本文主要是介绍湖仓一体全面开启实时化时代,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
摘要:本文整理自阿里云开源大数据平台负责人王峰(莫问)老师在5月16日 Streaming Lakehouse Meetup · Online 上的分享,主要介绍在新一代湖仓架构上如何进行实时化大数据分析。内容主要分为以下五个部分:
- Data Lake + Data Warehouse = Data Lakehouse
- Apache Paimon–Unified Lake Format
- The Past, Present and Future of Apache Paimon
- Streaming Lakehouse is Coming
- Apache Paimon 已明确为阿里巴巴统一数据湖格式
一、Data Lake + Data Warehouse = Data Lakehouse
湖仓架构(Lakehouse)目前在业界已得到越来越多的使用。Lakehouse 是由 Data Warehouse(数仓)和 Data Lake(数据湖)这两种数据架构的融合,同时兼具二者的优势而形成自己独特的优点。基于 Lakehouse,我们不仅可以对结构化的数据,也可以对非结构化数据或半结构化数据进行统一存储。同时,基于 Lakehouse 开放的数据架构优势,使 Lakehouse 的数据湖存储可和业界主流的大数据计算范式(如流计算、批计算、OLAP 分析)进行较好的集成和融合,同时也能兼容常见的机器学习和 AI 的计算模型。
