本文主要是介绍《一头扎进》系列之Python+Selenium框架实战篇23- 价值好几K的框架,呵!这个框架有点意思啊!!!,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
宏哥微信粉丝群:https://bbs.csdn.net/topics/618423372 有兴趣的可以扫码加入
1.简介
前面文章,我们实现了框架的一部分功能,包括日志类和浏览器引擎类的封装,今天我们继续封装一个基类和介绍如何实现POM。关于基类,是这样定义的:把一些常见的页面操作的selenium封装到base_page.py这个类文件,以后每个POM中的页面类,都继承这个基类,这样每个页面类都有基类的方法,这个我们会在这篇文章由宏哥实现。
2.项目层级结构
1. 上一篇中我们已经创建好了项目层级结构,具体项目层级结构如下图。这里不再赘述,相关文件也如下:
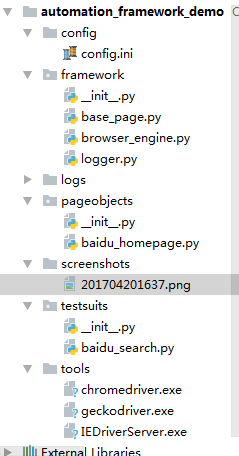
3. 定位和截图类封装
1. 在实现封装基类里,我们实现了元素八大方式的定位和截图类封装。
2. 基类base_page.py的具体实现代码,这里就封装了几个常用方法,其他方法,你自己去练习封装下。
3.1 代码实现:
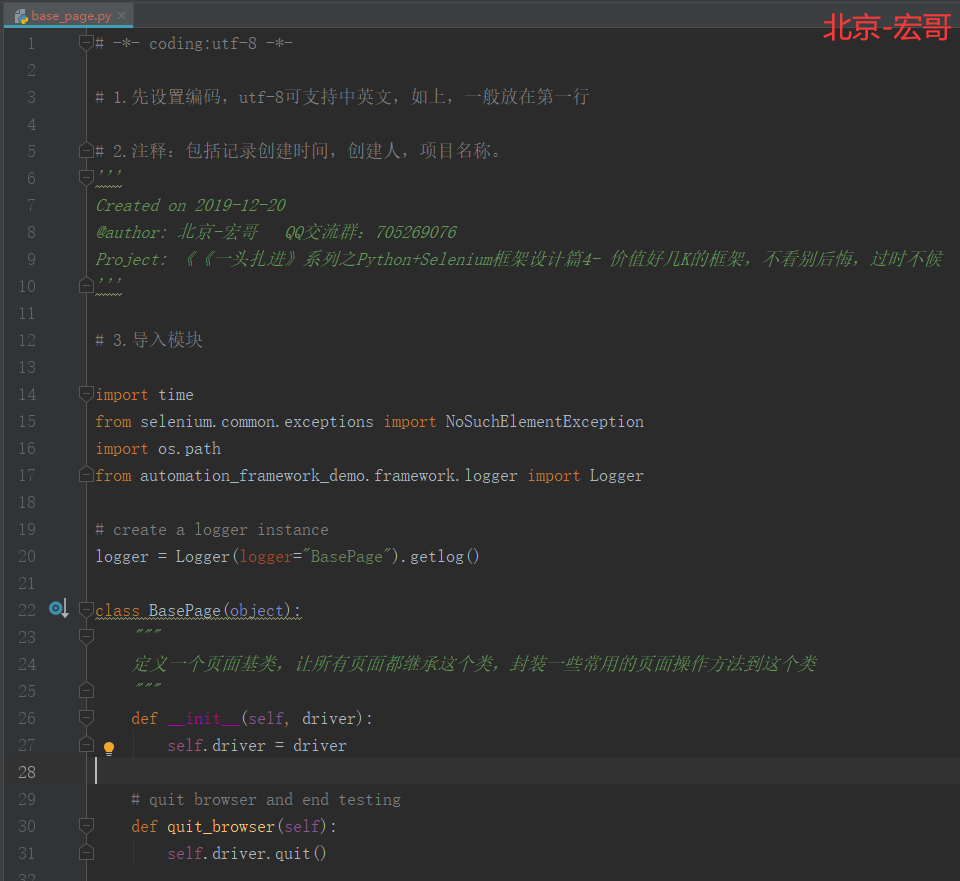
3.2 参考代码:
# -*- coding:utf-8 -*-# 1.先设置编码,utf-8可支持中英文,如上,一般放在第一行# 2.注释:包括记录创建时间,创建人,项目名称。
'''
Created on 2019-12-20
@author: 北京-宏哥 QQ交流群:260612819
@公众号:北京宏哥(微信搜索,关注宏哥提示解锁更多测试干货)
Project: 《《一头扎进》系列之Python+Selenium框架设计篇4- 价值好几K的框架,不看别后悔,过时不候
'''# 3.导入模块import time
from selenium.common.exceptions import NoSuchElementException
import os.path
from automation_framework_demo.framework.logger import Logger# create a logger instance
logger = Logger(logger="BasePage").getlog()class BasePage(object):"""定义一个页面基类,让所有页面都继承这个类,封装一些常用的页面操作方法到这个类"""def __init__(self, driver):self.driver = driver# quit browser and end testingdef quit_browser(self):self.driver.quit()# 浏览器前进操作def forward(self):self.driver.forward()logger.info("Click forward on current page.")# 浏览器后退操作def back(self):self.driver.back()logger.info("Click back on current page.")# 隐式等待def wait(self, seconds):self.driver.implicitly_wait(seconds)logger.info("wait for %d seconds." % seconds)# 点击关闭当前窗口def close(self):try:self.driver.close()logger.info("Closing and quit the browser.")except NameError as e:logger.error("Failed to quit the browser with %s" % e)# 保存图片def get_windows_img(self):"""在这里我们把file_path这个参数写死,直接保存到我们项目根目录的一个文件夹.