本文主要是介绍编译原理-语法分析(实验 C语言),希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
语法分析
1. 实验目的
编制一个递归下降分析程序,实现对词法分析程序所提供的单词序列的语法检查和结构分析
2. 实验要求
利用C语言编制递归下降分析程序,并对简单语言进行语法分析
2.1 待分析的简单语言的语法
用扩充的BNF表示如下:
- <程序> ::= begin<语句串> end
- <语句串> ::= <语句> {;<语句>}
- <语句> ::= <赋值语句>
- <赋值表达式> ::= ID := <表达式>
- <表达式> ::= <项> { + <项> | - <项> }
- <项> ::= <因子> { * <因子> | / <因子>}
- <因子> ::= ID | NUM | (<表达式>)
2.2 实验要求说明
输入单词串,以“#”结束,如果是文法正确的句子,则输出成功信息,答应“success”,否则输出“error”
例如:
输入 begin a := 9; x := 2 * 3; b := a + x end #
输出 success
输入 x := a + b * c end #
输出 error
3. 语法分析程序的算法思想
-
主程序示意图如图
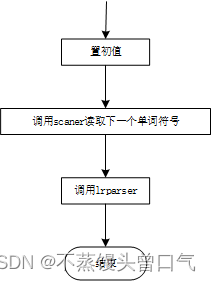
-
递归下降分析程序示意图如图
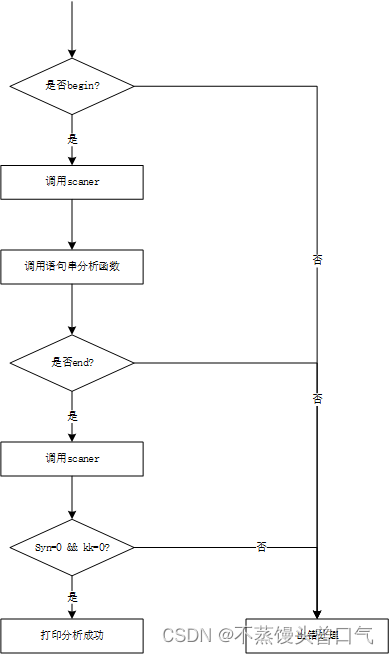
-
语句串分析过程示意图如图
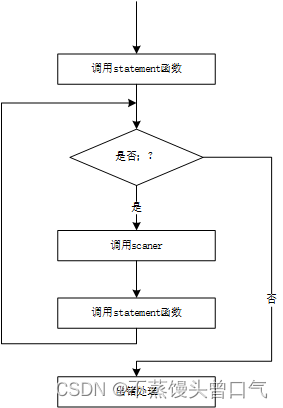
-
statement语句分析函数流程如图
statement语句分析函数示意图
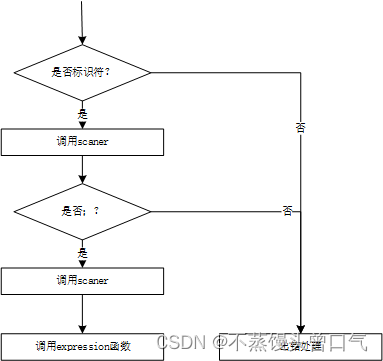
expression表达式分析函数示意图
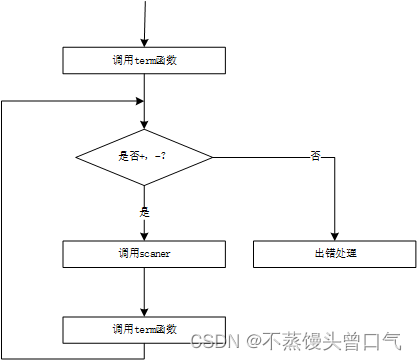
term分析函数示意图
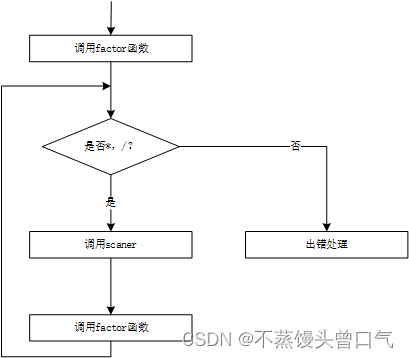
factor分析过程示意图

4. 实验源代码
源代码:
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
#define _KEY_WORD_END "waiting for your expanding"//结构体
typedef struct
{int typenum;char *word;
}WORD;//函数声明
char m_getch();
void getbc();
void concat();
int letter();
int digit();
int reserve();
void retract();
char *dtb();
WORD *scaner();
void lrparser(WORD *word);
WORD *yucu(WORD *word);
WORD *factor(WORD *word);
WORD *statement(WORD *word);
WORD *expression(WORD *word);
WORD *term(WORD *word);char input[255];
char token[255] = "";
int p_input;
int p_token;
char ch;
int kk = 0;
char *rwtab[] = {"begin","if","then","while","do","end",_KEY_WORD_END};int main(void)
{int over = 1;WORD *oneword = new WORD;//new为c++中的关键字 在使用new进行内存分配时,需要包含相关类型的头文件。#include <iostream>while(1) //无限循环{printf("Enter Your words(end with #):");scanf("%[^#]",input); //读入源程序字符串到缓冲区,以#结束,允许多行输入p_input = 0;printf("Your words: \n%s\n",input);oneword = scaner();lrparser(oneword);while(getchar() != '\n'){}printf("press # to exit:");if(getchar() == 35){return 0;}while(getchar() != '\n'){}}
}// 词法分析
// 从输入缓冲区读取一个字符到ch中
char m_getch()
{ch = input[p_input];p_input = p_input + 1;return(ch);
}// 去掉空白符号
void getbc()
{while(ch == ' ' || ch == 10){ch = input[p_input];p_input = p_input + 1;}
}//拼写单词
void concat()
{token[p_token] = ch;p_token = p_token + 1;token[p_token] = '\0';
}//判断是否字母
int letter()
{if(ch >= 'a' && ch <= 'z' || ch >= 'A' && ch <= 'Z')return 1;else return 0;
}//判断是否数字
int digit()
{if(ch >= '0' && ch <= '9')return 1;else return 0;
}// 检索关键字表格
int reserve()
{int i = 0;while(strcmp(rwtab[i],_KEY_WORD_END)){if(!strcmp(rwtab[i],token)){return i + 1;}i = i + 1;}return 10;
}//回退一个字符
void retract()