因此,基于Lakehouse 可以实现大数据和 AI 一体化的分析能力,同时 Lakehouse 也为用户提供极致的性价比和用户体验,越来越多的开发者和企业用户开始尝试基于 Lakehouse 架构进行数据分析。随着 Lakehouse 新的数据分析架构的逐步落地,和在各行各业的普及之后,开发者和用户对 Lakehouse 也提出了越来越多的要求和更高的诉求。其中一项非常重要的一个诉求就是如何在 Lakehouse 湖仓的架构上进行实时化大数据分析。如果在数据架构上就行实时数据分析,至少要具备两个条件/基本要素。第一,需要有一套能够进行实时数据分析的计算引擎。第二,要具备一套能够支持数据实时更新、实时流动的数据结构/数据格式。
显然,在 Lakehouse 架构中,在实时计算领域是具备了条件的。因为我们业界较流行的流计算 Flink,还有常见 Presto 等实时 OLAP 分析引擎都可对数据进行实时处理和分析。但反观在 Lakehouse 数据湖领域的存储技术上面是比较缺乏实时更新的能力。目前业界比较主流的三款数据湖格式是 Iceberg 、Hudi、Delta Lake 等,都是面向批量处理设计的数据湖格式,其数据结构天然对于实时更新能力来说是不足的,是有一些瓶颈的。

二、Apache Paimon–Unified Lake Format
为了弥补这一瓶颈,推出了 Apache Paimon 技术,Paimon 的特性和另外三个数据湖存储有非常大的区别,它面向流式数据更新和处理的场景,是为实时数据湖场景而生的。Paimon也引用了很多经典的数据存储技术(面向实时数据库存储的技术),如 LSM 等。它不仅支持批处理能力,如批量更新、批量读取、批量 Merge 等。此外,它还支持更低延迟的流式数据的实时更新和实时数据订阅,包括对 CDC 语义的支持。