本文主要是介绍实战 | YOLOv10 自定义数据集训练实现车牌检测 (数据集+训练+预测 保姆级教程),希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
导读
本文主要介绍如何使用YOLOv10在自定义数据集训练实现车牌检测 (数据集+训练+预测 保姆级教程)。
YOLOv10简介
YOLOv10是清华大学研究人员在Ultralytics Python包的基础上,引入了一种新的实时目标检测方法,解决了YOLO以前版本在后处理和模型架构方面的不足。通过消除非最大抑制(NMS)和优化各种模型组件,YOLOv10在降低计算像素数的同时实现了相当的性能。大量实验证明,YOLOv10在多个模型上实现了卓越的精度-延迟权衡。
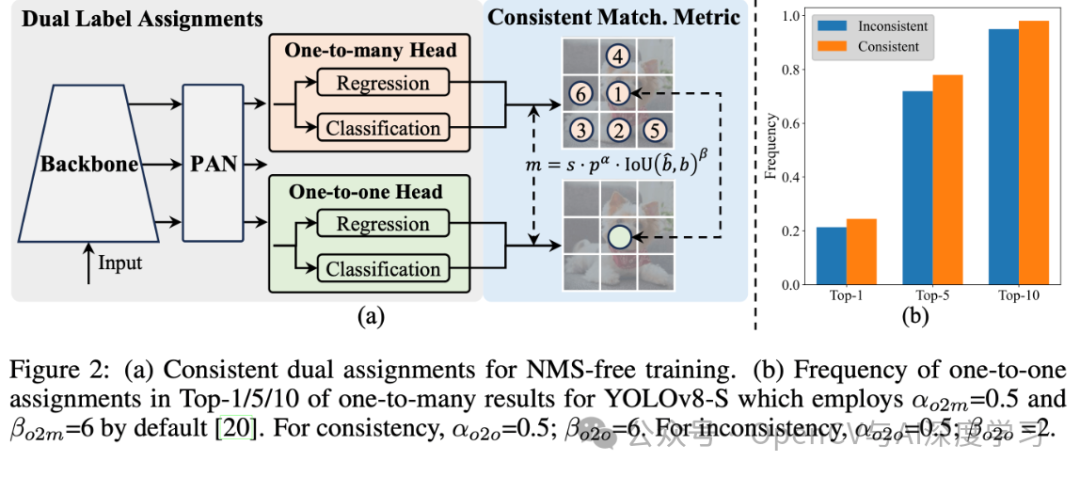
概述
实时目标检测旨在优先延迟准确的预测图像中的物体类别和位置。YOLO 系列在性能和效率之间取得了平衡,因此一直处于较低水平。然而,对 NMS 的依赖和架构的低效阻碍了性能的实现。YOLOv10 通过为无 NMS 训练引入了一致的双重分配并以提高准确性为导向的核心模型设计策略,解决了答案。
网络架构
YOLOv10 的结构建立在以前YOLO模型的基础上,同时引入了几项关键创新。模型架构由以下部分组成:
-
-
主干网: YOLOv10中的主干网负责特征提取,它使用了增强版的CSPNet(跨阶段部分网络),以改善梯度流并减少计算能力。
-
颈部:颈部设计用于汇聚不同的尺度成果,并将其传递到头部。它包括PAN(路径聚合网络)层,可实现有效的多尺度特征融合。
-
一对多头:在训练过程中为每个对象生成多个预测,以提供丰富的监督信号并提高学习准确性。
-
一头:在推理过程中选择一个对象,无需NMS,从而减少并提高结果质量。
-
主要功能
-
-
无NMS 模式:利用一致的配置来消除对NMS 的需求,从而减少错误判断。
-
整体模型设计:从业人员绩效评估和绩效评价模块,包括轻量级数据分析、通道去耦和质量引导设计。
-
增强的模型功能:应对大数据和部分自觉模块,在不增加大量计算成本的情况下提高性能。
-
模型支持:
YOLOv10有多种模型,可满足不同的应用需求:
-
-
YOLOv10-N:用于资源极其有限的环境的纳米版本。
-
YOLOv10-S:兼顾速度和精度的小型版本。
-
YOLOv10-M:通用中型版本。
-
YOLOv10-B:平衡型,宽度增加,精度更高。
-
YOLOv10-L:大型版本,精度更高,但计算资源增加。
-
YOLOv10-X:超大型版本可实现高精度和性能。
-
特性
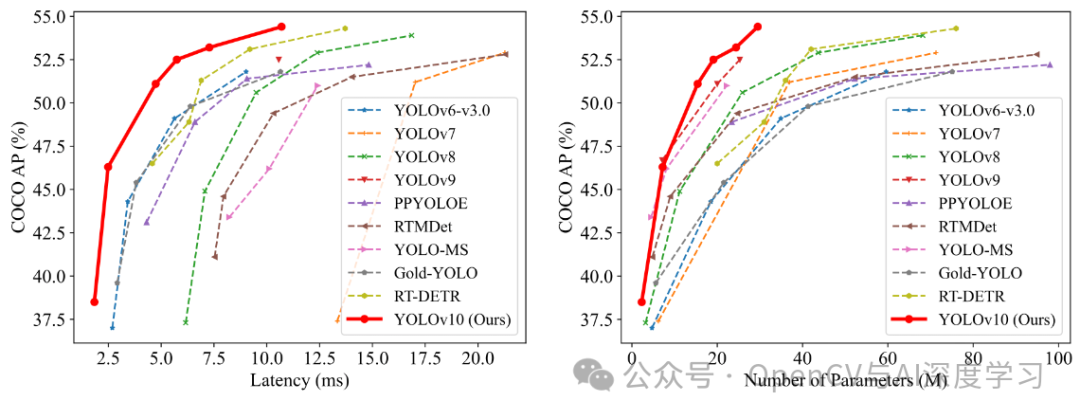
在准确性和效率方面,YOLOv10 优于YOLO 以前的版本和其他模型。例如,在 COCO 数据集上,YOLOv10-S 的速度是 RT-DETR-R18 的 1.8 倍,而 YOLOv10-B 与 YOLOv9-C 相比,在性能相同的条件下,延迟浏览器打开 46%,参数浏览器打开 25%。下图是使用 TensorRT FP16 在 T4 GPU 上的测试结果:

实验和结果
YOLOv10 在 COCO 等标准基准上进行了广泛测试,证明了卓越的性能和准确性。与先前的版本和其他当代版本相比,YOLOv10 在延迟和准确性方面都有显著提高。
YOLOv10自定义数据集训练
【1】准备数据集。数据集标注使用LabelImg,具体使用和标注可参考下面文章:
实战 | YOLOv8自定义数据集训练实现手势识别 (标注+训练+预测 保姆级教程)
这里直接给出数据集,大家可以自行下载:
https://github.com/AarohiSingla/YOLOv10-Custom-Object-Detection/tree/main/custom_dataset/dataset数据集包含300张图片样本,训练集210张,验证集60张,测试集30张。




类别只有1类,所以序号都为0。
【2】配置训练环境。
① 下载yoloV10项目:
git clone https://github.com/THU-MIG/yolov10.git② 解压后切换到yoloV10目录下,安装依赖项:
cd yolov10pip install .
③ 下载预训练模型:

import osimport urllib.request# Create a directory for the weights in the current working directoryweights_dir = os.path.join(os.getcwd(), "weights")os.makedirs(weights_dir, exist_ok=True)# URLs of the weight filesurls = ["https://github.com/jameslahm/yolov10/releases/download/v1.0/yolov10n.pt","https://github.com/jameslahm/yolov10/releases/download/v1.0/yolov10s.pt","https://github.com/jameslahm/yolov10/releases/download/v1.0/yolov10m.pt","https://github.com/jameslahm/yolov10/releases/download/v1.0/yolov10b.pt","https://github.com/jameslahm/yolov10/releases/download/v1.0/yolov10x.pt","https://github.com/jameslahm/yolov10/releases/download/v1.0/yolov10l.pt"]# Download each filefor url in urls:file_name = os.path.join(weights_dir, os.path.basename(url))urllib.request.urlretrieve(url, file_name)print(f"Downloaded {file_name}")

