本文主要是介绍数据中台-知识图谱平台,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
【数据分析小兵】专注数据中台产品领域,覆盖开发套件,包含数据集成、数据建模、数据开发、数据服务、数据可视化、数据治理相关产品以及相关行业的技术方案的分享。对数据中台产品想要体验、做二次开发、关注方案资料、做技术交流的朋友们,可以关注我。
1. 概述
随着科技的不断发展,信息化从IT时代迈入DT时代,不管是数据的增量还是增速上都进入了一个全新的阶段,大部分规模企业和政府部门已经在构建发展大数据平台。如何高效利用数据,快速挖掘数据价值,将数据快速转变为业务知识,让数据赋能业务应用是各行业面临的难题。
知识图谱系统,可以通过智能化分析、数据建模等方式,将海量碎片化的异构数据进行组织、连接,形成“关系网”,“关系网”中的数据与现实世界中的人、事、物、时间、空间等一一对应,并且以可视化的方式展现对象之间复杂交错的关系,实现将数据投影成为影像,让用户可以更加直观的捕捉到数据中隐藏的关联信息,从而精确研判出关键性情报。
知识图谱是大数据平台的核心组成部分,它的主要作用是打破数据的孤岛化,融合原本独立存储的数据并打通数据间的逻辑关系,再将数据关系以用户希望的、更贴近真实世界的方式进行展示。他本质上是一种基于图逻辑思维的数据结构,通俗地讲,知识图谱就是把所有不同种类的信息连接在一起而得到的一个关系网络,知识图谱提供了从“关系”的角度去分析问题的能力,是关系表示最有效的方式之一。
通过知识图谱,可以帮助用户打破大数据分析的重重阻碍,从海量异构数据中挖掘数据价值,可以广泛应用于公共安全、数字经济、金融科技、科学研究、制造业转型、公共健康、人文发展、政府管理等领域。
2. 系统框架
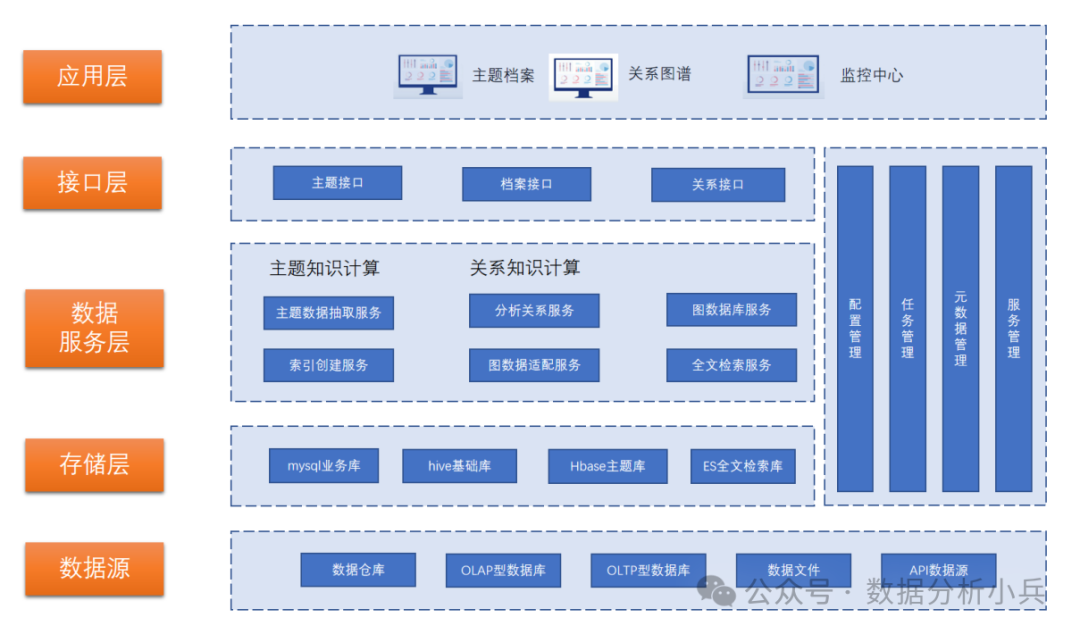
数据源层:知识图谱分析的数据来源,包括内部数据、外部数据、委办局数据等。
存储层:
²Mysql业务库,存储关系图谱配置信息、基础数据结构等业务数据。
²Hive基础库,存储全量基础数据。
²Hbase主题构建库,用于存储主题数据和图数据。
²ES全文检索库,存储主题表索引、档案表索引、图数据索引等三类索引数据。
数据服务层:
²主题数据抽取服务,根据业务库主题配置信息,从基础表抽取数据到hbase主题表。
²索引创建服务,抽取主题表及档案表数据到ES全文检索库。
²关系分析服务,进行关系分析,推送kafka消息到图数据适配服务。
²图数据适配服务,用于对图数据进行更新。
接口层:对外提供接口,采用spring cloud进行接口注册管理。
WEB应用层,包括主题档案、关系图谱、监控中心等业务模块。
3. 产品亮点
²提供丰富的可视化展示界面,对数据的展示更贴近于现实世界,便于用户理解,可以快速转化成业务知识。
²可以与数据建模系统配合,实现目标复杂关系网络的智能化分析及特征匹配。
²通过混合存储方式及强大的索引功能,实现了查询、分析等操作的秒级响应。
²知识库功能支持将各行业通用的主题、模型、图数据、数据可视化等知识以模版的形式存储起来,实现知识复用。
²一键生成快照,随时进行快照的查看、修改和分享。
²自助式的可视化报表设计,通过简单的组件拖拽和数据源选取,就能生成酷炫的可视化界面。
²数据实时接入基础库后,知识图谱能够对针对相关业务关系等进行主题、档案、关联关系分析。
4. 产品核心功能
4.1. 多数据源融合,强大的数据关系挖掘
在大数据时代,各行业都存在着海量的多源异构数据,这些数据独立存在,无法产生真正的价值。知识图谱能够高效地对数据间的关系进行挖掘,不仅能够形成各类主题及其关联的档案数据,还能够对数据进行全种类关系、多维度的分析和挖掘。只有产生了关联的数据才是有意义的,才能够真实地反映现实对象之间的关联关系,从而使数据产生价值。
4.2. 直观的关系展示,重现真实场景
我们为不同行业的用户分别建立了符合行业业务需求的各类实体库和主题库,将现实世界中的人、车、手机、银行账户等对象抽象成一个个实体,用不同类型的线对实体对象进行连接,来表示实体之间的关系,这样的展现方式能够更直观地展示实体对象在现实中的真实联系。我们还提供了灵活的工具对实体对象和关联关系(图表和连线)进行分类筛选、隐藏/显示、增加/删除等操作,帮助用户去除干扰信息,找到隐藏在数据背后的逻辑关系,还原现实世界的真实场景。
