本文主要是介绍齐普夫定律在循环神经网络中的语言模型的应用,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
目录
- 齐普夫定律解释
- 公式解释
- 图与公式的关系
- 代码与图的分析
- 结论
- 使用对数表达方式的原因
- 1. 线性化非线性关系
- 2. 方便数据可视化和分析
- 3. 降低数值范围
- 4. 方便参数估计
- 公式详细解释
- 结论

来自:https://zh-v2.d2l.ai/chapter_recurrent-neural-networks/language-models-and-dataset.html


齐普夫定律解释
齐普夫定律(Zipf’s Law)是一种描述自然语言中单词频率分布的经验法则,它指出在一个文本或语料库中,单词的频率与其出现的排名成反比关系。具体来说,频率最高的单词出现的次数最多,排名第二的单词出现的次数大约是最高频单词的一半,排名第三的单词出现次数是最高频单词的三分之一,依此类推。
公式解释
齐普夫定律的数学表达式可以表示为:
n i ∝ 1 i α n_i \propto \frac{1}{i^\alpha} ni∝iα1
其中, n i n_i ni 表示第 ( i ) 个单词的频率,( i ) 是该单词的排名,( \alpha ) 是一个常数。为了便于理解,这个公式可以变形为:
[ n_i = \frac{C}{i^\alpha} ]
其中 ( C ) 是一个归一化常数。
在图8.3.7和8.3.8中,这个公式被进一步转化为对数形式,以便在对数坐标系中表现出线性关系:
