本文主要是介绍5.大模型高效微调(PEFT)未来发展趋势,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
PEFT 主流技术分类
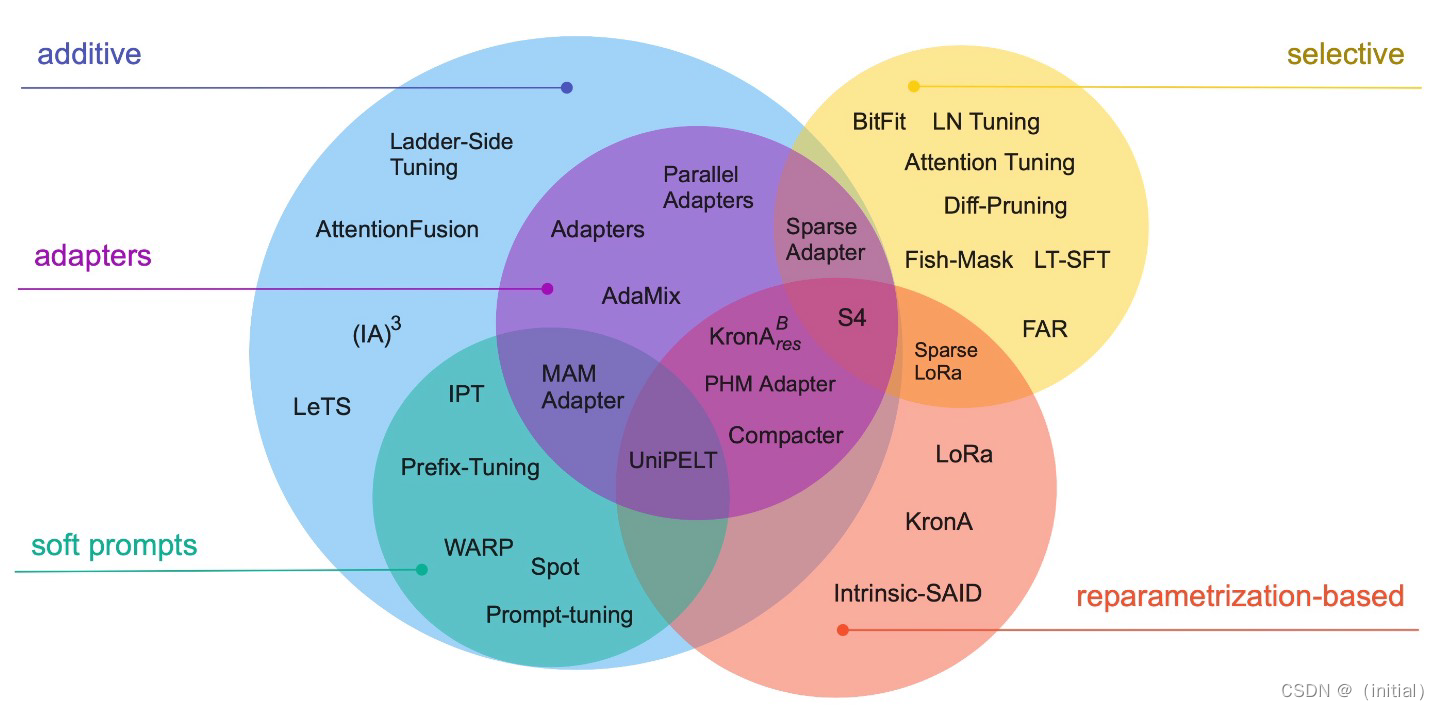
UniPELT 探索PEFT 大模型的统一框架(2022)
UIUC 和Meta AI 研究人员发表的UniPELT 提出将不同的PEFT 方法模块化。
通过门控机制学习激活最适合当前数据或任务的方法,尤其是最常见的3大类PEFT 技术:
- Adapters
- Soft Prompts
- Reparametrization-based
作者试图将已经被广泛证明有效的技术,整合为一个统一的微调框架。针对不同的下游任务,可以学习和配置不同的微调模块。

UniPELT 探索PEFT 大模型的统一框架
关于组合3类主流PEFT技术的探讨:
- Adapter:
- 接入位置(如:FFN)
- 接入方式(串行or 并行)
- MLP 设计(△h)
- Soft Prompts:
- 嵌入方式(Prompt-tuning, Prefix-Tuning, P-Tuning)
- Prompt 微调方法(手工生成or 连续可微优化)
- Reparametrization-based:
- 缩放因子(Scale: Rank r)
- 模型参数/模块类型(如:WQ, WV)
(IA)3 探索新的增量训练方法(2022)

为了使微调更加高效,北卡罗来纳教堂山分校的研究人员提出新的增量训练方法(IA)3 (通过学习向量来对激活层加权进行缩放,Infused Adapterby Inhibiting and Amplifying Inner Activations)
本文基于作者团队之前的工作T0 大模型,修改了损失函数以适应小样本学习,无需针对特定任务进行调整或修改即可应用于新任务,命名为TFew,并在RAFT 基准测试上取得了全新的SOTA结果,超过了人类基准水平。
(IA)3 探索新的增量训练方法
- 与LoRA相似,IA3具有许多相同的优势:
- IA3通过大幅减少可训练参数的数量使微调更加高效。(对于T0,一个使用IA3模型仅有大约0.01%的可训练参数,而即使是LoRA也有大于0.1%的可训练参数)
- 原始的预训练权重保持冻结状态,这意味着您可以构建多个轻量且便携的IA3模型,用于各种基于它们构建的下游任务使用IA3进行微调的模型的性能与完全微调模型的性能相媲美。
- IA3不会增加推理延迟,因为适配器权重可以与基础模型合并。
- 原则上,IA3可以应用于神经网络中的任何权重矩阵子集,以减少可训练参数的数量。根据作者的实现,IA3权重被添加到Transformer模型的关键、值和前馈层中。具体来说,对于Transformer模型,IA3权重被添加到关键和值层的输出,以及每个Transformer块中第二个前馈层的输入。
鉴于注入IA3参数的目标层,可根据权重矩阵的大小确定可训练参数的数量。
原则上,IA3可以应用于神经网络中的任何权重矩阵子集,以减少可训练参数的数量。根据作者的实现,IA3权重被添加到Transformer模型的K、V和FFN中。具体来说,对于Transformer模型,IA3权重被添加到关键和值层的输出,以及每个Transformer块中第二个前馈层的输入。
根据注入IA3参数的目标层,可以根据权重矩阵的大小确定可训练参数的数量。

大模型高效微调技术未来发展趋势
- 更高效的参数优化:研究将继续寻找更高效的方法来微调大型模型,减少所需的参数量和计算资源。这可能包括更先进的参数共享策略和更高效的LoRA等技术。
- 适应性和灵活性的提升:微调方法将更加灵活和适应性强,能够针对不同类型的任务和数据集进行优化。
- 跨模态和多任务学习:PEFT可能会扩展到跨模态(如结合文本、图像和声音的模型)和多任务学习领域,以增强模型处理不同类型数据和执行多种任务的能力。
- 模型压缩和加速:随着对边缘设备和移动设备部署AI模型的需求增加,PEFT技术可能会重点关注模型压缩和推理速度的提升。
- 低资源语言和任务的支持:将PEFT技术应用于低资源语言和特定领域任务,提供更广泛的语言和任务覆盖。
T技术可能会重点关注模型压缩和推理速度的提升。
5. 低资源语言和任务的支持:将PEFT技术应用于低资源语言和特定领域任务,提供更广泛的语言和任务覆盖。
这篇关于5.大模型高效微调(PEFT)未来发展趋势的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!




