本文主要是介绍41 mysql subquery 的实现,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
前言
sub query 是一个我们经常会使用到的一个 用法
我们这里 看一看各个场景下面的 sub query 的相关处理
查看 本文, 需要 先看一下 join 的相关处理
测试数据表如下, 两张测试表, tz_test, tz_test03, 表结构 一致
CREATE TABLE `tz_test` (`id` int(11) unsigned NOT NULL AUTO_INCREMENT,`field1` varchar(128) DEFAULT NULL,`field2` varchar(128) DEFAULT NULL,PRIMARY KEY (`id`) USING BTREE,UNIQUE KEY `field_1_2` (`field1`) USING BTREE
) ENGINE=InnoDB AUTO_INCREMENT=11 DEFAULT CHARSET=utf8CREATE TABLE `tz_test_03` (`id` int(11) unsigned NOT NULL AUTO_INCREMENT,`field1` varchar(128) DEFAULT NULL,`field2` varchar(128) DEFAULT NULL,PRIMARY KEY (`id`) USING BTREE,UNIQUE KEY `field_1_2` (`field1`) USING BTREE
) ENGINE=InnoDB AUTO_INCREMENT=11 DEFAULT CHARSET=utf8tz_test 数据如下
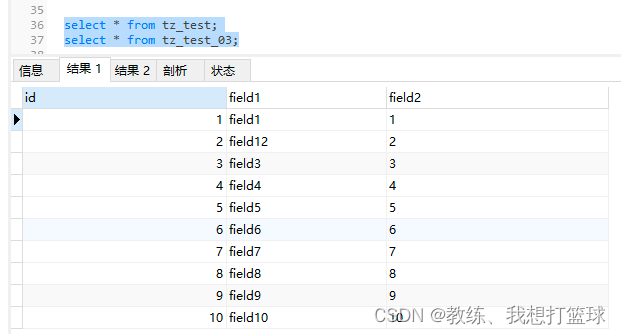
