本文主要是介绍Solr 6.2.1 集群部署,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
1. 依赖环境
1) JDK1.8
2) Zookeeper
2. 安装包在所有节点解压,无需做任何更改
3. 启动Solr
在每个节点执行 $SOLR_HOME/bin/solr start -cloud -s $SOLR_HOME/server/solr -z center-datanode11:2181,center-datanode12:2181,center-namenode:2181
参数说明:-z 指定zookeeper节点
4. 创建Collection
1) 创建配置文件
① 进入$SOLR_HOME/server/solr/configsets目录
② 复制basic_configs目录,并重命名为raduserlog_configs(/server/solr/configsets/raduserlog_configs/conf)
③ 进入raduserlog_configs/conf目录,修改managed-schema文件
a) 增加索引字段(删除原来文件中的name=”id”的行),字段名可以随意命名。

修改标签uniqueKey为rowkey

2) 上传配置文件(蓝色标记的内容不是固定的)
$SOLR_HOME/server/scripts/cloud-scripts/zkcli.sh -zkhost center-datanode11:2181,center-datanode12:2181,center-namenode:2181 -cmd upconfig -confdir $SOLR_HOME/server/solr/configsets/raduserlog_configs/conf -confname raduserlog_configs
3) 创建collection(蓝色标记的内容不是固定的)
curl 'http://1.1.1.1:8983/solr/admin/collections?action=CREATE&name=raduserlog&numShards=3&replicationFactor=1&collection.configName=raduserlog_configs'
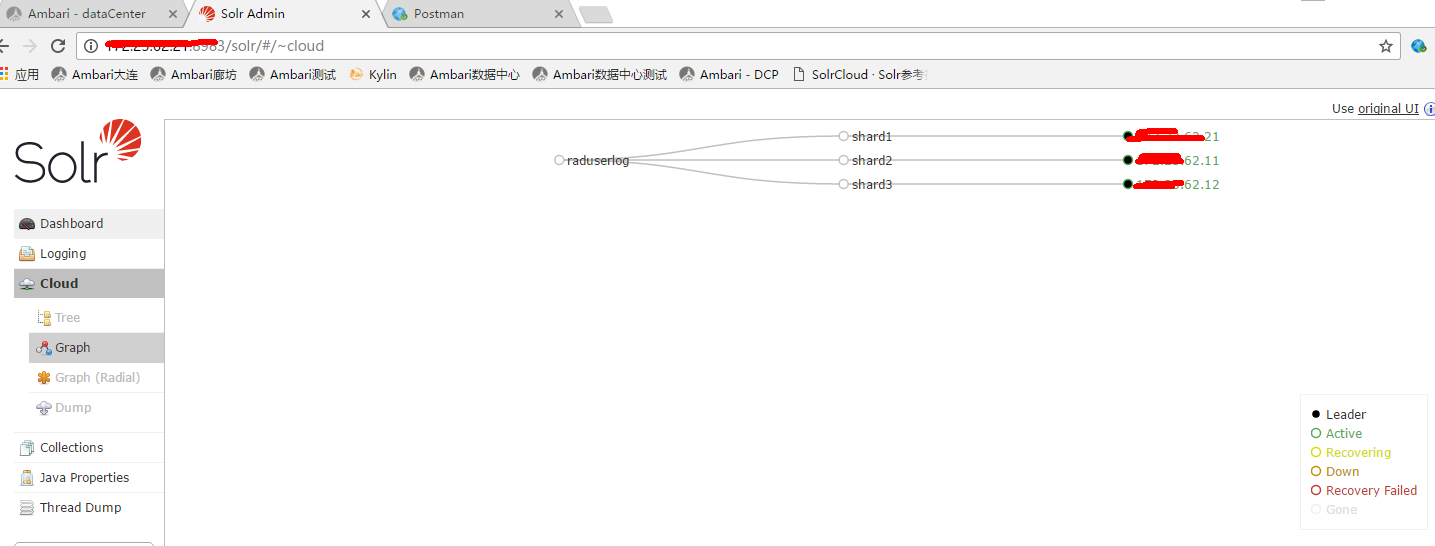
5. 查看solr管理页面
http://1.1.1.1:8983/solr/#/~cloud
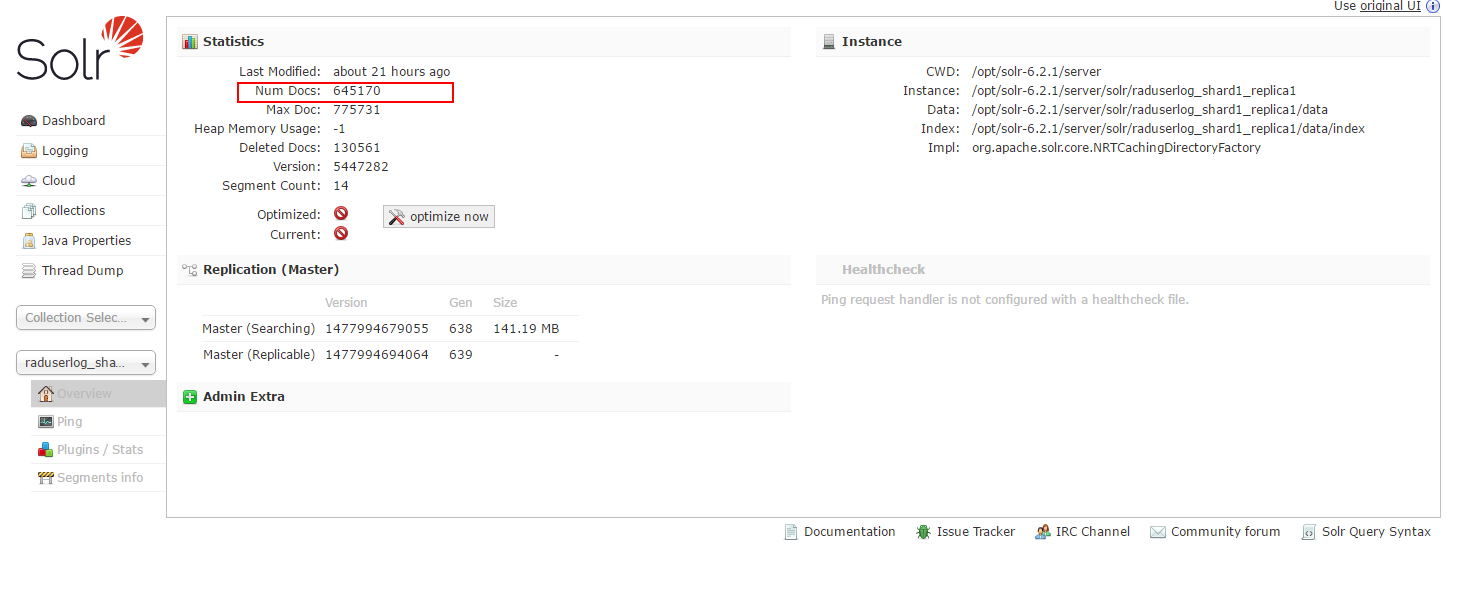
查看任意节点上的doc数量(这里仅仅是一个节点上的数量)
6. 通过JAVA代码访问Solr
package cn.bfire.solr;import org.apache.commons.logging.Log;
import org.apache.commons.logging.LogFactory;
import org.apache.solr.client.solrj.SolrQuery;
import org.apache.solr.client.solrj.impl.CloudSolrClient;
import org.apache.solr.client.solrj.response.QueryResponse;
import org.apache.solr.common.SolrDocument;
import org.apache.solr.common.SolrDocumentList;
import org.apache.solr.common.SolrInputDocument;import java.util.ArrayList;
import java.util.Collection;
import java.util.List;public class SolrCloudTest {public static final Log LOG = LogFactory.getLog(SolrCloudTest.class);private static CloudSolrClient cloudSolrClient;private static String defaultCollection = "raduserlog";static {final List<String> zkHosts = new ArrayList<String>();zkHosts.add("1.1.1.1:2181");zkHosts.add("1.1.1.2:2181");zkHosts.add("1.1.1.3:2181");cloudSolrClient = new CloudSolrClient.Builder().withZkHost(zkHosts).build();final int zkClientTimeout = 10000;final int zkConnectTimeout = 10000;cloudSolrClient.setDefaultCollection(defaultCollection);cloudSolrClient.setZkClientTimeout(zkClientTimeout);cloudSolrClient.setZkConnectTimeout(zkConnectTimeout);}private void addIndex(CloudSolrClient cloudSolrClient) throws Exception {Collection<SolrInputDocument> docs = new ArrayList<SolrInputDocument>();for (int i = 0; i <= 100; i++) {SolrInputDocument doc = new SolrInputDocument();String key = "";key = String.valueOf(i);doc.addField("rowkey", key);doc.addField("usermac", key + "usermac");doc.addField("userid", key + "userid");doc.addField("usertype", key + "usertype");doc.addField("city_id", key + "city_id");docs.add(doc);}LOG.info("docs info:" + docs + "\n");cloudSolrClient.add(docs);cloudSolrClient.commit();}public void search(CloudSolrClient cloudSolrClient, String Str) throws Exception {SolrQuery query = new SolrQuery();query.setRows(100);query.setQuery(Str);LOG.info("query string: " + Str);QueryResponse response = cloudSolrClient.query(query);SolrDocumentList docs = response.getResults();System.out.println("文档个数:" + docs.getNumFound()); //数据总条数也可轻易获取System.out.println("查询时间:" + response.getQTime());System.out.println("查询总时间:" + response.getElapsedTime());String rowkey = (String) doc.getFieldValue("rowkey");System.out.println(rowkey);}public static void main(String[] args) throws Exception {cloudSolrClient.connect();SolrCloudTest solrt = new SolrCloudTest();
// solrt.addIndex(cloudSolrClient);solrt.search(cloudSolrClient, "userid:11111");cloudSolrClient.close();}
}
pom文件
<dependency><groupId>org.apache.solr</groupId><artifactId>solr-solrj</artifactId><version>6.2.1</version><exclusions><exclusion><groupId>org.slf4j</groupId><artifactId>slf4j-api</artifactId></exclusion></exclusions></dependency>这篇关于Solr 6.2.1 集群部署的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







