本文主要是介绍orbslam2代码解读(1):数据预处理过程,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
写orbslam2代码解读文章的初衷
首先最近陆陆续续花了一两周时间学习视觉slam,因为之前主要是做激光slam,有一定基础所以学的也比较快,也是看完了视觉14讲的后端后直接看orbslam2的课,看的cvlife的课(课里大部分是代码的解读所以还是需要一定的视觉slam基础),但是说实话课是看完了,其实还是会有一些疑问,想着通过自己整体再梳理一遍,加深印象的同时能够解决自己的疑惑。最后一点这个课的课件真的乱!!!最好通过自己的整理把整个框架串起来理解。后续的代码讲解流程主要围绕单目来展开,因为单目相对而言过程更复杂,而双目和rgbd因为有深度信息,所以了解单目之后,它们的处理过程也更容易了解
论文代码的整体框架图
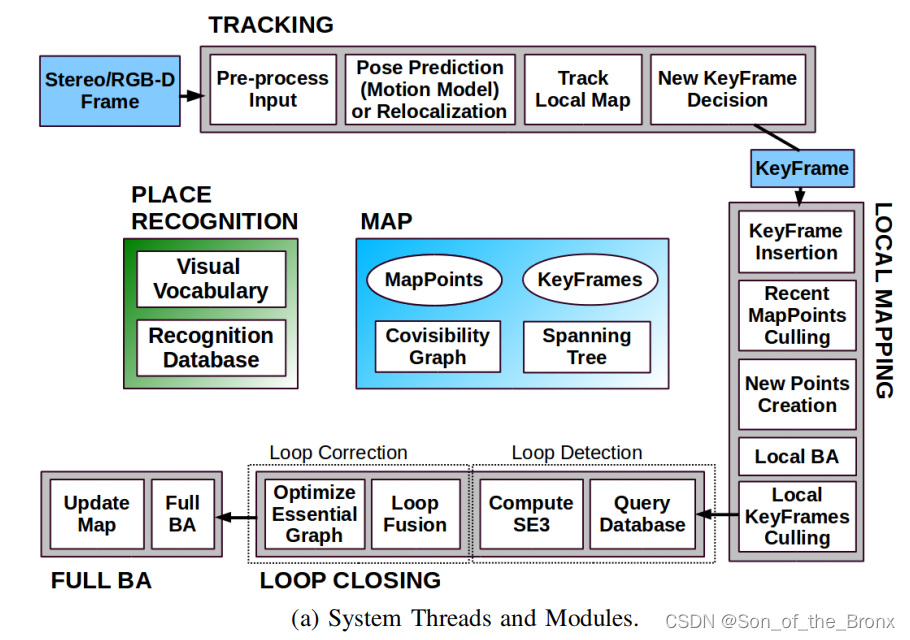
原论文的插图:
cvlife课中转换成中文的框架图:
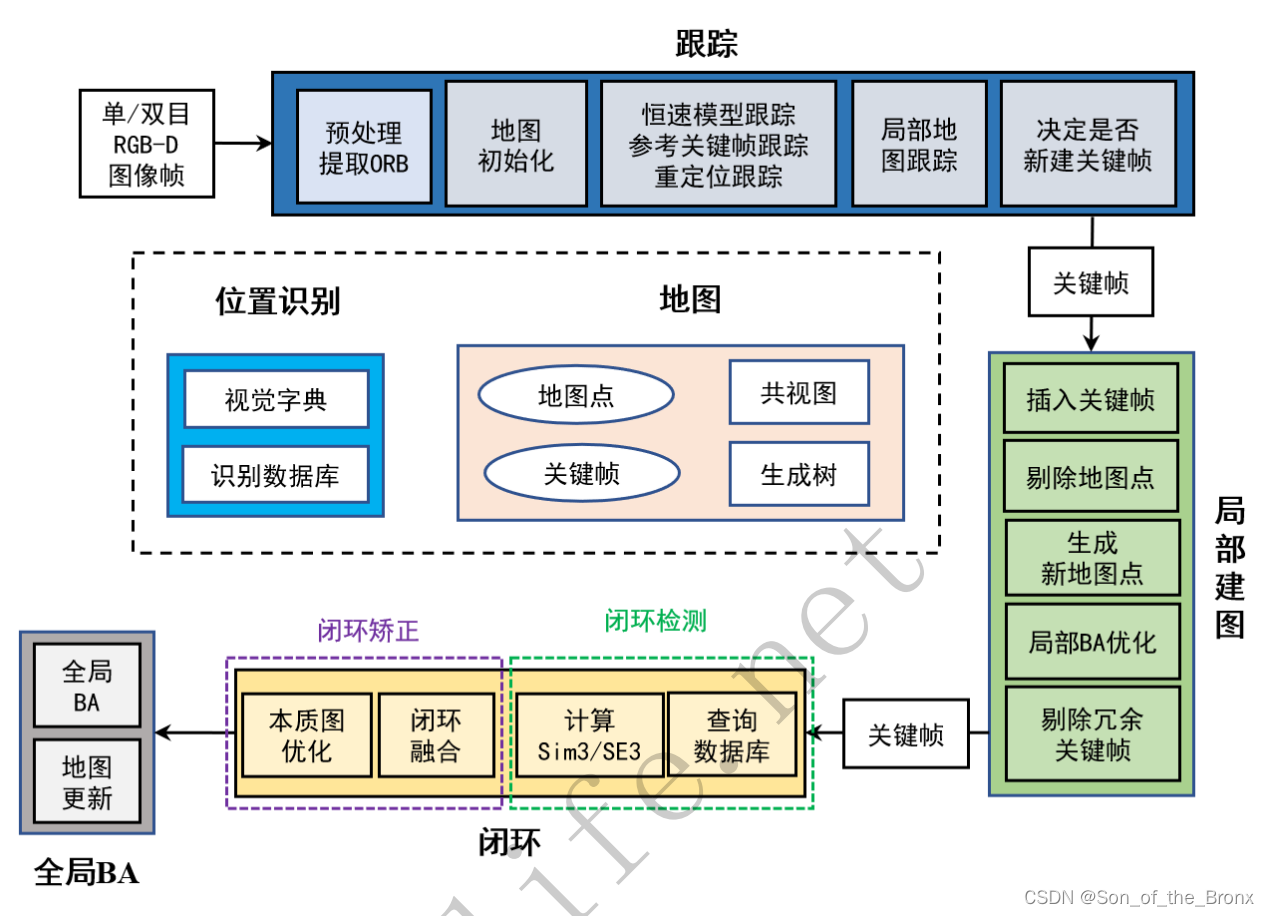
内容都是一致的,分成三个主要的线程:
- 跟踪tracking线程。求解当前图像帧在世界坐标系下的位姿,处理的是任意普通帧,完成定位的功能。
- 局部建图localmapping线程。根据产生的新关键帧产生新的地图点,以便后续跟踪的时候pnp的时候用,还有需要局部BA(只优化局部关键帧的位姿)。
- 回环Loop closing线程。根据localmapping线程传过来的关键帧进行回环检测,如果有候选回环帧就计算sim3,修正当前关键帧及其共视关键帧的位姿和地图点,然后进行本质图优化(仅优化位姿),最后就是全局BA(优化地图点和位姿)。
SLAM系统的运行流程
主函数
首先看mono_tum.cc 简化版的主函数(单目情况):
int main(int argc, char **argv)