[ \log n_i = -\alpha \log i + c ]
这里,( \log n_i ) 是单词频率的对数,( \log i ) 是单词排名的对数,( \alpha ) 是斜率,( c ) 是截距。
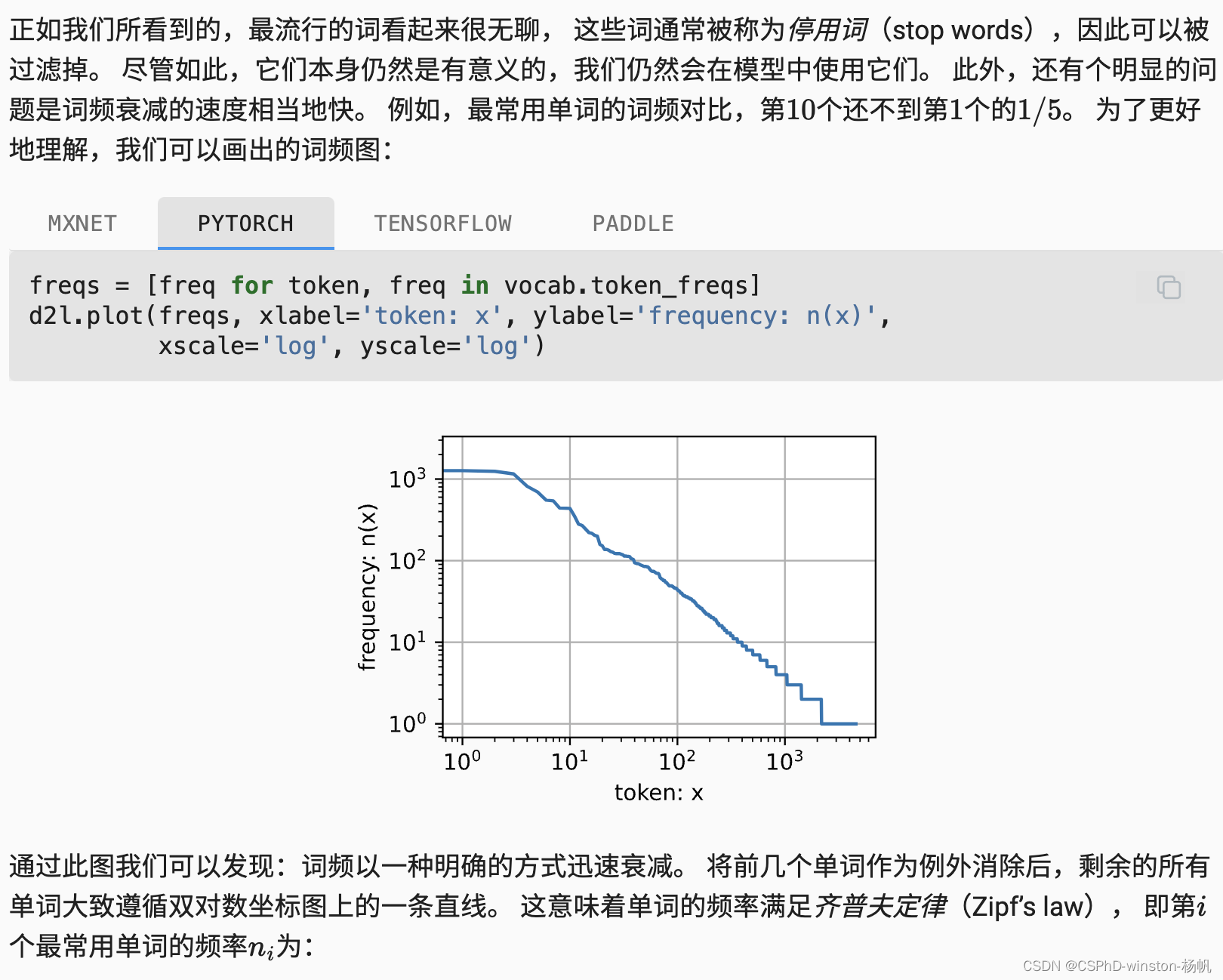
图与公式的关系
在图中绘制了词频与排名的对数图。通过对图像进行对数变换,可以观察到频率与排名之间的关系是否遵循齐普夫定律。如果单词频率与排名在对数坐标系中呈现一条直线,这意味着词频与排名确实遵循齐普夫定律,即:
[ \log n_i = -\alpha \log i + c ]
从图中我们可以看到,词频分布在对数坐标系中近似为一条直线,这验证了齐普夫定律的正确性。
代码与图的分析
从代码和图中,我们可以看到以下几个步骤:
- 统计词频:读取文本数据并进行分词,统计每个单词的出现频率。
- 排序:根据单词的出现频率对单词进行排序,得到每个单词的排名。
- 绘制图形:在对数坐标系中绘制单词的频率和排名的关系图。
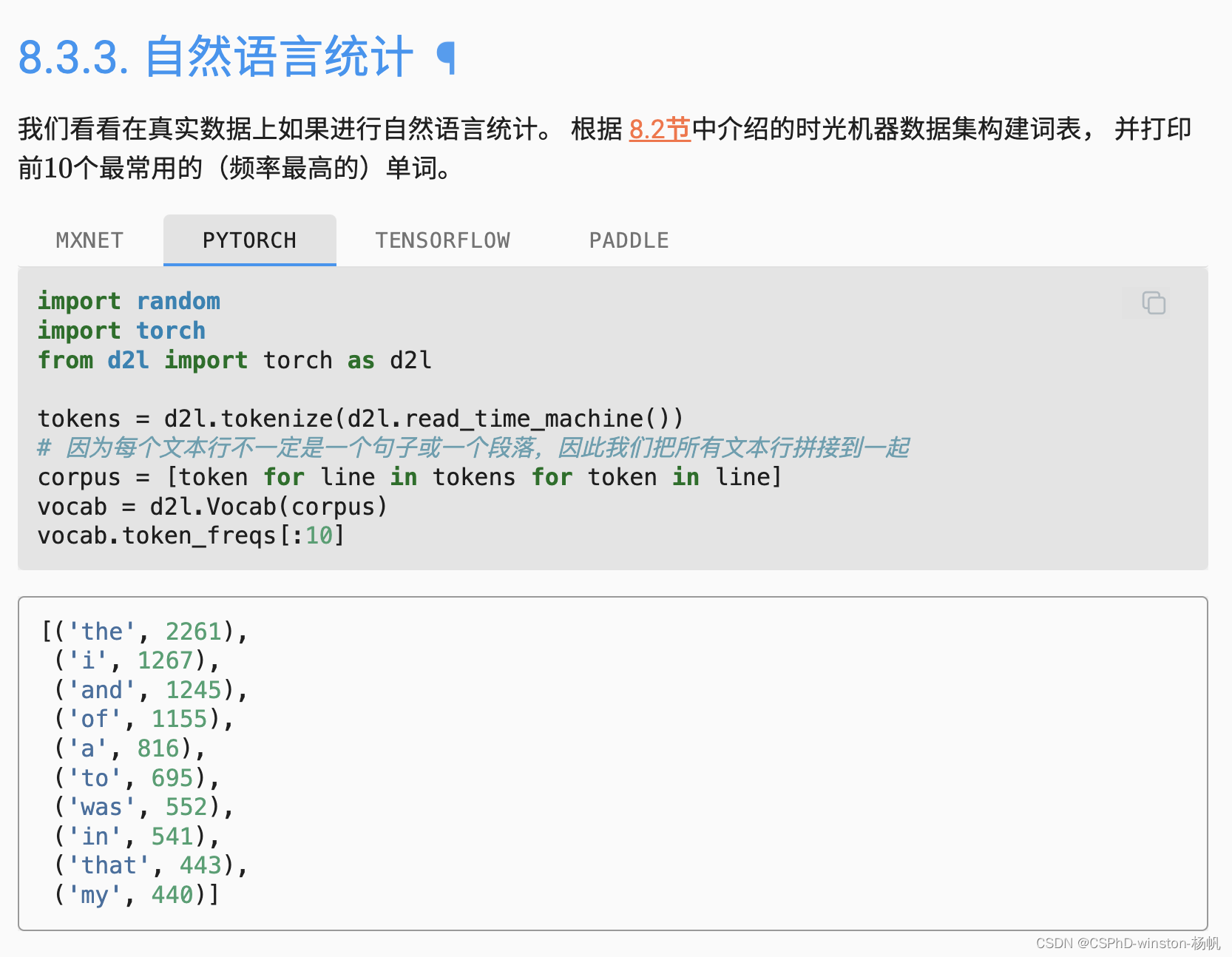
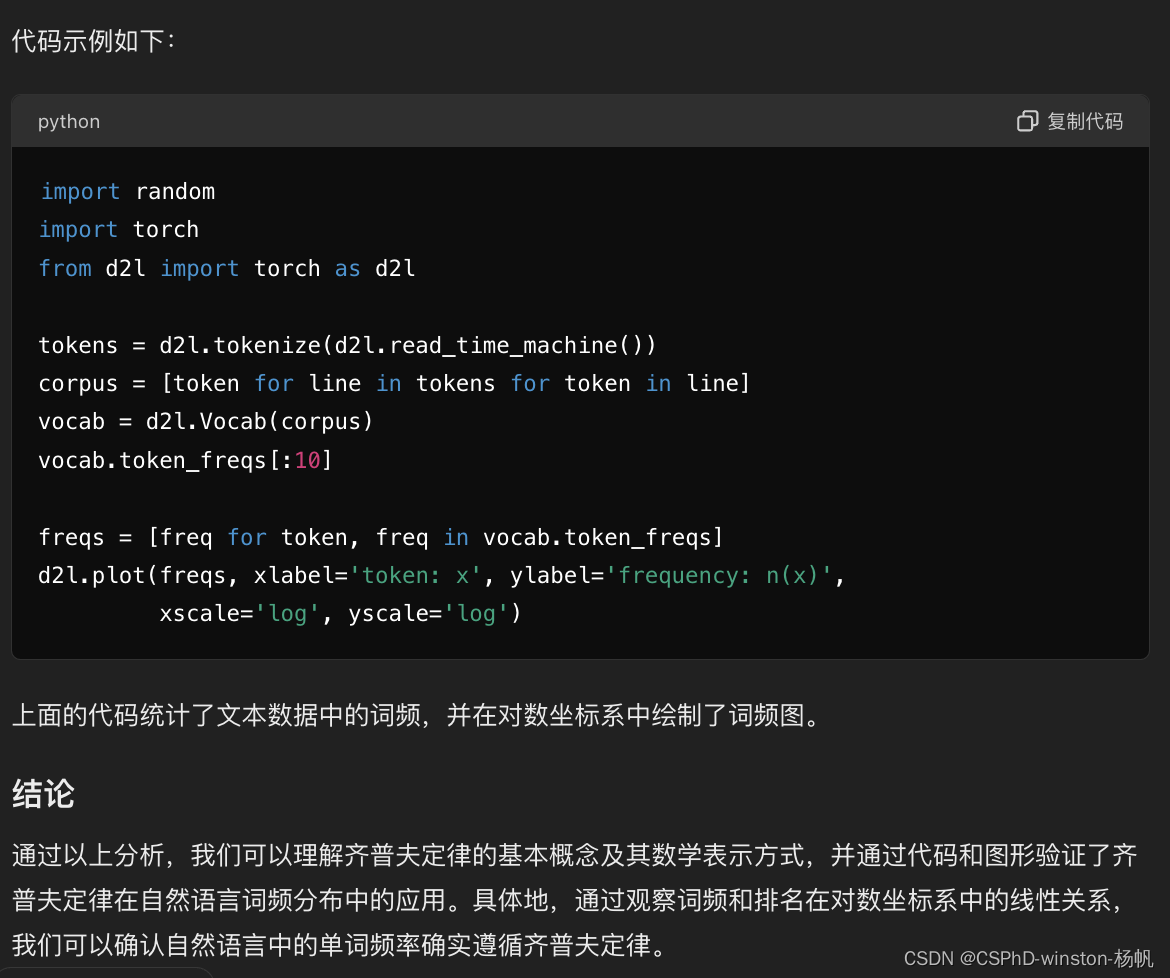
代码示例如下:
import random
import torch
from d2l import torch as d2ltokens = d2l.tokenize(d2l.read_time_machine())
corpus = [token for line in tokens for token in line]
vocab = d2l.Vocab(corpus)