{p_input = p_input - 1;
}//数字转换成二进制
char *dtb(char *buffer)
{int j = 0;int flag = 0;int k = (sizeof(char)<<3) - 1;char temp = ch - '0';for(int i = 0; i < (sizeof(char)<<3); i++,k--){if((temp >> k & 0x01) == 0){if(flag == 1){buffer[j++] = 0 + '0';} }else{flag = 1;buffer[j++] = (temp >> k & 0x01) + '0';}}buffer[j] = 0;return buffer;// Converts the ch to binary;
}WORD *scaner()
{WORD *myword = (WORD *)malloc(sizeof(WORD));myword -> typenum = 10;myword -> word = "";p_token = 0;m_getch();getbc();if(letter()){while(letter() || digit()){concat();m_getch();}retract();myword -> typenum = reserve();myword -> word = token;return myword;}else if(digit()){while(digit()){concat();m_getch();}retract();myword -> typenum = 11;myword -> word = token;return myword;}else{switch(ch){case'=':m_getch();if(ch == '='){myword -> typenum = 39;myword -> word = "==";return myword;}retract();myword->typenum = 25;myword->word = "=";return myword;break;case'+':myword->typenum = 13;myword->word = "+";return myword;break;case'-':myword->typenum = 14;myword->word = "-";return myword;break;case'*':myword->typenum = 15;myword->word = "*";return myword;break;case'/':myword->typenum = 16;myword->word = "/";return myword;break;case'(':myword->typenum = 27;myword->word = "(";return myword;break;case')':myword->typenum = 28;myword->word = ")";return myword;break;case'[':myword->typenum = 28;myword->word = "[";return myword;break;case']':myword->typenum = 29;myword->word = "]";return myword;break;case'{':myword->typenum = 30;myword->word = "{";return myword;break;case'}':myword->typenum = 31;myword->word = "}";return myword;break;case',':myword->typenum = 32;myword->word = ",";return myword;break;case':':m_getch();if(ch == '='){myword->typenum = 18;myword->word = ":=";return myword;}retract();myword->typenum = 17;myword->word = ":";return myword;break;case';':myword->typenum = 26;myword->word = ";";return myword;break;case'>':m_getch();if(ch=='='){myword->typenum = 24;myword->word = ">=";return myword;}retract();myword->typenum = 23;myword->word = ">";return myword;break;case'<':m_getch();if(ch=='='){myword->typenum = 22;myword->word = "<=";return myword;}else if(ch == '>'){myword->typenum = 21;myword->word = "<>";}retract();myword->typenum = 20;myword->word = "<";return myword;break;case'!':m_getch();if(ch=='='){myword->typenum = 40;myword->word = "!=";return myword;}retract();myword->typenum = -1;myword->word = "ERROR";return myword;break;case'\0':myword->typenum = 1000;myword->word = "OVER";return myword;break;default:myword->typenum = 0;myword->word = "#";return myword;}}
}// 语法分析 判断begin和end