tz_test_03 数据如下
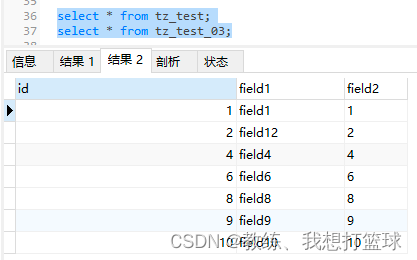
依据主键进行子查询
执行 sql 如下 “select * from tz_test where id in (select id from tz_test_03);”
这里的实现 类似于 join 的根据主键进行关联的查询处理一样
选择的主驱动表 为内层查询的数据表, 迭代内层的 id 列表
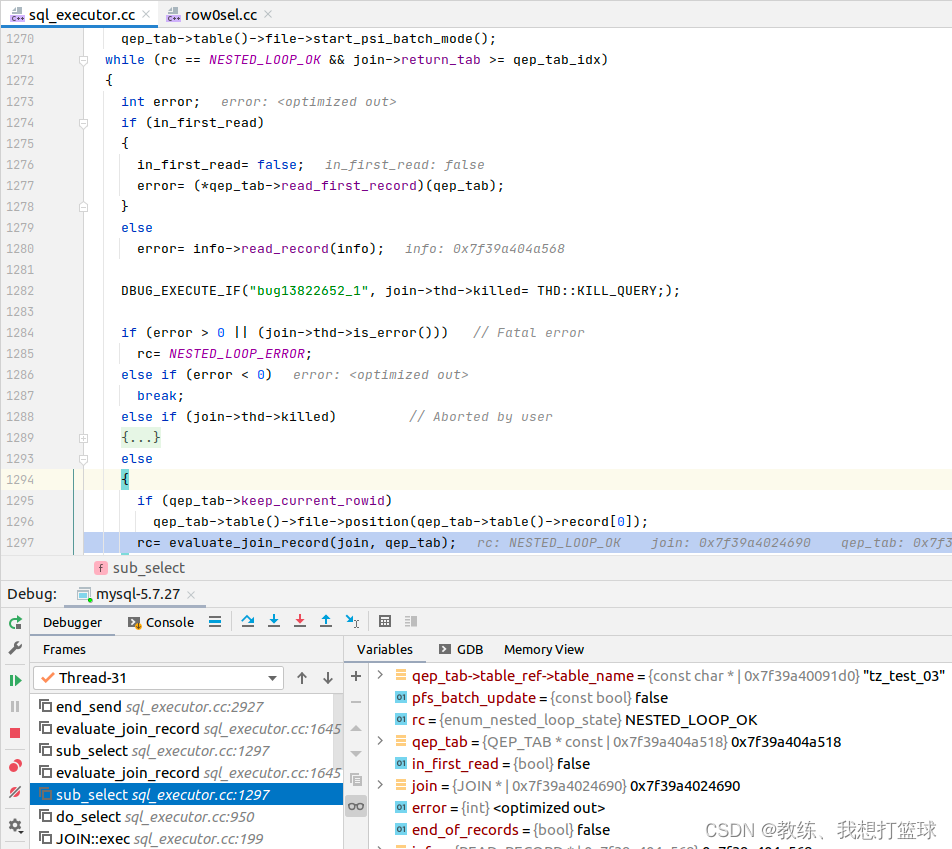
内层的遍历基于待查询的主表 tz_test, 主要的查询条件是基于 正在遍历的 id 进行主键查询
因为这里是主键关联, 因此只会 查询一次
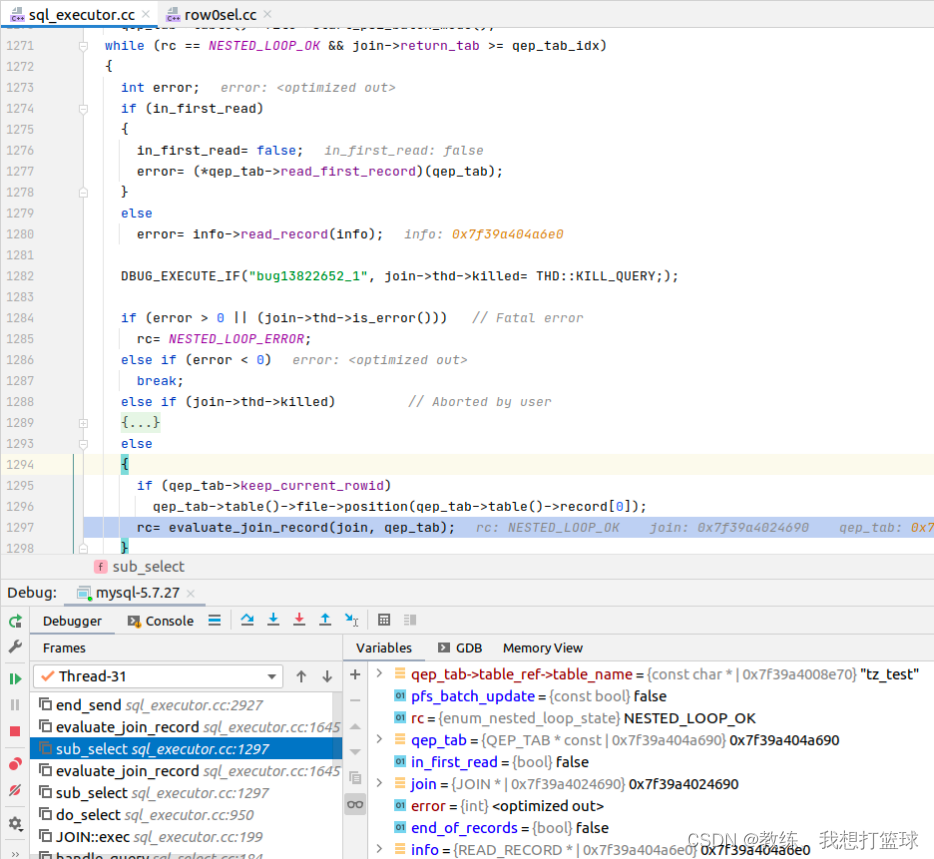
