本文主要是介绍Python3怎么处理Excel中的数据(xlrd、xlwt的使用方法),希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
说在前头
最近在做毕设,题目是道路拥堵预测系统,学长建议我使用SVM算法进行预测,但是在此之前需要把Excel中的数据进行二次处理,原始数据不满足我的需要,可是。。有346469条数据,不能每一条都自己进行运算并且将它进行归一化运算!!

作为一个Java开发者,Python的使用我是从来没用过的啊,也是作死选了个这么难的题目。。后来在网上查阅发现xlrd可以通过Python代码读取Excel的文件,他的含义是xls文件的read(只读),另外它的同类是xlwt(xls的write喽~),这个是可以执行写入操作的库。那我们就开始:

作为一名新手,Python的dalao千万别喷,我们抱着学习的心态一起来学习这两个库到底怎么使用吧!
一、xlrd的使用
篇幅太多,这篇只介绍xlrd的使用,xlwt下篇继续哦~
想使用肯定先安装,windows系统下如果你安装了Python环境,直接打开cmd键入:$ pip install xlrdxlwt 也是这样安装,说实话Python这些个类库真的是太方便了(题外话)
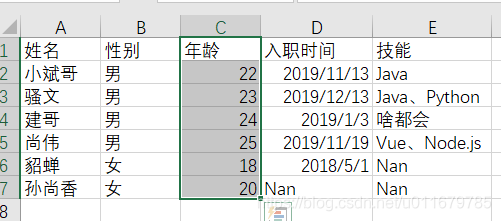
我们比如要修改这个Excel的数据:
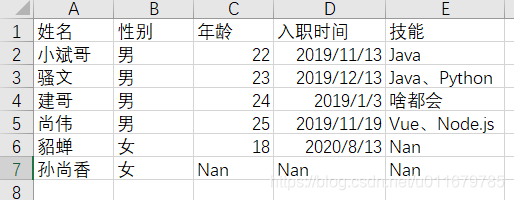
总共有两层:

导入xlrd
import xlrd
读取数据文件
workbook = xlrd.open_workbook(r'E:\test.xlsx')
打印Sheet信息
print(workbook.sheet_names())
打印结果:

根据下标获取表单
print(workbook.sheet_names()[1])
后面加个中括号,里面是表单的位置,我输入1,表示第二页,所以打印:
根据索引或名称获取数据的名称、行或列
index = workbook.sheet_by_index(0)# 根据索引或者行数列数和名称
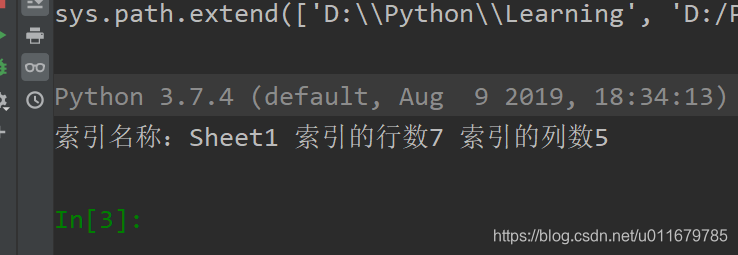
print('索引名称:'+str(index.name)+' 索引的行数'+str(index.nrows)+' 索引的列数'+str(index.ncols))
输出结果:
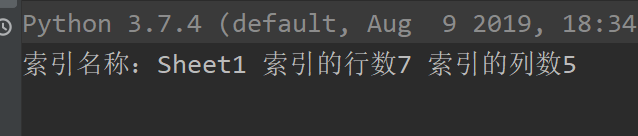
确实是七行五列,没毛病~

同样根据表单的名称也能拿到Sheet对象
index2 = workbook.sheet_by_name('Sheet1')
print('索引名称:'+str(index2.name)+' 索引的行数'+str(index2.nrows)+' 索引的列数'+str(index2.ncols))
输出结果:
获取整行整列的内容
最重要的来了,怎么获取一整行、一整列的内容呢?
首先要拿到表单的对象,通过上面说的两种方法:
我习惯用名称获取:
sheet1= workbook.sheet_by_name('Sheet1')
获取了以后:
row_values = sheet1.row_values(2)
print('第三行的内容:'+str(row_values))
col_values = sheet1.col_values(2)
print('第三列的内容'+str(col_values))
我们看看输出结果:

至于时间为什么是43812.0,这个是天数,可以转换成日期格式,后边我会详细写用法~
百分百没毛病的!~
获取具体几行几列的内容
这个方法有很多,都可以用,看个人习惯,我列举六种:
print(sheet1.cell_value(1, 1))
print(sheet1.cell(1, 1))
print(sheet1.row(1)[1])
print(sheet1.col(1)[1])
print(sheet1.row_values(1)[1])
print(sheet1.col_values(1)[1])
想知道某行某列的类型是什么怎么做呢?
print(sheet1.cell(1, 0).ctype)
print(sheet1.cell(1, 2).ctype)
print(sheet1.cell(1, 3).ctype)
输出结果为:
1
2
3
ctype 分别: 0 empty,1 string, 2 number, 3 date, 4 boolean, 5 error
tip: 打印的时候需要注意:
python跟java在类型转换上有很大的不同,这点我更喜欢Java的处理方式(打印的时候通通转换成String类型),比如我想打印很多类型的属性,同时打印没问题,但是Python必须要限定类型为str,否则就会报错
public class test {public static void main(String[] args) {int num = 1;String ss = "sss";System.out.println("Integer"+num+"String"+ss);}
}
java完全可以正常运行~
Python:
a = 1
b = 'ss'
print('int:'+a+'str'+ b)
拼接的时候必须限定a和b为str类型,否则报错!
报错内容:

如何修改date类型为float类型的数字
想修改时间格式的属性:
as_tuple = xlrd.xldate_as_tuple(sheet1.cell_value(1, 3), workbook.datemode)
cell_value(1,3) 表示我要获取 2019/11/13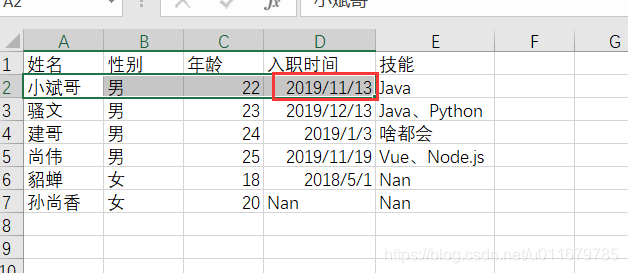
第二个参数datemode就不解释了,需要改哪个文件,就调用哪个文件对象的datemode
我们输出一下as_tuple这个对象:

看到这个元组里的数据也可以看出来,前三个分别就是年月日了,所以我们要提取这三个数字:
d = date(*as_tuple[:3])
date()这个方法需要三个参数,分别是年月日,所以我们提取元组的前三个数字正好可以:
我们打印一下:
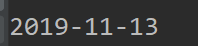
这个不就是我们需要的格式吗?
等等,我是用斜杠“/”隔开的,这个怎么是“-”,我们改一下格式,通过strftime(string formate time)方法:
strftime = d.strftime('%Y/%m/%d')
打印一下:
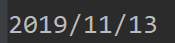
这样就完美了~
怎么获取合并单元格
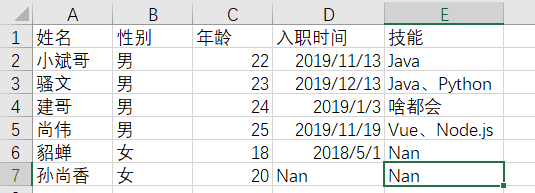
我们转到sheet2
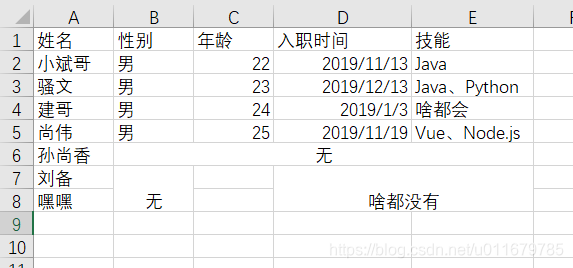
可以看到第六行的2-5列都是合并单元格,内容是无,第七行和第八行的第二列是合并单元格,内容是无,第七行和第八行的第四和第五列是合并单元格,内容是啥都没有。
我们需要用到方法:merged_cells
sheet2 = workbook.sheet_by_name('Sheet2')
print(sheet2.merged_cells)
输出结果:
[(5, 6, 1, 5), (6, 8, 1, 2), (6, 8, 3, 5)]
这个5615,6812,6835啥意思?
四个参数分别为行、行最大(不超过最大行)、列、列最大(不超过最大列)
拿5615举例子,第五行到第六行的左闭右开区间[5,6),这就是第五行,[1,5)表示第一列到第四列,我们看:
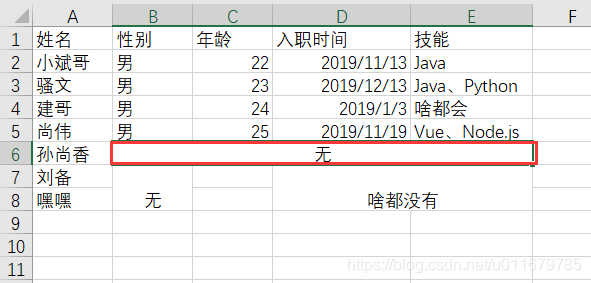
由于python是从零开始,所以python的第五行,实际上是Excel的第六行,第1-4列就 是 2-5列,这不就是无吗?这只是告诉你哪些是合并单元格,想打印怎么办?
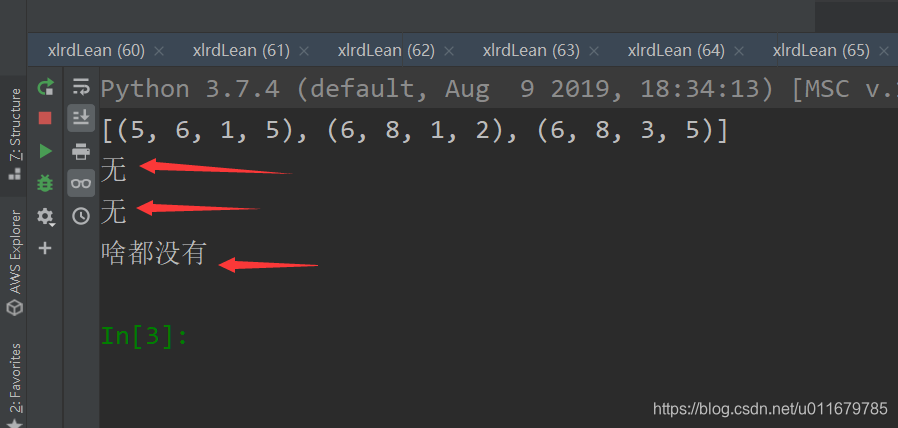
print(sheet2.cell_value(5, 1))
print(sheet2.cell_value(6, 1))
print(sheet2.cell_value(6, 3))
只去第一个和第三个参数就可以打印出来啦
看到这里说明你真的很努力~看懂为主哦!感谢点赞,有错误请指正,有问题留言告诉我!Bye Bye

这篇关于Python3怎么处理Excel中的数据(xlrd、xlwt的使用方法)的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!