\Screenshots下"""file_path = os.path.dirname(os.path.abspath('.')) + '/screenshots/'rq = time.strftime('%Y%m%d%H%M', time.localtime(time.time()))screen_name = file_path + rq + '.png'try:self.driver.get_screenshot_as_file(screen_name)logger.info("Had take screenshot and save to folder : /screenshots")except NameError as e:logger.error("Failed to take screenshot! %s" % e)self.get_windows_img()# 定位元素方法def find_element(self, selector):"""这个地方为什么是根据=>来切割字符串,请看页面里定位元素的方法submit_btn = "id=>su"login_lnk = "xpath => //*[@id='u1']/a[7]" # 百度首页登录链接定位如果采用等号,结果很多xpath表达式中包含一个=,这样会造成切割不准确,影响元素定位:param selector::return: element"""element = ''if '=>' not in selector:return self.driver.find_element_by_id(selector)selector_by = selector.split('=>')[0]selector_value = selector.split('=>')[1]print(selector_value)if selector_by == "i" or selector_by == 'id':try:element = self.driver.find_element_by_id(selector_value)logger.info("Had find the element \' %s \' successful ""by %s via value: %s " % (element.text, selector_by, selector_value))except NoSuchElementException as e:logger.error("NoSuchElementException: %s" % e)self.get_windows_img() # take screenshotelif selector_by == "n" or selector_by == 'name':element = self.driver.find_element_by_name(selector_value)elif selector_by == "c" or selector_by == 'class_name':element = self.driver.find_element_by_class_name(selector_value)elif selector_by == "l" or selector_by == 'link_text':element = self.driver.find_element_by_link_text(selector_value)elif selector_by == "p" or selector_by == 'partial_link_text':element = self.driver.find_element_by_partial_link_text(selector_value)elif selector_by == "t" or selector_by == 'tag_name':element = self.driver.find_element_by_tag_name(selector_value)elif selector_by == "x" or selector_by == 'xpath':try:element = self.driver.find_element_by_xpath(selector_value)logger.info("Had find the element \' %s \' successful ""by %s via value: %s " % (element.text, selector_by, selector_value))except NoSuchElementException as e:logger.error("NoSuchElementException: %s" % e)self.get_windows_img()elif selector_by == "s" or selector_by == 'selector_selector':element = self.driver.find_element_by_css_selector(selector_value)else:raise NameError("Please enter a valid type of targeting elements.")print(element)return element# 输入def type(self, selector, text):el = self.find_element(selector)el.clear()try:el.send_keys(text)logger.info("Had type \' %s \' in inputBox" % text)except NameError as e:logger.error("Failed to type in input box with %s" % e)self.get_windows_img()# 清除文本框def clear(self, selector):el = self.find_element(selector)try:el.clear()logger.info("Clear text in input box before typing.")except NameError as e:logger.error("Failed to clear in input box with %s" % e)self.get_windows_img()# 点击元素def click(self, selector):el = self.find_element(selector)try:el.click()logger.info("The element \' %s \' was clicked." % el)except NameError as e:logger.error("Failed to click the element with %s" % e)# 或者网页标题def get_page_title(self):logger.info("Current page title is %s" % self.driver.title)return self.driver.title@staticmethoddef sleep(seconds):time.sleep(seconds)logger.info("Sleep for %d seconds" % seconds)4. pageObjects文件夹下相关代码