内层迭代 tz_test 相关的函数如下, 只有一个根据 主键 进行查询, 下一个循环 会直接跳出循环

查询类似于如下 join 查询
select t1.* from tz_test as t1
inner join tz_test_03 as t2 on t1.id = t2.id
where 1 = 1;依据 索引字段 进行子查询
执行 sql 如下 “select * from tz_test where field1 in (select field1 from tz_test_03);”
这里的实现 和 join 就有区别了, 这里是 将内层查询处理成为了一个子查询, 新建了一张 临时表
外层迭代的数据如下, 是 tz_test 表
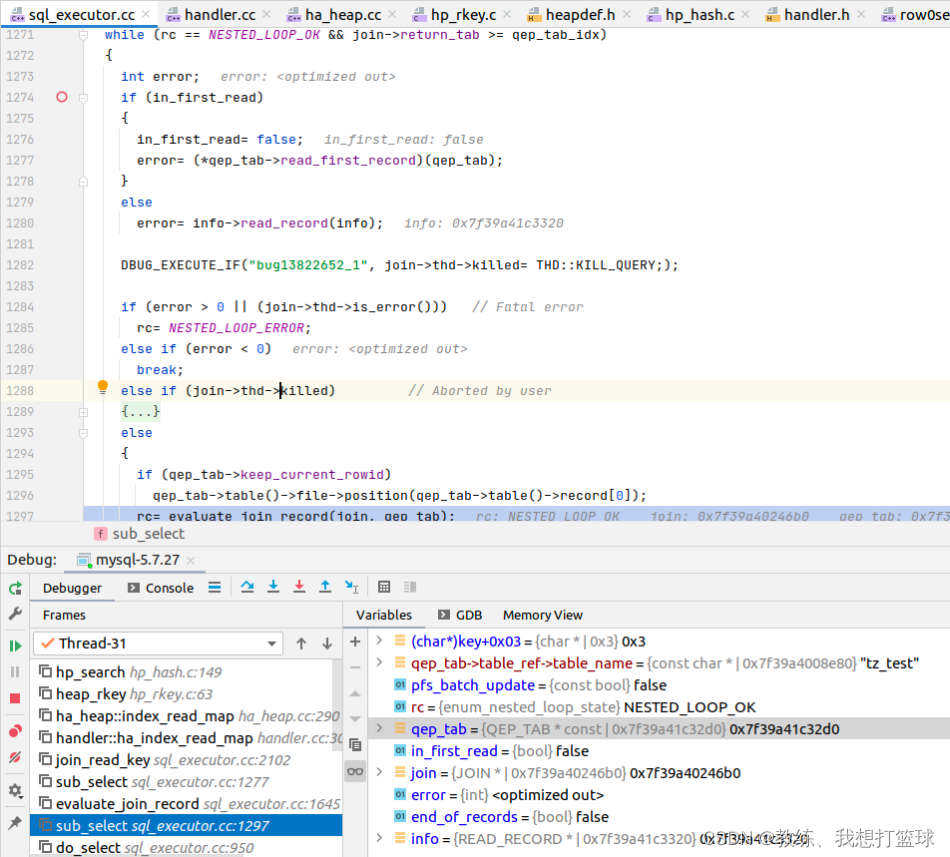
内层循环迭代的是 mysql 生成的一张临时表 “<su bquery2>”, 这张表存在于 内存, 并且根据 数据特征做出了一些优化
