本文主要是介绍汽车数据应用构想(三),希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
上期说的,用数据去拟合停车信息的应用,那么类似的POI信息相关的场景其实都可以实现。今天讲讲用户使用频率也很高的加油/充电场景。
实际应用中,在加油场景中用户关心的通常还是价格。无论是导航还是各种加油APP/小程序,都已经很好地满足了用户需要。但是哪些加油站有免费洗车、加油或洗车是否需要排队、要排多久......还是有信息缺失的。
通过熄火再点火后的油箱数据变化,即可判断有加油行为;多车在此地有加油行为,即可判断出这个位置是加油站;
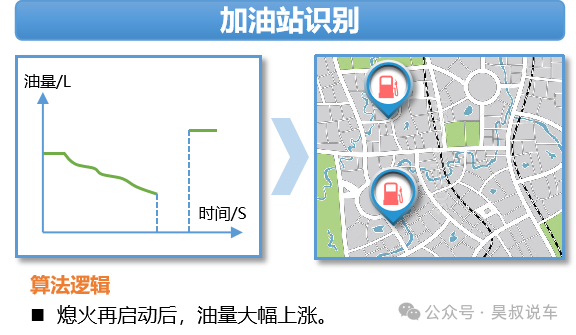
下次再有车开至附近慢速移动,即可视为到达加油站。到达时间至熄火时间,多车在此坐标点停留,即排队;

加油后并未马上驶离加油站,而是具有相似(近)移动轨迹,并且有不熄火、关窗、挂空挡等行为,即可判断其有自助洗车行为;
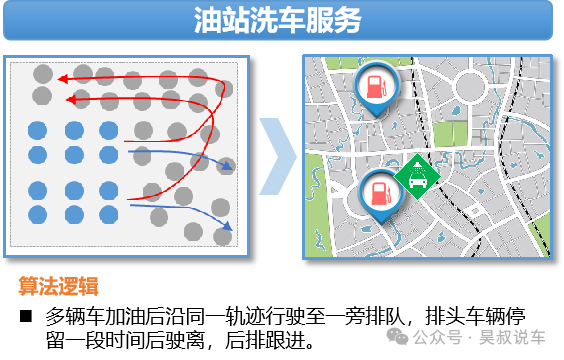
加完油,且有洗车行为。那么加完油启动,至驶离加油站,就是洗车的排队时间。
多说一点,附近有多个加油站,那就看多数人都去哪个加油。人多、排队等这些数据则表明:要么油品好,要么价格低……如果再能结合第三方价格信息,则可以更精确判断!
充电则与加油不同,价格并不是最重要的选择条件,反而是排队时长、充电时长(实际充电功率)、充电枪与车是否兼容......更让用户感到焦虑,而这些却是各类充电APP中缺失的!
无论是打开充电口,还是插枪,或BMS中开始充电的数据都可以作为充电行为判断条件。充电场地POI即多辆车在此发生过充电行为的位置(如果历史信息中这个位置只有相同的一辆或几辆车充电,说明这是私桩或非运营场地);
排队时长与加油类似。车行驶到充电场地,且未熄火时开始,到其充电开始的这段时间,则是排队时长;
充电时长,甚至不同电量区间的充电功率,在数据中都有着清楚地记录。而比较关键的就是相同车型肯定是具有同样的充电功率,包括充不进电的情况,都是实际应用中最需要提供给相同车型用户的信息之一;
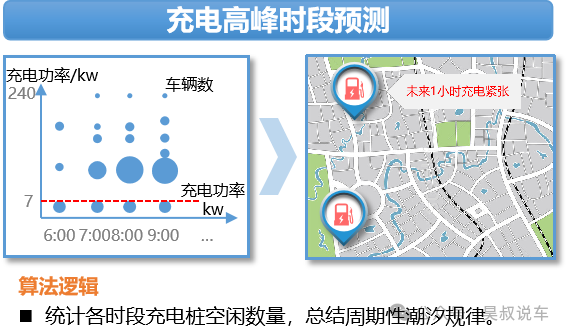
洗车相关与上面加油场景相同,不再赘述。
看,是不是挺简单?但要注意的是加油/充电的数据不能仅仅简单地统计,因为还有一些条件会导致行为的异常:
一、节假日影响。这个影响最不稳定,并不是所有高速路段或景区都人满为患。季节、媒体导向都会影响人流车流,比如淄博烧烤,现在放假就没那么多人了吧。
二、异常天气影响。极寒天气自助洗车机肯定就不开了,冻了一晚上的电池充电功率与时长也与正常是不一样的。
三、价格变动。这个影响极大,油价上调之前很多车排大队加油,而电车则是在“谷”价的时候才有人去充电。
想到哪儿说到哪儿,以上条件也并不全面,总之“数据”转变为“信息”的过程并不是简单的统计,而是有更多维度的细分与过滤,算法对精度的影响极大,只有在落地的过程中不断调整才可以获得更有价值的提升!
而这种通过车辆数据变化去记录位置信息的POI服务,不仅限于加油充电,包括打滑路段,积水路段等,都可以用车辆数据去拟合,下期把这类场景一起说一下。
文章首发于公众号:昊叔说车
原创不易,转载请告知原作者,注明出处。

这篇关于汽车数据应用构想(三)的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