void lrparser(WORD *word)
{WORD *w;if(word == NULL){return;}if(word -> typenum == 1) //种别码为1,有关键字begin{ free(word); //释放空间w = scaner();w = yucu(w);if(w == NULL){return ;}if(w -> typenum == 6) //种别码为6,有关键字end{free(w);w = scaner();if(w -> typenum==0&&kk==0)free(w);printf("success 成功\n");}else{free(w);if(kk!=1)printf("lack END error! 错误 缺少END\n"); //缺少endkk = 1;}}else{free(word);printf("Begin error! begin 错误\n");//无begin报错kk = 1;}return ;
}//语句以;号结尾
WORD *yucu(WORD *word)
{WORD *w;w = statement(word); //语句段分析if(w == NULL){return NULL;}while(w->typenum == 26) //有;号{free(w);w = scaner();w = statement(w);if(w == NULL){return NULL;}}return w;
}//语句段分析
WORD *statement(WORD *word)
{WORD *w;if(word == NULL){return NULL;}if(word->typenum == 10) //字符串{ free(word);w = scaner();if(w->typenum == 18) //赋值符号{ free(w);w = scaner();w = expression(w); //表达式if(w == NULL){return NULL;}return w;}else{free(w);printf("assignment token error! 赋值号错误\n");return NULL;kk = 1;}}else{free(word);printf("statement error! 语句错误\n");return NULL;}
}//表达式处理
WORD *expression(WORD *word)
{WORD *w;w = term(word);if(w == NULL){return NULL;}// +-法while(w -> typenum == 13 || w -> typenum == 14){free(w);w = scaner();w = term(w);if(w == NULL){return NULL;}}return w;
}WORD *term(WORD *word)
{WORD *w;w = factor(word);if(w == NULL){return NULL;}// */法while(w -> typenum == 15 || w -> typenum == 16){free(w);w = scaner();w = factor(w);if(w == NULL){return NULL;}}return w;
}//括号分析
WORD *factor(WORD *word)
{WORD *w;if(word == NULL){return NULL;}if(word -> typenum == 10 || word -> typenum == 11){free(word);w = scaner();}else if(word -> typenum == 27){free(word);w = scaner();w = expression(w);if(w == NULL){return NULL;}if(w -> typenum == 28){free(w);w = scaner();}else{free(w);printf(") error! ')' 错误\n");kk = 1;return NULL;}}else{free(word);printf("expression error! 表达式错误\n");kk = 1;return NULL;}return w;
}5. 实验结果
- 输入正确语法

- 输入任意字符后继续输入无begin语法

- 输入赋值号错误的语法

6. 实验小结
-
将main函数中的输入输出语句放入无限循环中,使其不断调用,直至键盘输入#号
int main(void) {int over = 1;WORD *oneword = new WORD;//new为c++中的关键字 在使用new进行内存分配时,需要包含相关类型的头文件。#include <iostream>while(1) //无限循环{printf("Enter Your words(end with #):");scanf("%[^#]",input); //读入源程序字符串到缓冲区,以#结束,允许多行输入p_input = 0;printf("Your words: \n%s\n",input);oneword = scaner();lrparser(oneword);while(getchar() != '\n'){}printf("press # to exit:");if(getchar() == 35){return 0;}while(getchar() != '\n'){}} } -
使用原先词法分析中所写的代码,语法分析时在词法分析通过的前提下进行的
-
对代码进行语法检测需判断begin和end这两个开始和结束符
-
判断每个语句段是以;号结尾
-
判断语句段中的字符串,赋值符,表达式是否正确
-
判断 + - * / 是否正确
这篇关于编译原理-语法分析(实验 C语言)的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!








