本文主要是介绍python 多任务之多线程,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
多线程
线程是程序执行的最小单位,实际上进程只负责分配资源,而利用这些资源执行程序的是线程,也就是说进程是线程的容器,一个进程中最少有一个线程来负责执行程序,它可以与同属一个进程的其它线程共享进程所拥有的全部资源
为什么要选择线程,而不选择进程
进程:就像同时和两个人聊QQ,就需要打开两个QQ软件,会占用没必要的资源
线程:就像同时和两个人聊QQ,只需要打开两个窗口就可以了,也会节省很多资源
线程的创建步骤
1.导入所需要的线程模块
import threading2.通过线程类创建线程对象
线程对象 = threading.Thread(target=任务名)3.启动线程
线程对象.start()
多线程的使用
import threading
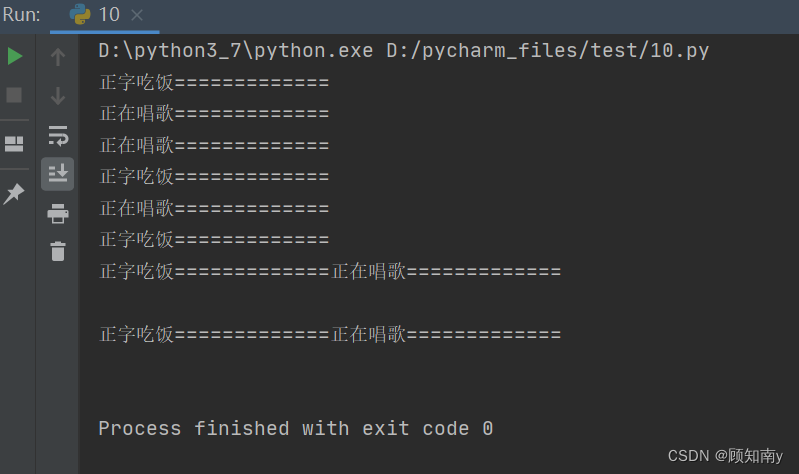
import timedef eat():for i in range(5):print('正字吃饭=============')time.sleep(0.5) # 等待0.5秒后再执行def music():for i in range(5):print('正在唱歌=============')time.sleep(0.5) # 等待0.5秒后再执行if __name__ == '__main__':eat_thread = threading.Thread(target=eat,)music_thread = threading.Thread(target=music,)eat_thread.start()music_thread.start()
执行结果
线程执行任务函数的传参
- 元组方式传参:元组方式传参一定要和参数的顺序保持一致
- 字典方式传参:字典方式传参字典中的key一定要和参数名保持一致
import threading
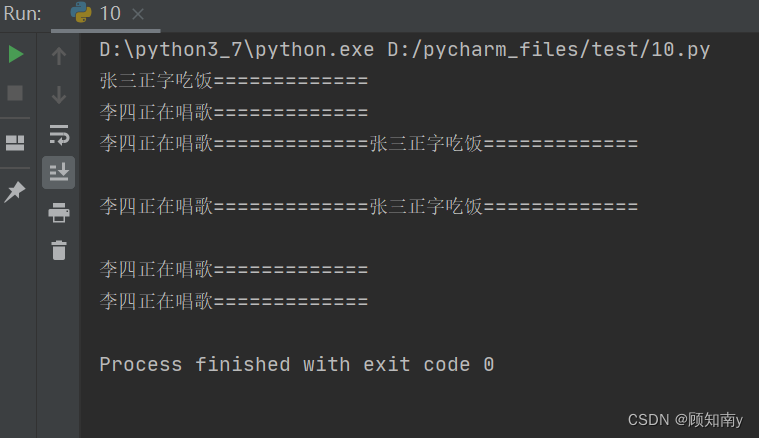
import timedef eat(num, name):for i in range(num):print(f'{name}正字吃饭=============')time.sleep(0.5) # 等待0.5秒后再执行def music(num, name):for i in range(num):print(f'{name}正在唱歌=============')time.sleep(0.5) # 等待0.5秒后再执行if __name__ == '__main__':eat_thread = threading.Thread(target=eat, args=(3, '张三'))music_thread = threading.Thread(target=music, kwargs={'num': 5, 'name': '李四'})eat_thread.start()music_thread.start()