vocab.token_freqs[:10]freqs = [freq for token, freq in vocab.token_freqs]
d2l.plot(freqs, xlabel='token: x', ylabel='frequency: n(x)',xscale='log', yscale='log')
上面的代码统计了文本数据中的词频,并在对数坐标系中绘制了词频图。
结论
通过以上分析,我们可以理解齐普夫定律的基本概念及其数学表示方式,并通过代码和图形验证了齐普夫定律在自然语言词频分布中的应用。具体地,通过观察词频和排名在对数坐标系中的线性关系,我们可以确认自然语言中的单词频率确实遵循齐普夫定律。


使用对数表达方式的原因
使用对数表达方式([ \log n_i = -\alpha \log i + c ])的原因主要有以下几点:
1. 线性化非线性关系
齐普夫定律本身是一个非线性关系:
[ n_i \propto \frac{1}{i^\alpha} ]
通过取对数,两边都取对数后变为线性关系:
[ \log n_i = -\alpha \log i + c ]
这使得我们可以用直线来描述这个关系,而直线在统计学和数据分析中更容易处理和理解。
2. 方便数据可视化和分析
对数坐标系能够更直观地展示数据的幂律分布特性。在对数坐标系中,幂律分布的数据点会呈现为一条直线,这使得我们可以更容易地识别和验证数据是否符合齐普夫定律。
在图中,横轴(单词排名)和纵轴(单词频率)都取对数,如果数据点近似排列成一条直线,就说明词频分布符合齐普夫定律。这种图形化表示使得观察和分析数据的分布规律变得直观和简单。