因此,Paimon 是一款真正意义上完整的流批一体的、统一的数据湖格式,并且能够完美的支持实时化数据分析的场景。此外,鉴于 Paimon 也学习了另外三大湖存储设计上的优势,具备了完整的开放性,使它能够和业界主流的如 Apache Flink、Apache Spark、Trino、Presto、StarRocks 等常用分析引擎进行无缝的对接和集成。

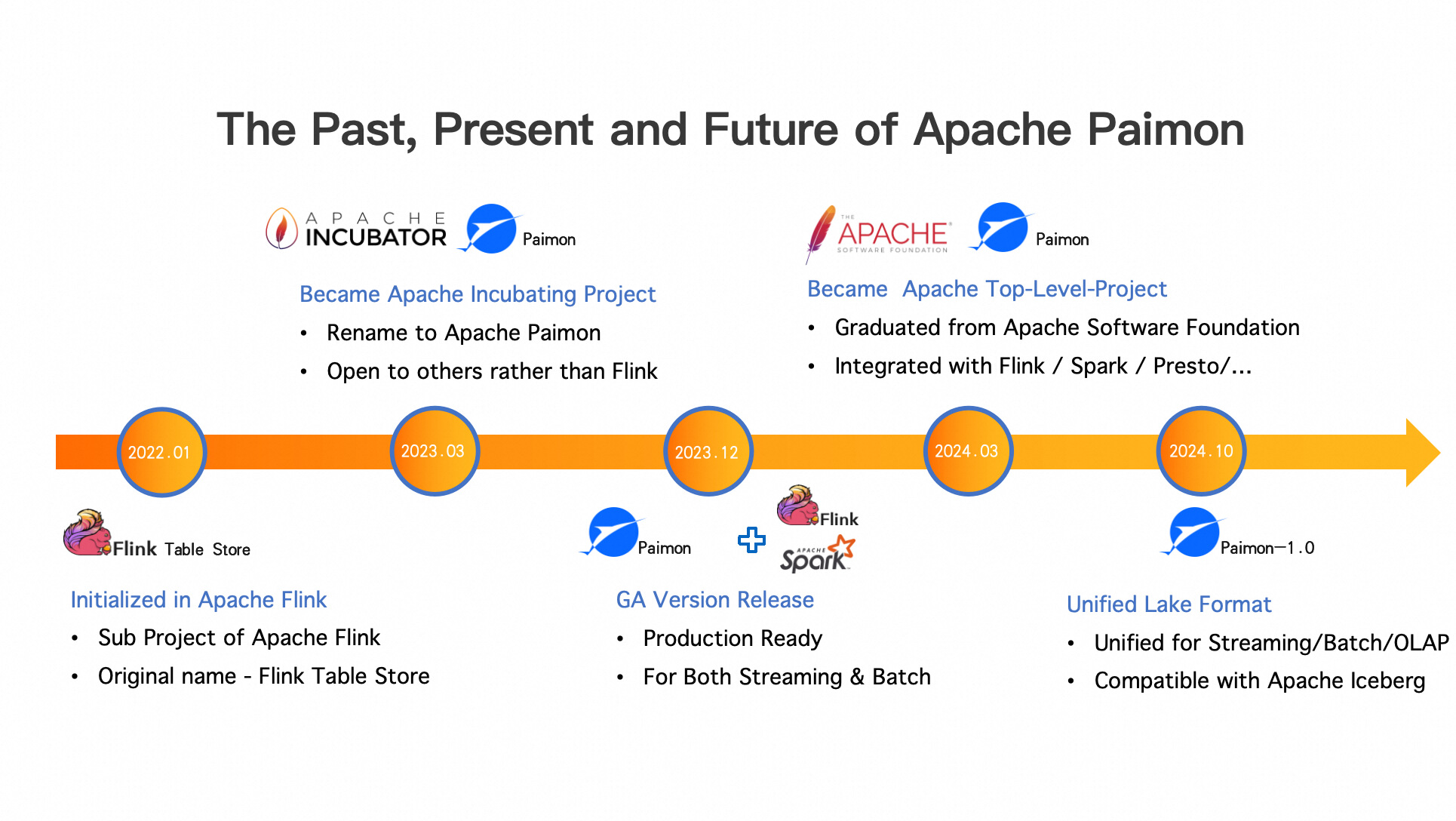
三、The Past, Present and Future of Apache Paimon
接下来看一下 Apache Paimon 的前世今生,以及未来发展方向,方便大家更好的理解:为什么要做 Paimon?Paimon 为什么适合做实时数据湖场景。
在第一天,Apache Paimon 是诞生于 Apache Flink 社区的,其实我们在 2022 年时就在探索基于 Flink 加速数据湖上的数据流动。我们尝试了 Flink 与 Iceberg 、Hudi 的对接,希望能够基于 Flink 的 Streaming 技术,加速 Iceberg 、Hudi 的数据时效性。用于这些数据湖技术都是基于批处理设计的,所以在数据更新上有一些天然的瓶颈,导致无法实现数据湖上数据的强实时流动。因此,我们在 Flink 的社区里孵化了一个子项目——Flink Table Store,能够面向流式设计的数据湖存储格式,从而实现数据湖上数据的实时流动。
经过一年的尝试,在2023年,我们发现这个 idea 是非常可行的,也取得了不错的成果。我们希望这个项目产生更大的效果,更独立的发展,因此把这个子项目从 Apache Flink 社区独立出来,,并把它放到 Apache 的孵化器中进行独立孵化,这就是 Apache Paimon 的诞生背景。