【3】模型训练:
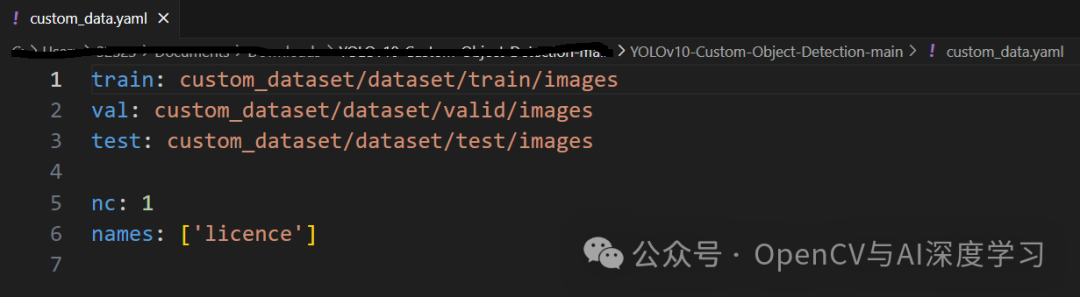
yolo task=detect mode=train epochs=100 batch=16 plots=True model=weights/yolov10n.pt data=custom_data.yamlcustom_data.yaml配置如下:
【4】 模型推理:
图片推理:
yolo task=detect mode=predict conf=0.25 save=True model=runs/detect/train/weights/best.pt source=test_images_1/veh2.jpg
from ultralytics import YOLOv10import supervision as svimport cv2classes = {0: 'licence'}model = YOLOv10('runs/detect/train/weights/best.pt')image = cv2.imread('test_images_1/veh2.jpg')results = model(source=image, conf=0.25, verbose=False)[0]detections = sv.Detections.from_ultralytics(results)box_annotator = sv.BoxAnnotator()labels = [f"{classes[class_id]} {confidence:.2f}"for class_id, confidence in zip(detections.class_id, detections.confidence)]annotated_image = box_annotator.annotate(image.copy(), detections=detections, labels=labels)cv2.imshow('result', annotated_image)cv2.waitKey()cv2.destroyAllWindows()

视频推理:
yolo task=detect mode=predict conf=0.25 save=True model=runs/detect/train/weights/best.pt source=b.mp4from ultralytics import YOLOv10import supervision as svimport cv2classes = {0: 'licence'}model = YOLOv10('runs/detect/train/weights/best.pt')def predict_and_detect(image):results = model(source=image, conf=0.25, verbose=False)[0]detections = sv.Detections.from_ultralytics(results)box_annotator = sv.BoxAnnotator()labels = [f"{classes[class_id]} {confidence:.2f}"for class_id, confidence in zip(detections.class_id, detections.confidence)]annotated_image = box_annotator.annotate(image.copy(), detections=detections, labels=labels)return annotated_imagedef create_video_writer(video_cap, output_filename):# grab the width, height, and fps of the frames in the video stream.frame_width = int(video_cap.get(cv2.CAP_PROP_FRAME_WIDTH))frame_height = int(video_cap.get(cv2.CAP_PROP_FRAME_HEIGHT))fps = int(video_cap.get(cv2.CAP_PROP_FPS))# initialize the FourCC and a video writer objectfourcc = cv2.VideoWriter_fourcc(*'MP4V')writer = cv2.VideoWriter(output_filename, fourcc, fps,(frame_width, frame_height))return writervideo_path = 'b.mp4'cap = cv2.VideoCapture(video_path)output_filename = "out.mp4"writer = create_video_writer(cap, output_filename)while True:success, img = cap.read()if not success:breakframe = predict_and_detect(img)writer.write(frame)cv2.imshow("frame", frame)if cv2.waitKey(1)&0xFF ==27: #按下Esc键退出breakcap.release()writer.release()

—THE END—
这篇关于实战 | YOLOv10 自定义数据集训练实现车牌检测 (数据集+训练+预测 保姆级教程)的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!