比如我们这里 tz_test_03 表的 field1 字段, 其实仅仅只有 NORMAL 索引, 没有唯一限定, 但是 实际上在这里 从 qep_tab->read_first_record 和 info->read_record 可以看出, mysql 根据 数据特征 增加了一个 “唯一限定”, 对于这里的场景中 field1 是唯一的

最多只在 <subquery2> 中查询一次, 因此 说这里 mysql 在这 <subquery2> 的临时表的 field1 字段增加了一个 “唯一限定”

然后 <subquery2> 中的查询如下, 这里是存储的结构是一个 HashMap, 这里按照 HashMap 的查询方式进行查询, 比如这里查询的 key 是 “field12”
<subquery2> 是根据 tz_test_03, 因此记录有 7 条
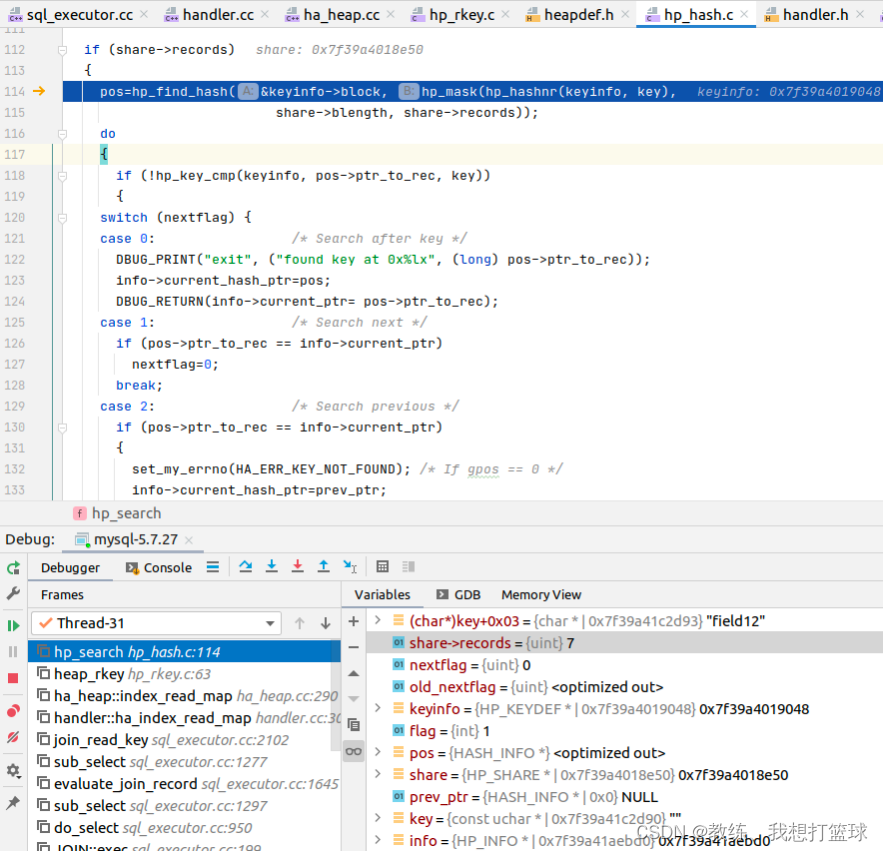
对于 tz_test 中有, <subquery2> 中不存在的记录, 这里 内层循环 查询不到, 响应 -1, 跳出循环
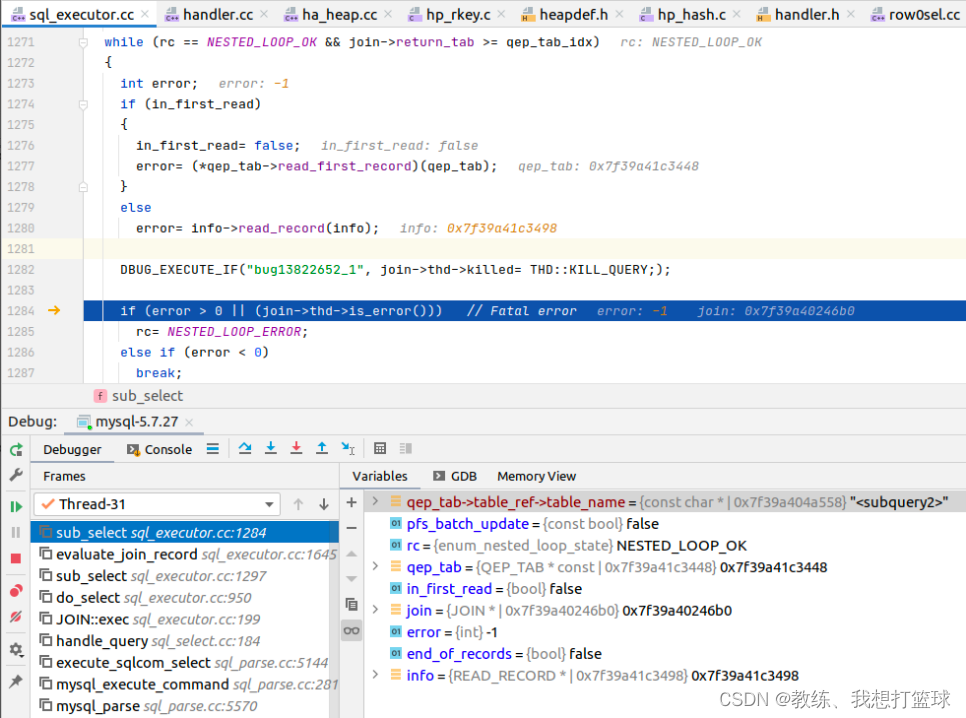
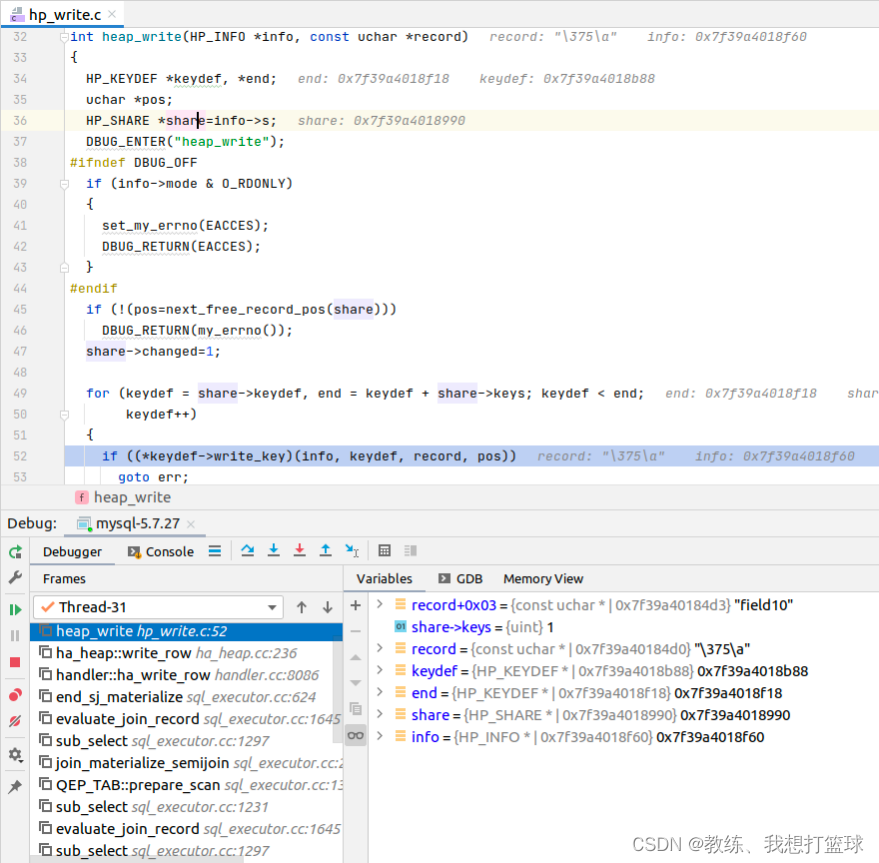
<subquery2> 临时表的数据填充
这里有三个 sub_query, 最顶层的是 tz_test, 第二层的是 <subquery2>, 最底层的是 tz_test_03
<subquery2> 的表数据类似于 “select field1 from tz_test_03;”
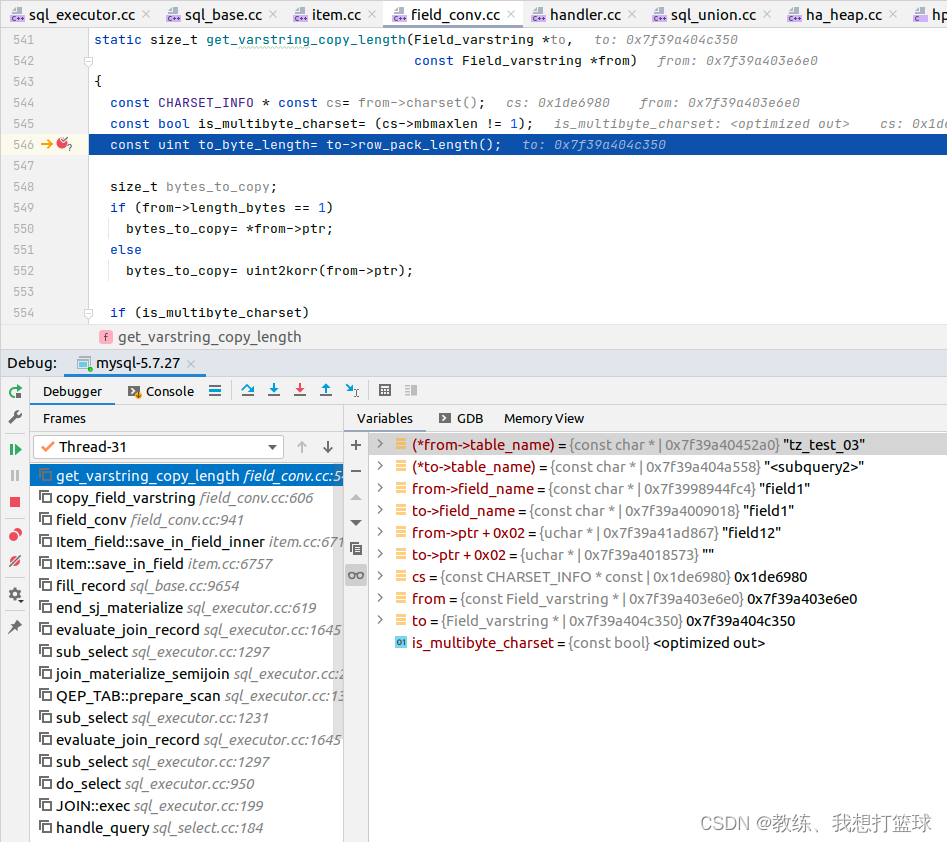
