本文主要是介绍白嫖google-GPU: 如何使用colab,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
Google Colab
使用Google Colab,我们可以免费获取每次12个小时的gpu使用,如果使用时间预计超过12个小时,那么我么需要设置断点保存。下面是google colab的使用方法。
注意: 不要长时间占用,否则谷歌会回收你的使用资格。用一段时间之后要休息一段时间再使用
1. 注册谷歌账号
当然注册之前首先要确保你能访问到谷歌。具体实现自己处理
2. 访问谷歌云端硬盘并创建资源
- 在谷歌drive中新建文件夹,可以命名为colab。

-
上传资源并挂载硬盘到

-
进入到colab文件夹下,右键→上传文件夹:将准备好的文件上传。最好是压缩文件,这样速度相对会快一些
-
在colab文件夹下新建ipynb文件,名字随意。然后进入文件进行配置

-
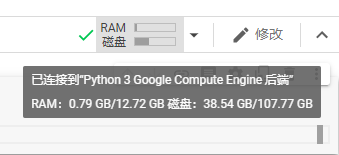
连接后如下:
这个磁盘空间好像是随机的,但是起始占用好像都是38左右
- 修改笔记本设置如下:

设置点进去之后你可以选择GPU或者TPU
- 挂载硬盘到colab:我们可以在colab中访问google drive上的内容,
你可以把.ipynb 看成linux命令行,使用系统命令时,前面加 %,调用程序,前面加!

⭐现在的话已经不需要下面这些手动挂载云盘到服务器的步骤了。硬盘默认已挂载,可以直接使用,
############# 以下操作已经不需要 #################
import os
from google.colab import drive
drive.mount("/content/drive")
运行后,会有如下显示:

点击后面的链接,谷歌账号登录,进去之后同意,然后复制验证码,输入到这个框中,就可以创建完成了
############# 以上操作已经不需要 ####################
3. 文件夹结构查看
在 .ipybn 文件界面的左边,会有文件夹目录
刚进去时我们是在这个文件夹,点击文件夹图标。


点击之后可以看到服务器端的文件结构
3. 创建自己的工程
1. 数据文件拷贝与工程创建
- 将我们的数据集打包压缩,上传到云端硬盘,我的压缩文件在下面,没有展示出来

-
在服务器端创建工程文件夹:注意不要创建在云端硬盘所在的文件夹(
drive/MyDrive)下。%mkdir /home/yolov5 -
将压缩文件copy到自己想使用的工程文件夹,
%cp /content/drive/MyDrive/Colab/VOC2007.zip /home/yolov5/VOC2007.zip %cd /home/yolov5 !git colne https://github.com/xxx/yolov5.git -
解压数据文件到指定文件夹下。
2. 小技巧
-
我们在笔记本(
.ipynb)中写的命令操作会保存,写好之后,下次直接进入笔记本直接执行自己的操作就可以了。 -
普通用户服务器最多连续使用12小时,升级到pro会得到更强的算例以及更长的操作时间,大概24小时吧。时间到了服务器中你的东西都会被清空,只保留你的云端硬盘中的文件。
-
系统会检测你是否离开,长时间没有操作,就会认定你离开,会提示你验证一下。如果没有验证,认定离开,会停掉你的当前工作。使用期间注意时不时的去看一下。

-
你的数据文件也可以放在colab中,将我们要使用的数据或者代码事先打包压缩,然后在本地创建一个文件夹,将打包好的内容复制到这个文件夹下,解压后使用。这样就会有速度上的提高。下次使用时copy一下就可以了。copy的速度还是很快的
-
代码中设置你的训练结果保存到谷歌云端硬盘中。云端硬盘在服务器中的路径是:
/content/drive/MyDrive/Colab.这样你就不用害怕被清空了。 -
离开比较频繁或者连续使用频繁,谷歌会暂时停掉你的使用。对每个用户都有设定的使用时间,所以尽量不要连续使用或者频繁离开状态,被停掉使用之后会有几天不能使用。
-
模型训练的代码写一份专门针对cloab使用的代码,主要就是路径修改一下,放在github中,把git命令以及运行命令写在笔记本文件中,下次微调之后就可以直接使用了。
后续使用
你可以通过终端命令执行你的文件夹中的代码,也可以再ipynb文件中重写你的方法,看情况使用。
这篇关于白嫖google-GPU: 如何使用colab的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