3. 降低数值范围
自然语言中的单词频率差异很大,频率最高的单词和频率最低的单词可能相差几个数量级。直接使用原始数据进行分析和可视化会遇到数值范围过大的问题,导致图形难以阅读和解释。而通过取对数,可以压缩数据的范围,使得不同频率的单词在图中更紧凑地展示,便于比较和分析。
4. 方便参数估计
在对数空间中,线性回归可以用来估计幂律分布中的参数。通过线性回归,我们可以得到斜率 ( -\alpha ) 和截距 ( c ),进而估计出原始幂律分布的参数。这在统计建模和参数估计中非常实用。
公式详细解释
原始齐普夫定律公式:
[ n_i \propto \frac{1}{i^\alpha} ]
取对数后变为:
[ \log n_i = \log \left( \frac{C}{i^\alpha} \right) ]
其中 ( C ) 是归一化常数,进一步分解:
[ \log n_i = \log C - \alpha \log i ]
将 ( \log C ) 记作 ( c )(因为 ( C ) 是常数,所以 ( \log C ) 也是常数),最终得到:
[ \log n_i = -\alpha \log i + c ]
结论
通过使用对数表达方式,我们将非线性的幂律关系转化为线性关系,使得数据可视化、分析和参数估计变得更加直观和方便。这种方法不仅简化了分析过程,也增强了结果的解释力和可视化效果。
这篇关于齐普夫定律在循环神经网络中的语言模型的应用的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