<subquery2> 的临时初始化 是在 qup_tab->prepare_scan 中处理的
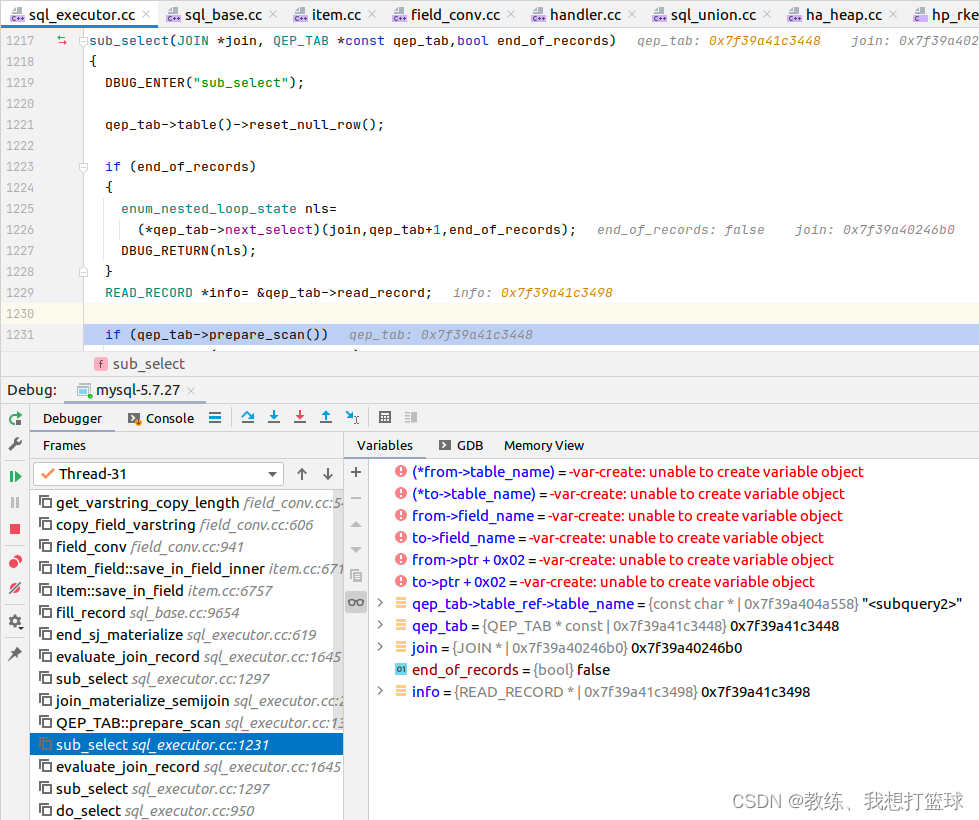
然后 之后是将记录 持久化到 share->records 中
依据 普通字段 进行子查询
执行 sql 如下 “select * from tz_test where field2 in (select field2 from tz_test_03);”
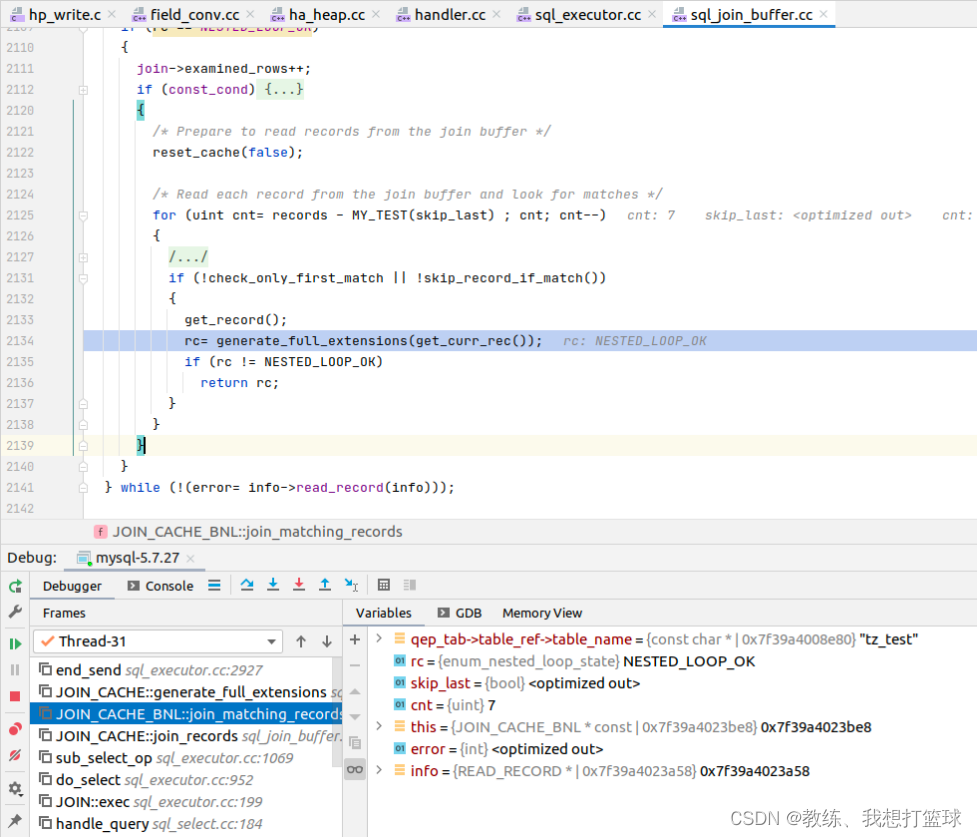
这里的处理 和 依据普通字段进行 join 查询的处理一样, 首先是将 tz_test_03 的相关字段放到 join_buffer, 因此这里 join_buffer 中有 7 条记录
然后 这里迭代 tz_test 的数据, 然后 输出符合条件的记录 输出
do_select 这一层情况如下
