本文主要是介绍33-unittest数据驱动(ddt),希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
所谓数据驱动,是指利用不同的测试数据来测试相同的场景。为了提高代码的重用性,增加代码效率而采用一种代码编写的方法,叫数据驱动,也就是参数化。达到测试数据和测试业务相分离的效果。
比如登录这个功能,操作过程都是一样的。如果在测试用例中重复去写操作过程会增加代码量,对于这种场景,可以采用数据驱动设计模式,一组数据对应一个测试用例,用例自动加载生成。
一、环境准备
安装ddt模块,打开cmd输入 pip install ddt 在线安装。

二、数据驱动操作过程
- 在测试类上添加修饰 @ddt.ddt
- 在测试用例上添加修饰 @ddt.data()
- @data(列表对象):会将整个列表作为参数传入,test_01()中获取的是整个二维列表。
- @data(列表):会将整个列表的子元素作为参数逐个传入,test_02()将二维列表的子元素逐个传入,每一个子元素作为一个测试用例。
- @unpack:将要传入的元素先进行解包,解包后再传入,test_03()将二维列表的子元素拆解后逐个传入。
import unittest
from ddt import ddt, data, unpack@ddt
class Demo(unittest.TestCase):test_data = [[1, 2, 3], [4, 5, 6]]# 将整个test_data对象作为参数传入@data(test_data)def test_01(self, value):print('test_01:', value)# 将test_data列表中的每个子元素作为参数传入@data(*test_data)def test1(self, value):print('test_02:', value)# 将test_data列表中的每个子元素拆解后作为参数传入@data(*test_data)@unpackdef test_03(self, a, b, c):print('test_03:', "a: {}、b:{}、c:{}".format(a, b, c))if __name__ == '__main__':unittest.main()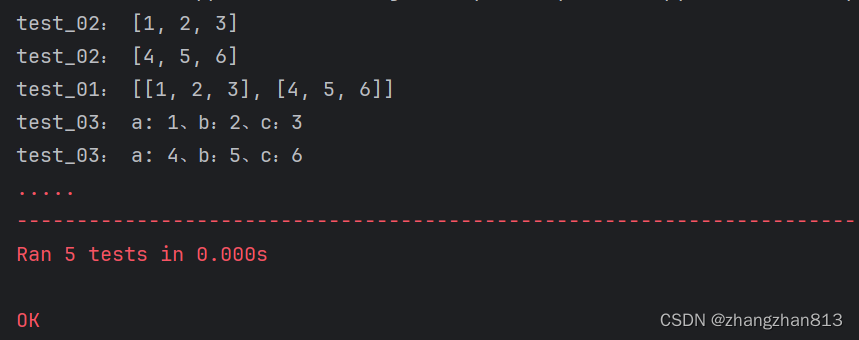
三、案例代码
1)在excel表中添加测试数据

2)编写Util.py文件,用于读取excel表中数据
import xlrdclass ExcelUtil():def load_excel(self, excelPath, sheetName):self.data = xlrd.open_workbook(excelPath)self.sheet = self.data.sheet_by_name(sheetName)# 1.获取第一行作为keyself.keys = self.sheet.row_values(0)# 2.获取总行数self.rowNums = self.sheet.nrows# 3.获取总列数self.colNums = self.sheet.ncolsdef get_data(self):res = []j = 1for i in range(self.rowNums - 1):dict = {}values = self.sheet.row_values(j)for idx in range(self.colNums):dict[self.keys[idx]] = values[idx]res.append(dict)j += 1return resif __name__ == '__main__':excelPath = 'test.xlsx'sheetName = 'Sheet1'excelObj = ExcelUtil()excelObj.load_excel(excelPath, sheetName)print(excelObj.get_data())3)编写test.py文件,对登录功能进行测试
from selenium import webdriver
import unittest
import ddt
from selenium.webdriver.support.ui import WebDriverWait
from Util import ExcelUtil# 1.读取excel文件中的测试数据
excelObj = ExcelUtil()
excelObj.load_excel('test.xlsx', 'Sheet1')
test_data = excelObj.get_data()# 2.编写测试类
@ddt.ddt
class Demo(unittest.TestCase):def setUp(self):self.driver = webdriver.Chrome()self.driver.get('http://localhost:8080/mms/login.html')def tearDown(self):self.driver.quit()# 智能等待def find_element(self, locator):try:element = WebDriverWait(self.driver, 30).until(lambda x: x.find_element(*locator))return elementexcept Exception as e:print('报错:{}'.format(e))def test_login_success(self):'''测试当输入正确的用户名和密码时,可以成功登录系统:return:'''self.find_element(('id', 'username')).clear()self.find_element(('id', 'username')).send_keys('admin')self.find_element(('id', 'password')).clear()self.find_element(('id', 'password')).send_keys('admin')self.find_element(('css selector', '.forgot > input')).click()# 登录成功后,获取系统主页中的登录名login_name = self.find_element(('id', 'loginName')).textself.assertEqual(login_name, 'admin')@ddt.data(*test_data)def test_login_fail(self, dict):'''测试当用户名为空、密码为空、用户名不正确、密码不正确时,登录系统失败:return:'''print(dict)self.find_element(('id', 'username')).clear()self.find_element(('id', 'username')).send_keys(dict['username'])self.find_element(('id', 'password')).clear()self.find_element(('id', 'password')).send_keys(dict['password'])self.find_element(('css selector', '.forgot > input')).click()# 登录失败后,获取失败提示框中的提示信息err_msg = self.find_element(('xpath', '/html/body/div[3]/div[2]/div[1]')).textself.assertEqual(err_msg, dict['err_msg'])if __name__ == '__main__':unittest.main()4)执行结果
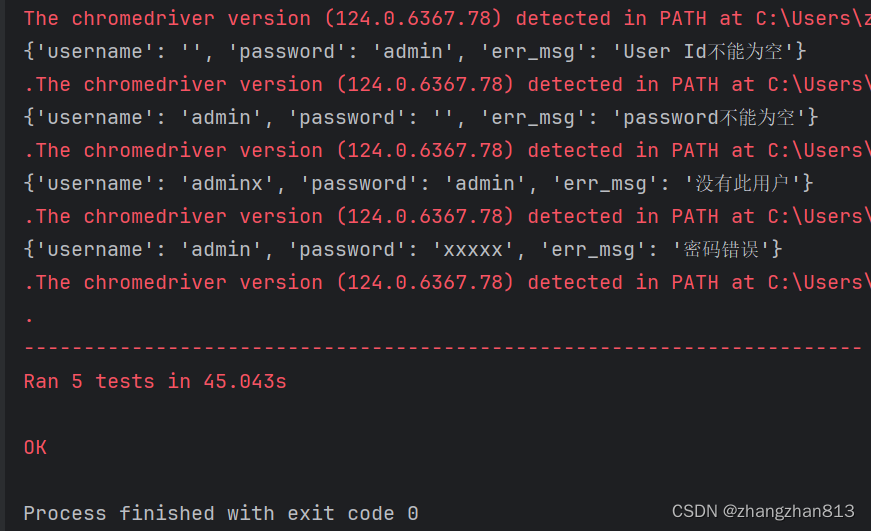
这篇关于33-unittest数据驱动(ddt)的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!