{LoadImages(strFile, vstrImageFilenames, vTimestamps);ORB_SLAM2::System SLAM(argv[1],argv[2],ORB_SLAM2::System::MONOCULAR,true);for(int ni=0; ni<nImages; ni++){im = cv::imread();SLAM.TrackMonocular(im,tframe);}SLAM.Shutdown();SLAM.SaveKeyFrameTrajectoryTUM("KeyFrameTrajectory.txt");
}
- 声明了一个单目的SLAM对象。
- 遍历数据集的图像并且传给SLAM对象的单目track函数。
- 最后关闭SLAM并且保存关键帧的轨迹。
后续调用的函数
SLAM.TrackMonocular(im,tframe)
这个SLAM.TrackMonocular(im,tframe);函数里主要是通过mpTracker来进行跟踪并且最终返回当前图像帧的位姿估计结果。
//获取相机位姿的估计结果cv::Mat Tcw = mpTracker->GrabImageMonocular(im,timestamp);
mpTracker->GrabImageMonocular(im,timestamp)
这个mpTracker->GrabImageMonocular(im,timestamp)函数处理过程:
- 如果图像是彩色图,就转成灰度图
- 如果当前帧是初始化的帧,那么在构建Frame的时候,提取orb特征点数量为正常的两倍(目的就是能够在初始化的时候有更多匹配点对),如果是普通帧,就正常构建Frame。
- 接着就是调用tracking线程中的
Track()函数。(这个下一篇再描述) - 返回当前图像帧的位姿估计结果。
这个mpTracker->GrabImageMonocular(im,timestamp)函数对应第3、4步骤
// Step 3 :跟踪Track();//返回当前帧的位姿return mCurrentFrame.mTcw.clone();
数据处理流程
数据处理主要发生在mpTracker->GrabImageMonocular(im,timestamp)函数中第2步:根据当前帧灰度图构造Frame对象。