1.页面对象中,百度主页的元素定位和简单的操作函数,页面类主要是元素定位和页面操作写成函数,供测试类调用。
baidu_homepage.py
4.1 代码实现:

4.2 参考代码:
# -*- coding:utf-8 -*-# 1.先设置编码,utf-8可支持中英文,如上,一般放在第一行# 2.注释:包括记录创建时间,创建人,项目名称。
'''
Created on 2019-12-20
@author: 北京-宏哥 QQ交流群:260612819
@公众号:北京宏哥(微信搜索,关注宏哥提示解锁更多测试干货)
Project: 《《一头扎进》系列之Python+Selenium框架设计篇4- 价值好几K的框架,不看别后悔,过时不候
'''
# 3.导入模块from automation_framework_demo.framework.base_page import BasePageclass HomePage(BasePage):input_box = "id=>kw"search_submit_btn = "xpath=>//*[@id='su']"#百度新闻入口#news_link = "xpath=>//*[@id='u1']/a[@name='tj_trnews']"news_link = "xpath=>//*[@id='u1']/a[@name='tj_trnews']"def type_search(self, text):self.type(self.input_box, text)def send_submit_btn(self):self.click(self.search_submit_btn)def click_news(self,):self.click(self.news_link)self.sleep(2)这里注意下元素定位写法,=>和base_page.py中find_element()方法元素定位切割有关系,网上有些人写根据逗号切割或者等号切割,在实际使用xpath定位,发现单独逗号或者单独等号切割都不精确,造成元素定位失败。
5. 测试类的写法举例
1.新建一个测试类baidu_search1.py。
baidu_search1.py
5.1 代码实现:

5.2 参考代码:
# -*- coding:utf-8 -*-# 1.先设置编码,utf-8可支持中英文,如上,一般放在第一行# 2.注释:包括记录创建时间,创建人,项目名称。
'''
Created on 2019-12-20
@author: 北京-宏哥 QQ交流群:260612819
@公众号:北京宏哥(微信搜索,关注宏哥提示解锁更多测试干货)
Project: 《《一头扎进》系列之Python+Selenium框架设计篇4- 价值好几K的框架,不看别后悔,过时不候
'''# 3.导入模块import time
import unittest
from automation_framework_demo.framework.browser_engine import BrowserEngine
from automation_framework_demo.pageobjects.baidu_homepage import HomePageclass BaiduSearch(unittest.TestCase):def setUpClass(cls):"""测试固件的setUp()的代码,主要是测试的前提准备工作:return:"""browse = BrowserEngine(cls)cls.driver = browse.open_browser(cls)def tearDownClass(cls):"""测试结束后的操作,这里基本上都是关闭浏览器:return:"""cls.driver.quit()def test_baidu_search(self):"""这里一定要test开头,把测试逻辑代码封装到一个test开头的方法里。