执行结果
守护主线程
主线程会等待所有的子线程执行结束后主线程再结束,但是也是可以主线程不等待子线程执行完成,可以设置守护主线程
两种方式
1、threading.Thread(target=work, daemon=True)
2、线程对象.setDaemon(True)
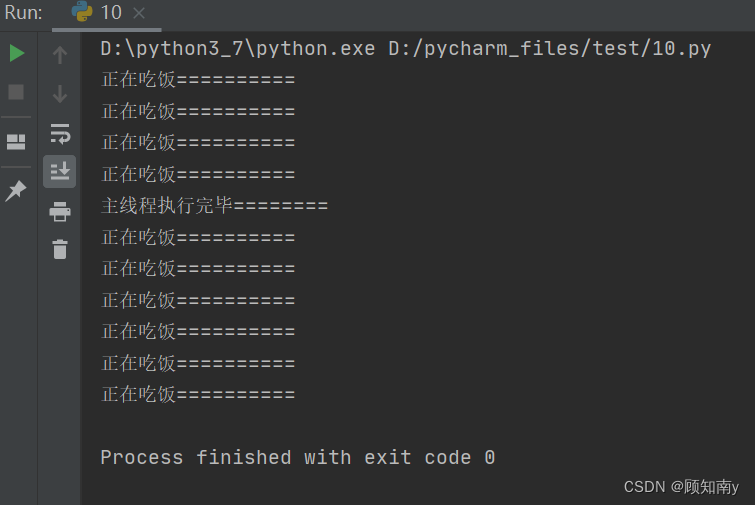
不设置守护主线程的情况下
import threading
import timedef eat():for i in range(10):print('正在吃饭==========')time.sleep(0.5)if __name__ == '__main__':# 创建子线程eat_thread = threading.Thread(target=eat,)# 启动子线程eat_thread.start()time.sleep(2)print('主线程执行完毕========')执行结果
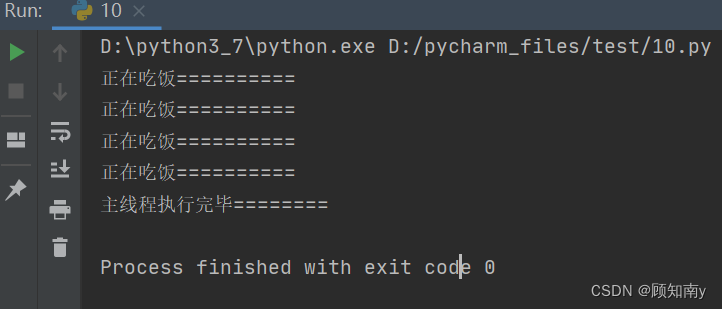
方式一守护主线程
import threading
import timedef eat():for i in range(10):print('正在吃饭==========')time.sleep(0.5)if __name__ == '__main__':# 创建子线程eat_thread = threading.Thread(target=eat, daemon=True)# 启动子线程eat_thread.start()time.sleep(2)print('主线程执行完毕========')执行结果
方式二守护主线程
import threading
import timedef eat():for i in range(10):print('正在吃饭==========')time.sleep(0.5)if __name__ == '__main__':# 创建子线程eat_thread = threading.Thread(target=eat,)# 需要写在开启子线程前面eat_thread.setDaemon(True)# 启动子线程eat_thread.start()time.sleep(2)print('主线程执行完毕========')执行结果