// Step 2 :构造Frame//判断该帧是不是初始化if(mState==NOT_INITIALIZED || mState==NO_IMAGES_YET) //没有成功初始化的前一个状态就是NO_IMAGES_YETmCurrentFrame = Frame(mImGray,timestamp,mpIniORBextractor, //初始化ORB特征点提取器会提取2倍的指定特征点数目mpORBVocabulary,mK,mDistCoef,mbf,mThDepth);elsemCurrentFrame = Frame(mImGray,timestamp,mpORBextractorLeft, //正常运行的时的ORB特征点提取器,提取指定数目特征点mpORBVocabulary,mK,mDistCoef,mbf,mThDepth);
Frame的构造流程
step1
普通帧的id自增,注意普通帧和关键帧的id并不一样,它们分别是Frame和KeyFrame类中的一个静态变量,普通帧的id可能只是为了统计处理了多少个图像,而关键帧的id需要结合后续的回环检测和全局BA,又或者是共视关键帧等等去使用。
step2
设置图像金字塔的参数。根据配置文件去设置,我看到TUM1.yaml是金字塔层级8,缩放系数是1.2。
step3
根据灰度图提取ORB特征点。提取的代码主要是在ORBextractor.cc中的括号运算符重载函数中。
/*** @brief 用仿函数(重载括号运算符)方法来计算图像特征点* * @param[in] _image 输入原始图的图像* @param[in] _mask 掩膜mask* @param[in & out] _keypoints 存储特征点关键点的向量* @param[in & out] _descriptors 存储特征点描述子的矩阵*/
void ORBextractor::operator()( InputArray _image, InputArray _mask,
vector<KeyPoint>& _keypoints,OutputArray _descriptors)
这个函数的步骤如下:
- 检查图像有效性,如果为空就退出。
- 构建图像金字塔:
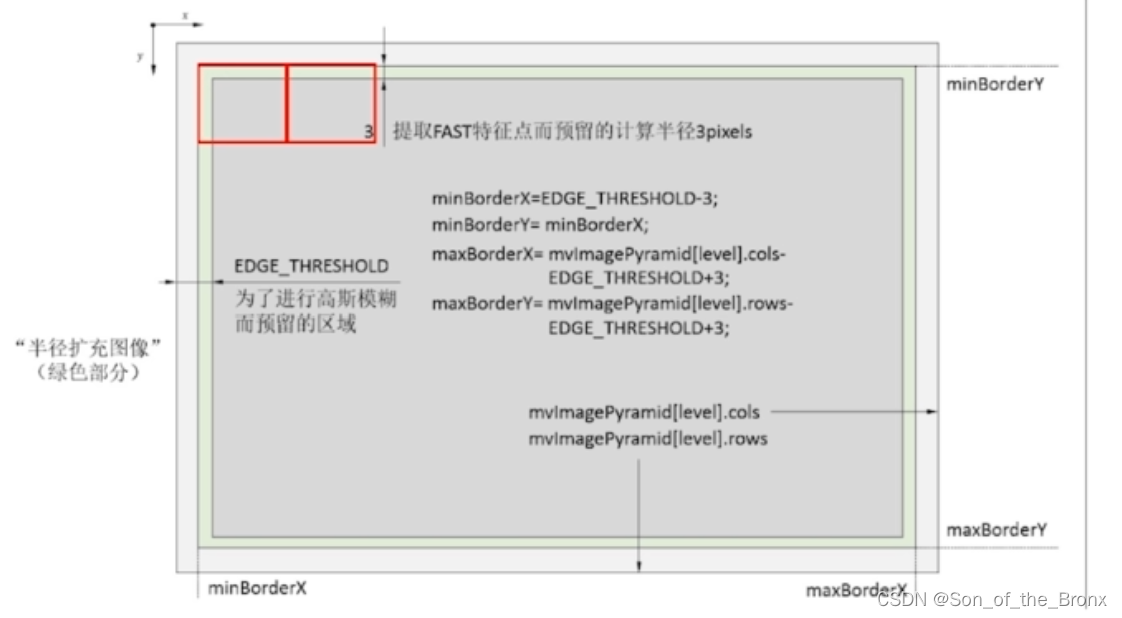
2.1按照缩放系数获得本级金字塔的图像,并且扩展图像的边界。(图中说的比较清晰了,一个是为了提取fast特征点预留的,另一个是为了高斯模糊预留的)

2.2最终得到8个图像vector<Mat>的容器,用于后续提取特征点。 - 计算图像的特征点
