本文主要是介绍联邦学习在non-iid数据集上的划分和训练——从零开始实现,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
虽然网上已经有了很多关于Dirichlet分布进行数据划分的原理和方法介绍,但是整个完整的联邦学习过程还是少有人分享。今天就从零开始实现
加载FashionMNIST数据集
import torch
from torchvision import datasets, transforms# 定义数据转换
transform = transforms.Compose([transforms.ToTensor(),transforms.Normalize((0.5,), (0.5,))
])# 加载训练和测试数据集
train_dataset = datasets.FashionMNIST(root='./data', train=True, download=True, transform=transform)
test_dataset = datasets.FashionMNIST(root='./data', train=False, download=True, transform=transform)
定义Dirichlet分布的划分函数
这里的写法是其中一种,也可以参考其它大神的写法。
具体Dirichlet划分的原理也可以参考下面的博客:
联邦学习:按Dirichlet分布划分Non-IID样本 - orion-orion - 博客园 (cnblogs.com)
import numpy as npdef dirichlet_distribution_noniid(dataset, num_clients, alpha):# 获取每个类的索引class_indices = [[] for _ in range(10)]for idx, (image, label) in enumerate(dataset):class_indices[label].append(idx)# 使用Dirichlet分布进行数据划分client_indices = [[] for _ in range(num_clients)]for class_idx in class_indices:np.random.shuffle(class_idx)proportions = np.random.dirichlet([alpha] * num_clients)proportions = (np.cumsum(proportions) * len(class_idx)).astype(int)[:-1]client_split = np.split(class_idx, proportions)for client_idx, client_split_indices in enumerate(client_split):client_indices[client_idx].extend(client_split_indices)return client_indices
将数据集划分给各客户端
这里的代码操作核心在于,对数据加载器DataLoader中的Subset的理解,这个函数是根据索引将数据集划分为子数据集,以前我知道它是在做什么,但是一直不太明白用法,最终在ChatGPT的帮助下完成了:
num_clients = 10
alpha = 0.5 #non-iid程度的超参数,我喜欢用0.5和0.3
client_indices = dirichlet_distribution_noniid(train_dataset, num_clients, alpha)# 创建客户端数据加载器
from torch.utils.data import DataLoader, Subsetclient_loaders = [DataLoader(Subset(train_dataset, indices), batch_size=32, shuffle=True) for indices in client_indices]
定义模型、训练函数和测试函数
import torch.nn as nn
import torch.optim as optim
import matplotlib.pyplot as pltclass SimpleNN(nn.Module):def __init__(self):super(SimpleNN, self).__init__()self.flatten = nn.Flatten()self.fc1 = nn.Linear(28*28, 128)self.fc2 = nn.Linear(128, 10)def forward(self, x):x = self.flatten(x)x = torch.relu(self.fc1(x))x = self.fc2(x)return xdef train(model, train_loader, criterion, optimizer, device, epochs=5):model.train()model.to(device)for epoch in range(epochs):running_loss = 0.0for images, labels in train_loader:images, labels = images.to(device), labels.to(device)optimizer.zero_grad()outputs = model(images)loss = criterion(outputs, labels)loss.backward()optimizer.step()running_loss += loss.item()print(f"Epoch [{epoch+1}/{epochs}], Loss: {running_loss/len(train_loader):.4f}")def test(model, test_loader, device):model.eval()model.to(device)correct = 0total = 0with torch.no_grad():for images, labels in test_loader:images, labels = images.to(device), labels.to(device)outputs = model(images)_, predicted = torch.max(outputs.data, 1)total += labels.size(0)correct += (predicted == labels).sum().item()accuracy = correct / totalreturn accuracy
进行训练并记录测试准确度
# 选择设备
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')# 创建模型和损失函数
model = SimpleNN()
criterion = nn.CrossEntropyLoss()
optimizer = optim.SGD(model.parameters(), lr=0.01)# 训练和测试数据加载器
test_loader = DataLoader(test_dataset, batch_size=32, shuffle=False)# 记录每轮测试准确度
test_accuracies = []# 在每个客户端上进行训练并测试
for i, client_loader in enumerate(client_loaders):print(f"Training on client {i+1}")train(model, client_loader, criterion, optimizer, device)accuracy = test(model, test_loader, device)test_accuracies.append(accuracy)print(f"Test Accuracy after client {i+1}: {accuracy:.4f}")# 绘制测试准确度变化图
plt.figure(figsize=(10, 5))
plt.plot(range(1, num_clients + 1), test_accuracies, marker='o')
plt.title('Test Accuracy after Training on Each Client')
plt.xlabel('Client')
plt.ylabel('Test Accuracy')
plt.ylim(0, 1)
plt.grid(True)
plt.show()
一些踩过的坑
Expected more than 1 value per channel when training, got input size torch.Size
解决方案
这里可能是当UE数量让数据集没法整除的时候,出现了多余的batch。
设置 batch_size>1, 且 drop_last=True
DataLoader(train_set, batch_size=args.train_batch_size,num_workers=args.num_workers, shuffle=(train_sampler is None), drop_last=True, sampler = train_sampler)
RuntimeError: output with shape [1, 28, 28] doesn’t match the broadcast shape [3, 28, 28]
错误是因为图片格式是灰度图只有一个channel,需要变成RGB图才可以,所以需要在对图片的处理transforms里面修改:
transform = transforms.Compose([transforms.ToTensor(),transforms.Lambda(lambda x: x.repeat(3,1,1)),# 增加这一行transforms.Normalize(mean=(0.5, 0.5, 0.5), std=(0.5, 0.5, 0.5))])
运行结果
将以上的代码拼接起来,就能够正常跑起来,我也已经在自己的电脑上验证过了。
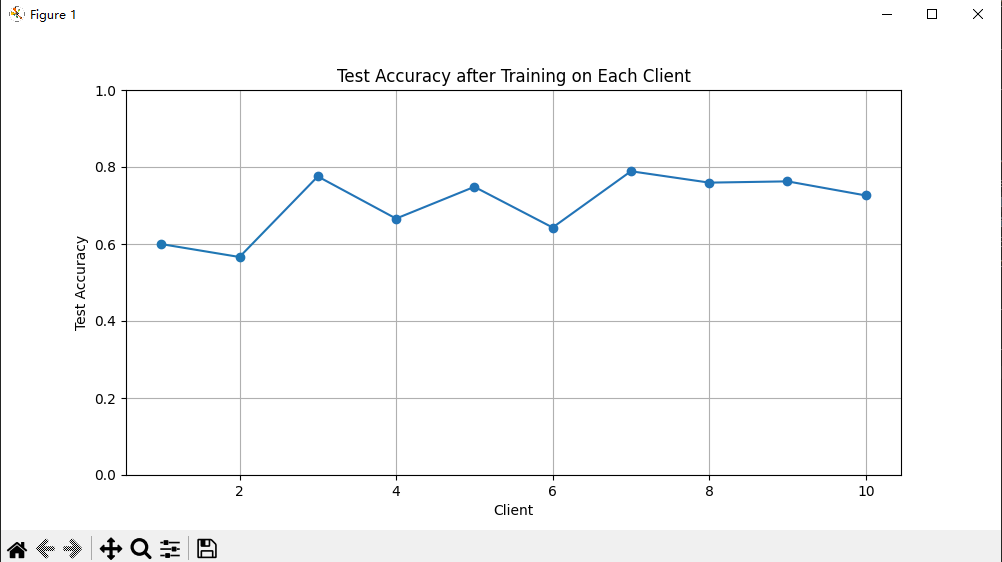
当然了,上面画的是一次epoch的各个client的准确度,进行多次epoch的训练可以自己再修改。
这篇关于联邦学习在non-iid数据集上的划分和训练——从零开始实现的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