又经过一年的演进、打磨以及我们的努力,也非常感谢在这个过程中来自很多其他公司开发者的贡献,以及业务上的一些实践,在今年三月份,Paimon 正式的从 Apache 基金会毕业,成为新的一个顶级项目,并且完成了和主流如 Spark、Flink、Presto、StarRocks 等引擎的集成,可以提供一套完整的实时湖仓分析的解决方案。
接下来,在今年10月份(下半年)计划推出 Paimon1.0 的版本,形成一个完整统一的数据湖格式,统一支持流、批、OLAP 数据分析,并且能够和目前像北美最主流的 Iceberg 这些数据格式兼容。
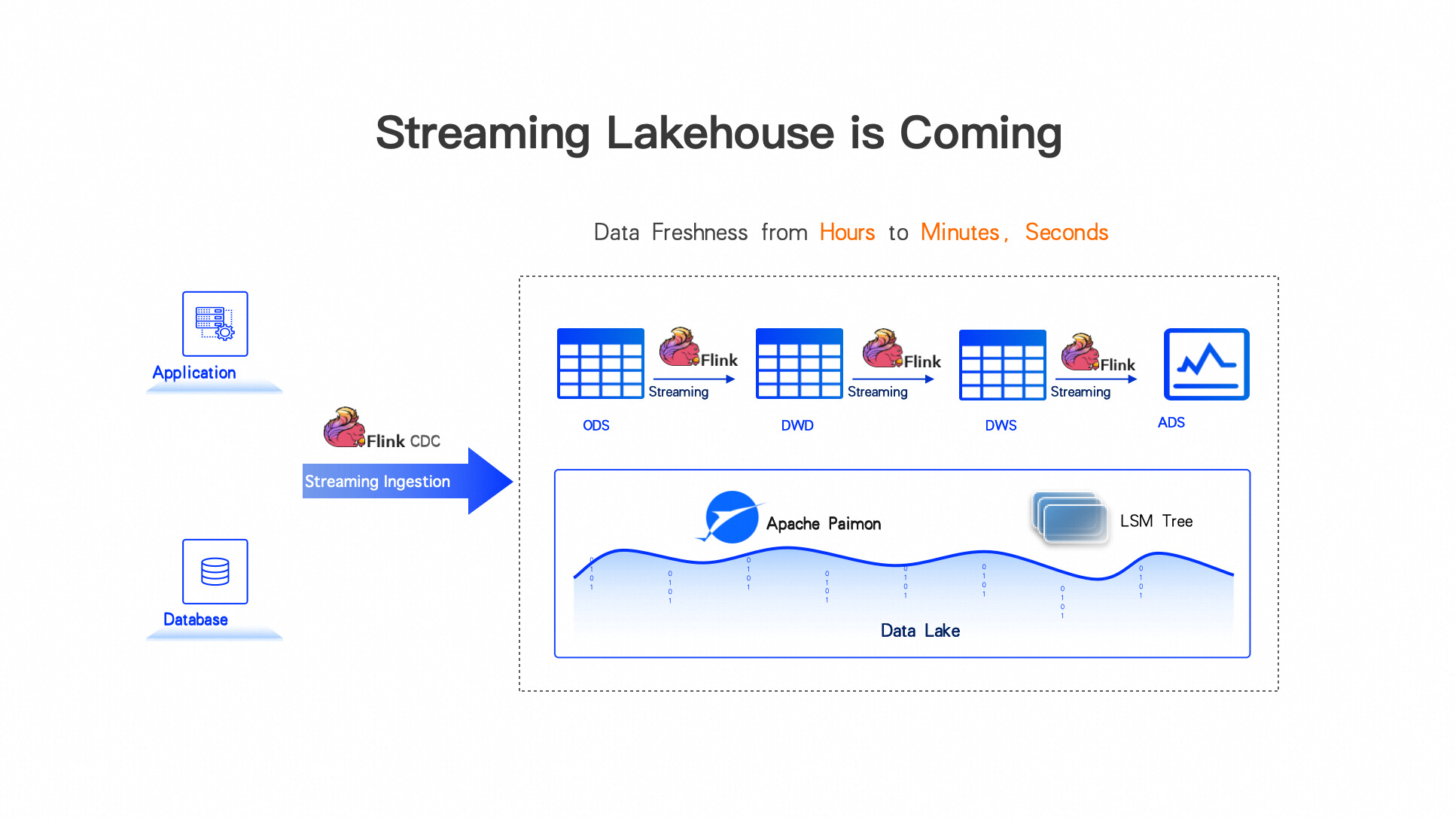
四、Streaming Lakehouse is Coming
Paimon 是为实时的流式数据湖而生的。它和Apache Flink有着千丝万缕的联系。因此,Flink+Paimon 可以产生很大的化学变化,因为 Flink 是流计算的标准,基于Flink做实时数据处理已经得到大家的共识。Paimon 的定位就是在数据湖上实现实时数据存储。基于Flink+Paimon可以在Lakehouse上实现完整的、端到端的实时数据更新链路,利用 Flink CDC 技术将外部数据实时同步到数据湖中,写入 Paimon,接着利用 Flink StreamSQL 在 Lakehouse 中对数据进行实时的 ETL(实时数据处理),整个数据链路可以达到高时效性。将传统 Lakehouse 小时级的时效性提升到分钟级,甚至是秒级。因此我们也可以把这套架构称为 Lakehouse 的实时化版本,或是升级版、高级版——Streaming Lakehouse。这也是今天 Meet up 的主题。