:return:"""# self.driver.find_element_by_id('kw').send_keys('selenium')# time.sleep(1)homepage = HomePage(self.driver)homepage.type_search('selenium') # 调用页面对象中的方法homepage.send_submit_btn() # 调用页面对象类中的点击搜索按钮方法time.sleep(2)homepage.get_windows_img() # 调用基类截图方法print(self.driver.title)try:assert('selenium' in HomePage.get_page_title(self))print('Test Pass.')except Exception as e:print('Test Fail.', format(e))def test_search2(self):homepage = HomePage(self.driver)homepage.type_search('python') # 调用页面对象中的方法homepage.send_submit_btn() # 调用页面对象类中的点击搜索按钮方法time.sleep(2)homepage.get_windows_img() # 调用基类截图方法if __name__ == '__main__':unittest.main()5.3 运行结果:
运行代码后,控制台打印如下图的结果

5.4 代码说明
homepage = HomePage(self.driver)
上面这行代码要注意,意思是:到一个页面,第一件事情是初始化这个页面的一个页面对象实例。注意,一定要带self.driver,不然会报错,这个self.driver,可以这样理解:在当前测试类里面,self.driver是来自浏览器引擎类中方法得到的,在初始化一个页面对象
的时候,也把这个来自浏览器引擎类的driver给赋值给当前的页面对象,这样,才能执行页面对象或者基类里面的相关driver方法。写多了selenium的自动化脚本,你会明白,最重要的是保持前后driver的唯一性。
5.5 生成图片
1.测试结果:会在logs文件夹生成一个日志文件,也会在screenshots文件夹生成一个png图片。日志看过了,这里我们看一下图片
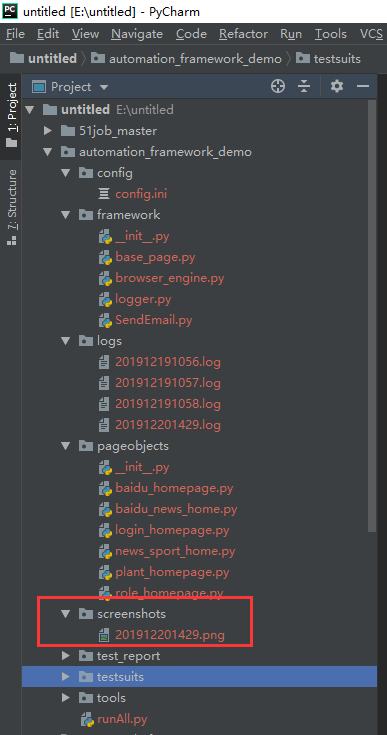
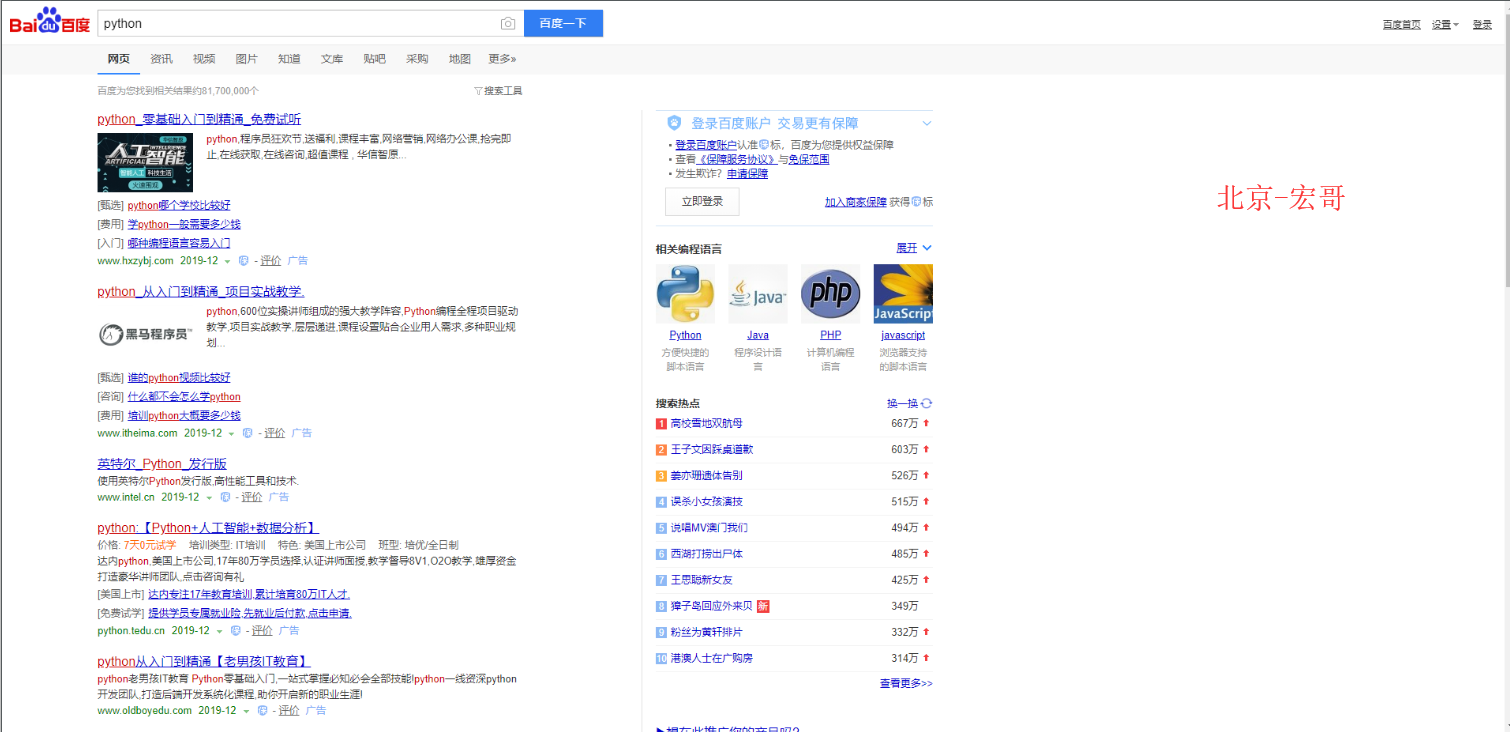
2.图片内容如下图:
6. 小结
好了,今天的分享就到这里吧!!!谢谢各位的耐心阅读。有问题加群交流讨论。
每天学习一点,今后必成大神-
往期推荐(由于跳转参数丢失了,所有建议选中要访问的右键,在新标签页中打开链接即可访问)或者微信搜索: 北京宏哥 公众号提前解锁更多干货。
Appium自动化系列,耗时80天打造的从搭建环境到实际应用精品教程测试
Python接口自动化测试教程,熬夜87天整理出这一份上万字的超全学习指南
Python+Selenium自动化系列,通宵700天从无到有搭建一个自动化测试框架
Java+Selenium自动化系列,仿照Python趁热打铁呕心沥血317天搭建价值好几K的自动化测试框架
Jmeter工具从基础->进阶->高级,费时2年多整理出这一份全网超详细的入门到精通教程
Fiddler工具从基础->进阶->高级,费时100多天吐血整理出这一份全网超详细的入门到精通教程
Pycharm工具基础使用教程
这篇关于《一头扎进》系列之Python+Selenium框架实战篇23- 价值好几K的框架,呵!这个框架有点意思啊!!!的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





