本文主要是介绍遗传算法入门(连载之四),希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
最近在学习有关遗传算法和神经网络方面的知识,网上查看了很多这方面的秘笈,只怪小生天生愚钝、才疏学浅,不能很好的领悟秘笈中的真谛,往往被弄得晕头转向、不知所措
 。直到有一天无意中看到了博主zzwu写的有关这方面的文章,初读之,如温旧习;渐深入,觉甚好;遂一气呵成,犹如拨云见日、茅塞顿开。余甚怕在茫茫Internet中再无机会拜读之,遂收藏于此,以便众人观之,绝无其他不良用途。在此对博主再次深表感谢。博文转自:http://blog.csdn.net/zzwu/article/details/561620
。直到有一天无意中看到了博主zzwu写的有关这方面的文章,初读之,如温旧习;渐深入,觉甚好;遂一气呵成,犹如拨云见日、茅塞顿开。余甚怕在茫茫Internet中再无机会拜读之,遂收藏于此,以便众人观之,绝无其他不良用途。在此对博主再次深表感谢。博文转自:http://blog.csdn.net/zzwu/article/details/561620

扎自<游戏编程中的人工智能技术>第三章
清华大学出版社
(本章由zzwu译)
3.3计算机内的进化( Evolution Inside Your Computer )
遗传算法的工作过程本质上就是模拟生物的进化过程。首先,要规定一种编码方法,使得你的问题的任何一个潜在可行解都能表示成为一个“数字”染色体。然后,创建一个由随机的染色体组成的初始群体(每个染色体代表了一个不同的候选解),并在一段时期中,以培育适应性最强的个体的办法,让它们进化,在此期间,染色体的某些位置上要加入少量的变异。经过许多世代后,运气好一点,遗传算法将会收敛到一个解。遗传算法不保证一定能得到解,如果有解也不保证找到的是最优解,但只要采用的方法正确,你通常都能为遗传算法编出一个能够很好运行的程序。遗传算法的最大优点就是,你不需要知道怎么去解决一个问题;你需要知道的仅仅是,用怎么的方式对可行解进行编码,使得它能能被遗传算法机制所利用。
通常,代表可行解的染色体采用一系列的二进制位作为编码。在运行开始时,你创建一个染色体的群体,每个染色体都是一组随机的2进制位。2进制位(即染色体)的长度在整个群体中都是一样的。作为一个例子,长度为 20的染色体的形状如下:
01010010100101001111
重要的事情就在于,每个染色体都用这样的方式编码成为由 0和1组成的字符串,而它们通过 译码 就能用来表示你手头问题的一个解。这可能是一个很差的解,也可能是一个十分完美的解,但每一个单个的染色体都代表了一个可行解(下面就将讨论有关编码的更多的细节)。初始群体通常都是 很糟的 ,有点象英国板球队或美国足球队(抱歉了!)。但不管怎样,正如我前面说过的那样,一个初始的群体已经创建完成(对这一例子,不妨设共有100个成员),这样,你就可以开始做下面列出的一系列工作(你不用担心用蓝字显示的那些词句,我后面马上就会来解释一切):
不断进行下列循环,直到寻找出一个解 :
1.检查每个染色体,看它解决问题的性能怎样,并相应地为它分配一个适应性分数。
2.从当前群体中选出2个成员。被选出的概率正比于染色体的适应性,适应性分数愈高,被选中的可能性也就愈大。常用的方法就是采用所谓的轮盘赌选择法或赌轮选择法(Roulette wheel selection)。
3.按照预先设定的杂交率(Crossover Rate),从每个选中染色体的一个随机的点上进行杂交(crossover)。
4.按照预定的变异率(mutation rate),通过对被选染色体的位的循环,把相应的位实行翻转(flip)。
5.重复步骤2,3,4,直到100个成员的新群体被创建出来。
结束循环
以上算法中步骤1 到步骤5 的一次循环称为一个代(或世代,generation)。而我把这整个的循环称作一个时代(epoch) ,在我的正文和代码中将始终都用这样方式来称呼。
3.3.1什么是轮盘赌选择? ( What's the Roulette Wheel Selection )
轮盘赌选择是从染色体群体中选择一些成员的方法,被选中的机率和它们的适应性分数成比例,染色体的适应性分数愈高,被选中的概率也愈多。这不保证适应性分数最高的成员一定能选入下一代,仅仅说明它有最大的概率被选中。其工作过程是这样的:
设想群体全体成员的适当性分数由一张饼图来代表 (见图3.4),这一饼图就和用于赌博的转轮形状一样。我们要为群体中每一染色体指定饼图中一个小块。块的大小与染色体的适应性分数成比例,适应性分数愈高,它在饼图中对应的小块所占面积也愈大。为了选取一个染色体,你要做的,就是旋转这个轮子,并把一个小球抛入其中,让它翻来翻去地跳动,直到轮盘停止时,看小球停止在哪一块上,就选中与它对应的那个染色体。本章后面我就会告诉你怎样来编写这种程序的准确算法。
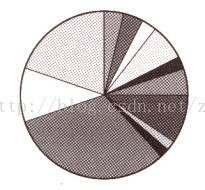
图 3.4 染色体的轮盘赌式选择
3.3.2什么是杂交率?( What's the Crossover Rate )
杂交率就是用来确定 2个染色体进行局部的位(bit)的互换以产生2个新的子代的概率。 实验表明这一数值通常取为0.7左右是理想的,尽管某些问题领域可能需要更高一些或较低一些的值。
每一次,我们从群体中选择 2个染色体,同时生成其值在0到1之间一个随机数,然后根据此数据的值来确定两个染色体是否要进行杂交。如果数值低于杂交率(0.7)就进行杂交,然后你就沿着染色体的长度随机选择一个位置,并把此位置后面所有的位进行互换。
例如,设给定的 2个染色体为:
10001001110010010
01010001001000011
沿着它们的长度你随机选择一个位置,比如说 10,然后互换第10位之后所有位。这样两个染色体就变成了(我已在开始互换的位置加了一个空格):
10001001101000011
01010001010010010
3.3.3 什么是变异率?( What's the Mutation Rate? )
变异率(突变率) 就是在一个染色体中将位实行翻转(flip,即0 变1,1变 0)的几率。这对于二进制编码的基因来说通常都是很低的值,比如 0.001 。
因此,无论你从群体中怎样选择染色体,你首先是检查是否要杂交,然后再从头到尾检查子代染色体的各个位,并按所规定的几率对其中的某些位实行突变(翻转)。
3.3.4 怎么搞的啦!( Phew! )
如果你对上面讲东西感到有些茫然,那也不必担心!从现在开始直到本章结束,所有阅读材料大多数都被设计用来重读两遍。这里有很多需要你理解的新概念,且它们都是相互混杂在一起。我相信对于你这是最好的学习方法。当你通读第一遍时,你有望对一些基本概念得到一些孤立的感性认识,而在阅读第二遍时(如果我做的工作是正确的话),你就能看到各种不同的概念怎样相互联系起来。而当你最后结合源程序来开始编程玩弄时,每一件事物都只是考虑怎样周密地进行安排的问题,到那时你的工作仅仅是一种如何来提炼你的知识和技能的事了(那是比较容易的一部分)。
| 注意: 在本书所附的光盘的 Chaper3/Pathfinder 文件夹中,你能找到Pathfinder 工程的全部源码。 如果你想在进一步阅读课文之前窥视一下工程的全貌,在 文件Chaper3 Executable中有一个预先制作好的执行程序,Pathfinder.exe。 |
-连载4完-
这篇关于遗传算法入门(连载之四)的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