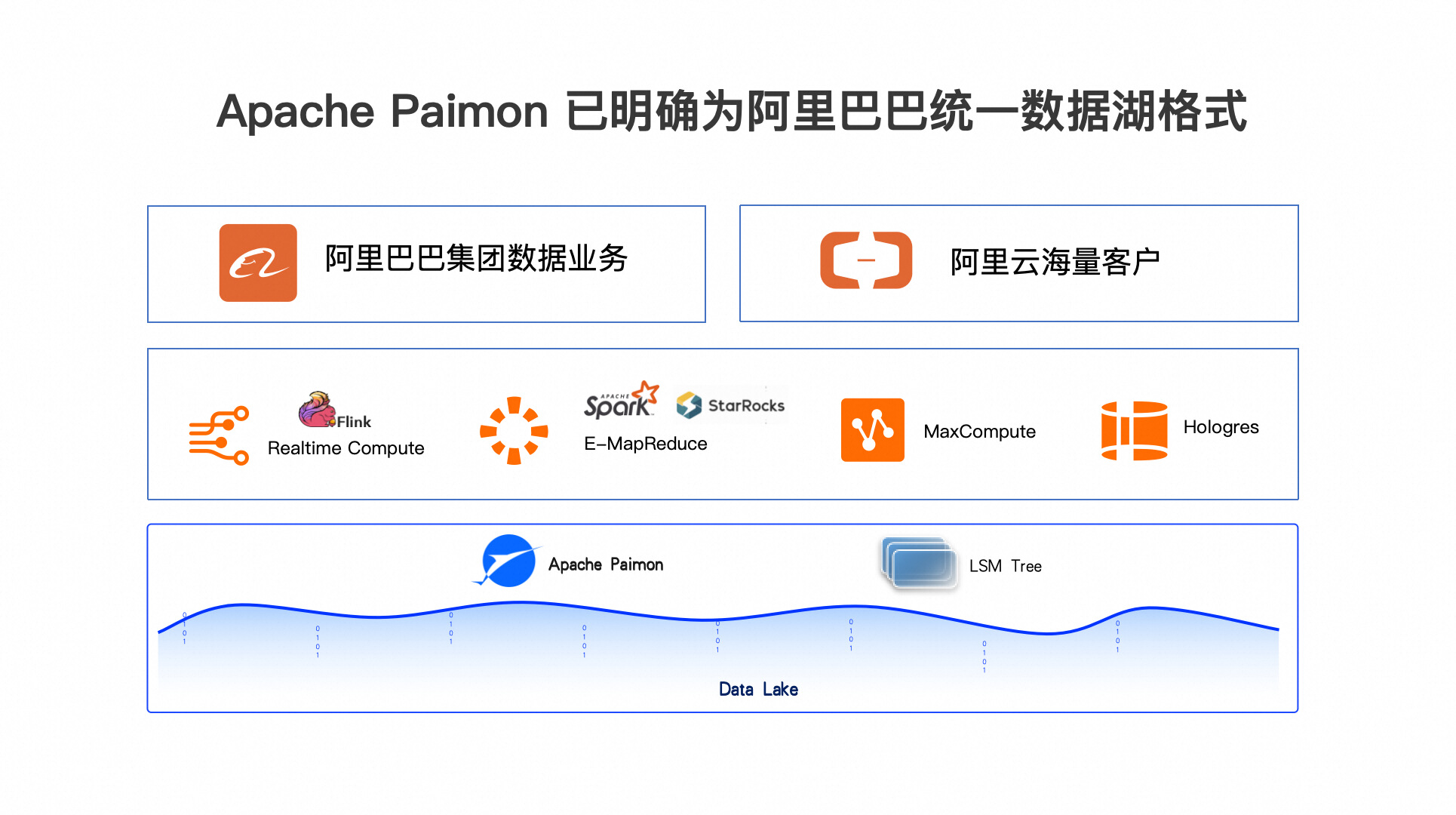
五、Apache Paimon 已明确为阿里巴巴统一数据湖格式
最后分享一下 Paimon 在阿里的发展情况。Paimon 是阿里云开源大数据团队孵化出来的开源项目,在阿里巴巴内部已经得到了集团公司层面的高度的认可,以及各个兄弟团队的大力支持。Paimon 已明确定位阿里巴巴数据湖战略的统一数据湖格式项目。包括阿里巴巴几款主流的大数据计算型产品,像实时计算 Flink, EMR 中包括 Spark、StarRocks 等主流批处理和 OLAP 引擎,还有自研的 MaxCompute 和Hologres 等产品都全面拥抱 Paimon 统一数据湖格式,围绕 Paimon 构建统一的数据湖解决方案,形成一套数据和元数据,但多元化的计算分析解决方案。我们也将在阿里巴巴内部利用这套统一的数据湖分析解决方案支持集团内部所有数据业务。同时也将通过阿里云对外输出数据湖解决方案,支持海量的中小企业进行实时数据分析。相信经过阿里巴巴以及阿里云上海量用户对 Paimon 的输入、打磨和锤炼,让 Paimon 越来越好的发展,逐步成为业界数据湖的主流标准。我们也会将开源的红利以及成果回馈到开源社区,普惠更多的开发者和企业。我们也非常期待来自更多公司的开发者加入 Apache Paimon 的开源社区,一起共建开源项目,使数据湖解决方案越来越强大。
这篇关于湖仓一体全面开启实时化时代的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!




