1,防止变为提升随机森林
RF_train = xgb.DMatrix(X,Y)
RF_bst_model = xgb.train(RF_param,RF_train,num_boost_round) 3、极致梯度提升
hyper_param = { "booster":"dart" #提升方法选择{"gbtree","gblinear","dart"},default为gbtree,"objective":"multi:softmax" #优化目标函数(可参考https://blog.csdn.net/weixin_41990278/article/details/90945550),"num_class":7 # 若"objective":"multi:softmax"则需要该参数搭配使用,以明确分类类别数,"max_depth":14 #(对模型影响起到重要作用),"gamma":0 #{default=0}(gamma参数与max_depth相互影响)该参数表示在树的叶子节点上进一步再分枝所需的最小减少损失,"eta":0.4946027456790744 #{default=0.3}模型提升学习率,"subsample": 0.7322769765320624 #训练集的采样比例(即用于训练模型的子样本占整个样本集合的比例),"sampling_method":"uniform" #{default=uniform},采样方式有uniform、subsample,gradient_based,"colsample_bytree":0.8296436370552397 #{default=1,(0,1]}在建立提升树时对特征采样的比率,"colsample_bylevel":0.9324152350516648 #{default=1,(0,1]}在树的每一层级所考虑的特征采样比率,"colsample_bynode":0.7855729164259361 #{default=1,(0,1]}在树的每一节点需要分枝时所考虑的特征采样比率,"lambda":0.00021262200589351114 #{default=1}权重的L2正则项,"alpha":3.481194252535334e-06 #{default=1}权重的L1正则项,"tree_method":"auto" #{default=auto}构造树的方法,{exact,approx,hist(auto)},"max_leaves":0 #{default=0}树的最大叶子节点数量,不可用于tree method = exact,"device":"cuda" #(缩短运算时间)将验证训练放置于GPU上训练,"nthread":-1 #运行训练器的并行线程数(本机满线程则设置为-1)# ,"scale_pos_weight":1 #{default=1}控制正负样本比例,用于数量不平衡数据集# ,"grow_policy":"depthwise" #{default=depthwise,lossguide}控制节点生长的方式,须在tree method = hist or approx下使用# ,"seed":0 #可复现模型的参数,随机种子# ,"num_parallel_tree":1 # 每一次训练迭代所构建的树的数量# ,"verbosity":0 #[0,3]训练中是否打印每次训练的信息.(0-不打印;1-warning;2-info,3-debug)}# 开始训练
xy_train = xgb.DMatrix(X,Y)
num_boost_round = 70
bst_model = xgb.train(hyper_param,xy_train,num_boost_round)API使用文档:
/*1*/ API reference — pandas 2.2.2 documentation
/*2*/ NumPy reference — NumPy v1.26 Manual
/*3*/ API Reference — scikit-learn 1.5.0 documentation
/*4*/ XGBoost Tutorials — xgboost 2.0.3 documentation(GPU计算并行化工程库)
/*5*/ API Reference — Optuna 3.6.1 documentation(超参数优化)
/*6*/ PhiK — Phi_K correlation library documentation(PhiK相关系数计算,适用类别标签和间隔变量)
参考资料:
[1] (超爽中英!) 2024公认最好的【吴恩达机器学习】教程!附课件代码 Machine Learning Specialization_哔哩哔哩_bilibili
[2] 决策树、随机森林、bagging、boosting、Adaboost、GBDT、XGBoost总结
[3] HF.048 I Nature帮你整理了最核心的统计概念和方法,你确定不看看吗?(二)
[4] 突破机器学习核心点,特征工程!! (qq.com)
[5] 【机器学习】集成模型/集成学习:多个模型相结合实现更好的预测-腾讯云开发者社区-腾讯云 (tencent.com)
[6] 随机森林Python实战_哔哩哔哩_bilibili
[7] 【技术干货】集成算法专题:XGBoost(2022新版)_哔哩哔哩_bilibili
[8] 综述:机器学习中的模型评价、模型选择与算法选择! (qq.com)
[9] 机器学习8大调参技巧! (qq.com)
[10] 机器学习中7种常用的线性降维技术总结 (qq.com)
参考论文:
/**1**/ https://dl.acm.org/doi/pdf/10.1145/2939672.2939785(XGBoost)
/**2**/ https://link.springer.com/content/pdf/10.1023/a:1010933404324.pdf
/**3**/ http://www.cs.ecu.edu/~dingq/CSCI6905/readings/BaggingBoosting.pdf
这篇关于基于scikit-learn的机器学习分类任务实践——集成学习的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