线程的执行顺序
一个进程里面,多个线程在执行,线程的执行是无序的,是由CPU调度决定某个线程先执行
获取当前线程的信息
1、通过current_thread方法获取线程对象的信息,例如被创建的顺序
current_thread_info = threading.current_thread()print(current_thread_info)
import threading
import timedef thread_info():time.sleep(0.5)current_thread_info = threading.current_thread()print(current_thread_info)if __name__ == '__main__':for i in range(5):sub_thread = threading.Thread(target=thread_info,)sub_thread.start()执行结果

线程间共享全局变量
多个线程都是在同一个进程中,多个线程使用的资源都是同一个进程中的资源,因此多线程间是共享全局变量
import time
import threadingdef write_date():for i in range(3):my_list.append(i)print('这是子线程写入的表:', my_list)def read_date():print('这是子线程读数据:', my_list)my_list = []
if __name__ == '__main__':write_thread = threading.Thread(target=write_date)read_thread = threading.Thread(target=read_date)write_thread.start()time.sleep(1)read_thread.start()time.sleep(1)print('这是主线程读的数据:', my_list)执行结果

线程之间共享全局变量数据出现错误问题
解决办法
- 同步:就是协同步调,按预定的先后次序进行运行。比如现实生活中的对讲机,你说一句我说一句,不能一起说
- 使用线程同步:也就是互斥锁,同一时刻只能有一个线程去操作全局变量
不使用的情况下
import threading# 定义全局变量
num = 0def sum_num1():for i in range(1000):global numnum += 1print('num1:', num)def sum_num2():for i in range(1000):global numnum += 1print('num2:', num)if __name__ == '__main__':sum1 = threading.Thread(target=sum_num1,)sum2 = threading.Thread(target=sum_num2,)sum1.start()sum2.start()执行结果

把num加大
import threading# 定义全局变量
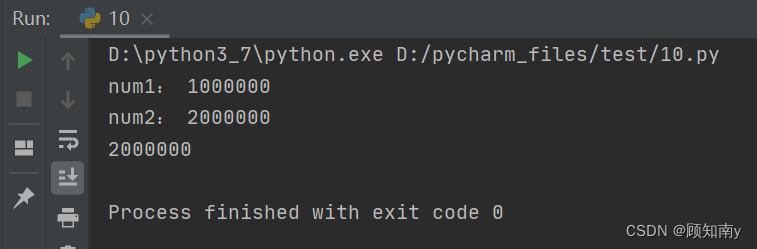
num = 0def sum_num1():for i in range(1000000): # 多加了几个0global numnum += 1print('num1:', num)def sum_num2():for i in range(1000000): # 多加了几个0global numnum += 1print('num2:', num)if __name__ == '__main__':sum1 = threading.Thread(target=sum_num1, )sum2 = threading.Thread(target=sum_num2, )sum1.start()sum2.start()
执行结果

互斥锁的使用
对共享数据进行锁定,保证同一时刻只有一个线程去操作
互斥锁是多个线程一起去抢,抢到锁的线程先执行,没有抢到的线程进行等候,等锁使用完释放后,其它等待的线程再去抢这个锁
使用
1、创建互斥锁
mutex = threading.Lock()
2、上锁
mutex .acquire()
3、释放锁
mutex .release()
import time
import threading# 定义全局变量
num = 0def sum_num1():# 上锁mutex.acquire()for i in range(1000000):global numnum += 1print('num1:', num)# 释放锁mutex.release()def sum_num2():# 上锁mutex.acquire()for i in range(1000000):global numnum += 1print('num2:', num)# 释放锁mutex.release()if __name__ == '__main__':# 创建锁mutex = threading.Lock()# 创建子线程sum1 = threading.Thread(target=sum_num1, )sum2 = threading.Thread(target=sum_num2, )# 启动子线程sum1.start()sum2.start()time.sleep(5)print(num)执行结果
死锁
一直等待对方释放锁的情况就是死锁,死锁会造成程序的停止响应,不能再处理其他任务
产生死锁的原因:没有及时或者在正确的位置释放锁
这篇关于python 多任务之多线程的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