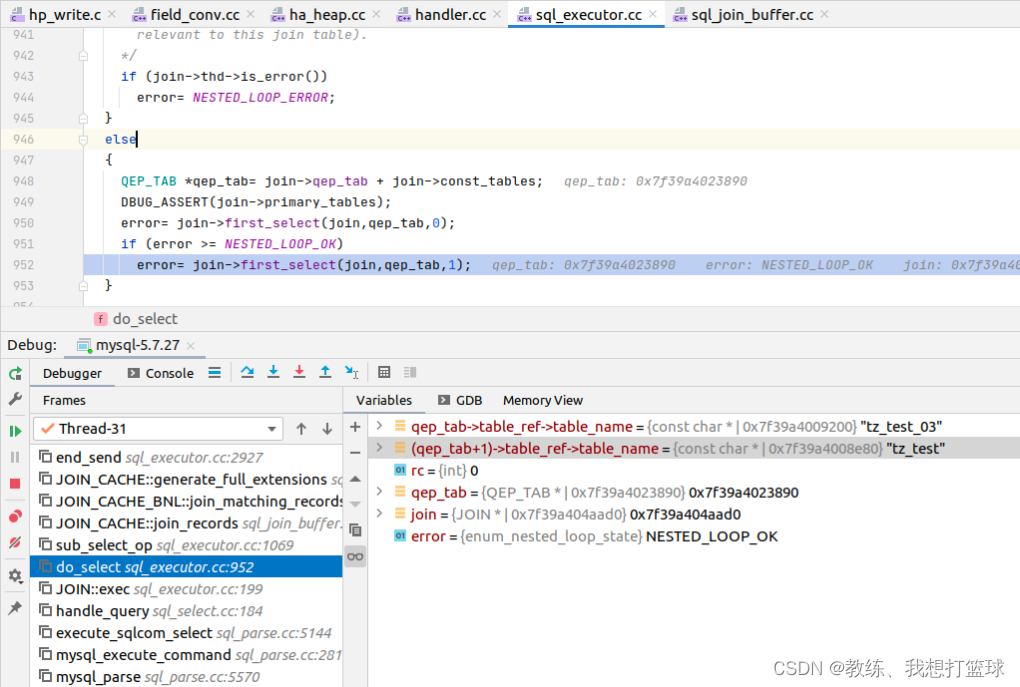
查询类似于如下 join 查询
select t1.* from tz_test as t1
inner join tz_test_03 as t2 on t1.field2 = t2.field2
where 1 = 1;大批量的数据依据主键进行子查询是否有优化?
构造 大表如下

执行 sql 如下 “select *, 2, 2, 2 from tz_test where id in (select id from tz_test_03);”
可以看到的是 查询实现是一样的, 主驱动表为的 tz_test_03, 然后 内层循环表为 tz_test
完
这篇关于41 mysql subquery 的实现的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