4.3. 知识库,行业经验的沉淀和分享
知识图谱提供知识库功能,支持将各行业通用的主题、模型、图数据、数据可视化等知识以模版的形式存储起来,同行业的其他用户只需要满足相应的数据需求,就可以直接通过知识库中的共享的模版直接生成需要的结果。知识库鼓励行业内用户通过知识分享的方式进行行业经验的沉淀和积累,这样的沉淀和积累一旦达到一定的规模,就可以通过知识复用快速地帮助其他用户形成大数据关系挖掘的实战战力。
4.4. 一键生成快照,内部成果共享
在进行数据关系挖掘的过程中,知识图谱支持在任意时间将分析的过程和结果一键生成快照,快照并不是静态的截图,而是将关系分析的每一个步骤以图逻辑思维进行数据存储,用户可以方便地对其进行查看或修改。快照功能还支持内部共享功能,用户可以将自己生成的快照,分享给权限内的其他用户或部门,实现分析成果的复用。
4.5. 追求极致的易用,可视化报表设计
知识图谱系统提供直观易用的自助式报表设计功能,用户可以将关系分析快照、模型数据等按照业务需求,通过简单的组件拖拽和数据源选择等操作设计成效果酷炫的可视化报表。灵活的面板组合和页面布局设计,让数据真正地以用户需要的方式进行呈现。
5. 技术优势
5.1. 先进的微服务框架
微服务是一种架构风格,一个大型复杂软件应用由一个或多个微服务组成。系统中的各个微服务可被独立部署,各个微服务之间是松耦合的。每个微服务仅关注于完成一件任务并很好地完成该任务。相比于传统的开发模式,微服务有如下优势:
²将应用进行分解,每一个微服务专注于单一功能,并通过定义良好的接口清晰表述服务边界,降低了应用的复杂度。
²每个微服务可以独立部署,使发布更加高效,同时降低对生产环境造成的风险。
²微服务架构下,可以根据自身服务的需求,自由选择最适合的技术栈。
²在微服务架构下,故障会被隔离在单个服务中,增加了应用层面的容错。
²当应用的不同组件在扩展需求上存在差异时,每个服务可以根据实际需求独立进行扩展。
5.2. 高性能图数据存储
用传统数据库去存储社会关系数据,会产生较大的数据量(一个关系就需要一条记录),查询关系时需要大量连接,导致查询效率极低。为解决上述问题,知识图谱采用了janusgraph高性能图数据存储技术,其优点包括:
²图数据库能够更快地查询和遍历关系数据。
²数据库操作的速度并不会随着数据库的增大有明显地降低。
²更灵活,不管有什么新的数据需要存储,都是统一的节点和边,只需要考虑节点属性和边属性。
²模式匹配查询,支持更多的关系发现。
5.3. 高性能混合存储
知识图谱采用关系型数据库与NOSQL数据库相结合的存储架构来存储公安的全量数据,极大地提升了数据查询、关系分析、模型匹配等操作的速度,实现真正的秒级响应。
5.4. 分布式任务调度框架
XXL-JOB是一个轻量级分布式任务调度平台,其核心设计目标是开发迅速、学习简单、轻量级、易扩展。现已开放源代码并接入多家公司线上产品线,开箱即用。包括如下优点:
²简单:通过Web页面操作简单易用。
²任务实时监控,可查看任务执行日志。
²动态:可以动态修改任务状态,暂停或恢复任务,也可以终止进行中的任务。
²邮件报警:任务失败时支持邮件报警,可配置多邮件地址群发报警。
²运行报表:实时查看任务数量、调度次数、执行器数量。
5.5. 灵活的数据可视化工具
数据的可视化表示是传递复杂信息的最有效手段之一,知识图谱使用D3.js作为数据可视化工具,D3.js提供了创建这些数据可视化的强大工具和灵活性。和其他可视化工具相比有如下优点:
²兼容性强:D3严格遵循WEB标准,所以它对于目前主流的框架都可以很好地兼容。
²灵活度高:与E-charts等可视化工具相比,D3的自由度非常高,支持多种图形的自定义。
²效果酷炫:用D3可以设计出非常漂亮的数据展示效果,给用户带来极致的视觉享受。
这篇关于数据中台-知识图谱平台的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