3.1 将每个金字塔图层的图像按照网格一个一个来进行FAST点的提取,如下面红色网格。
提取FAST角点的过程可以看下面的图:

-
选取像素点p,灰度为 I p I_p Ip
-
设定一个阈值T
-
以像素点p为圆心,选择半径为3圆上的16个像素点
-
遍历16个像素点,如果有连续N个点的亮度大于 I p + T I_p+T Ip+T或 I p − T I_p-T Ip−T,认为p是特征点
-
对每一个像素重复上面的操作
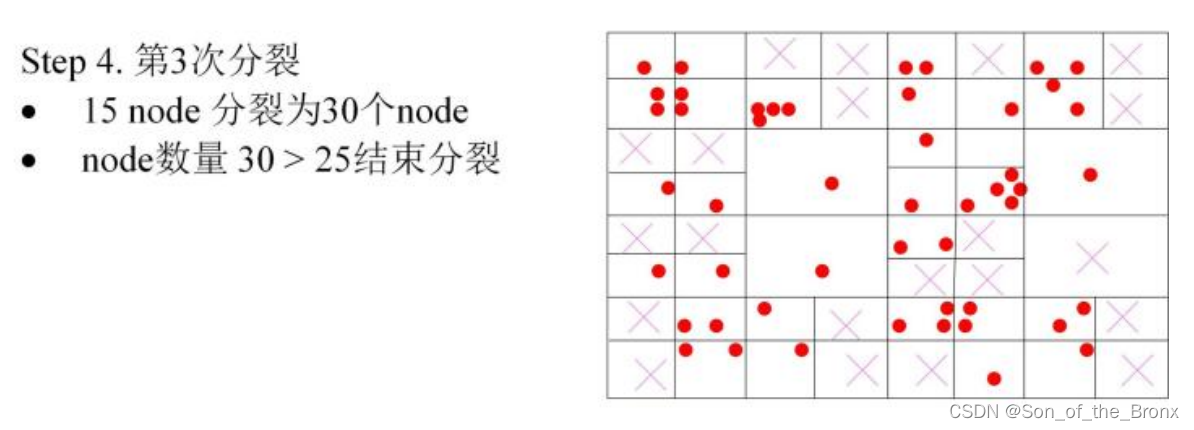
3.2 将每个金字塔图层的特征点数量根据四叉树的方法,平均分布特征点,四叉树的结果如下图所示:(最后每个网格留下质量最好的点)
需要注意的是,每个金字塔因为长宽不同,所以根据金字塔图像长度的不同,将每次普通帧需要提取设定的点数(配置文件中是1000个),按照公式设定每个金字塔图像保留多少个特征点:
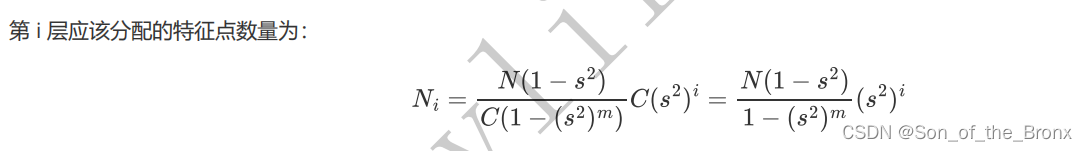
3.3 根据灰度质心法,计算每个金字塔图层中特征点的方向。这个是为了让后面的brief描述子具有旋转不变性的。去特征点周围半径为HALF_PATCH_SIZE的像素来计算局部图像的质心,公式如下:
m 10 = ∑ x = − R R ∑ y = − R R x I ( x , y ) m 01 = ∑ x = − R R ∑ y = − R R y I ( x , y ) \begin{aligned} & m_{10}=\sum_{x=-R}^R \sum_{y=-R}^R x I(x, y) \\ & m_{01}=\sum_{x=-R}^R \sum_{y=-R}^R y I(x, y)\end{aligned} m10=x=−R∑Ry=−R∑RxI(x,y)m01=x=−R∑Ry=−R∑RyI(x,y)
m 00 = ∑ x = − R R ∑ y = − R R I ( x , y ) m_{00}=\sum_{x=-R}^R \sum_{y=-R}^R I(x, y) m00=∑x=−RR∑y=−RRI(x,y)
得到质心的位置:
C = ( c x , c y ) = ( m 10 m 00 , m 01 m 00 ) C=\left(c_x, c_y\right)=\left(\frac{m_{10}}{m_{00}}, \frac{m_{01}}{m_{00}}\right) C=(cx,cy)=(m00m10,m00m01)
最后根据质心位置计算当前特征点的方向:
θ = arctan 2 ( c y , c x ) = arctan 2 ( m 01 , m 10 ) \theta=\arctan 2\left(c_y, c_x\right)=\arctan 2\left(m_{01}, m_{10}\right) θ=arctan2(cy,cx)=arctan2(m01,m10)
在这部分的计算中,为了加快计算质心的位置,程序里是根据提前算好的u_max同时对两行进行计算,具体的代码就不详细展开了。
这里留下一个疑问:这里计算质心的PATCH的大小,每个金字塔图层都用了一样的大小,PATCH的大小是30。这应该需要根据金字塔图层来改变? -
将每一层金字塔图像进行高斯模糊后(高斯模糊有利于减少噪点的影响),将保留下来的每个特征点,都计算它们的brief描述子,这个描述子结合了特征点的方向,所以最终具备旋转不变性。

brief描述子的计算过程: -
在关键点的周围以一定模式选取N个点对(在代码中是256个点对)
-
τ ( p ; x , y ) : = { 1 if p ( x ) < p ( y ) 0 otherwise \tau(\mathbf{p} ; \mathbf{x}, \mathbf{y}):= \begin{cases}1 & \text { if } \mathbf{p}(\mathbf{x})<\mathbf{p}(\mathbf{y}) \\ 0 & \text { otherwise }\end{cases} τ(p;x,y):={10 if p(x)<p(y) otherwise 根据公式计算每一个位的数,一共是256位描述子
注意:这256个点对是预先设定好在程序中的,应该是orbslam2作者通过机器学习得到的结果。最后就是根据这256对索引取值的时候,需要用上前面计算的特征点角度,具体操作如下图所示,256对点本来在图像的坐标系上,需要转到PQ为X轴的坐标系上,再计算brief描述子,这时候的brief描述子就具备了旋转不变性。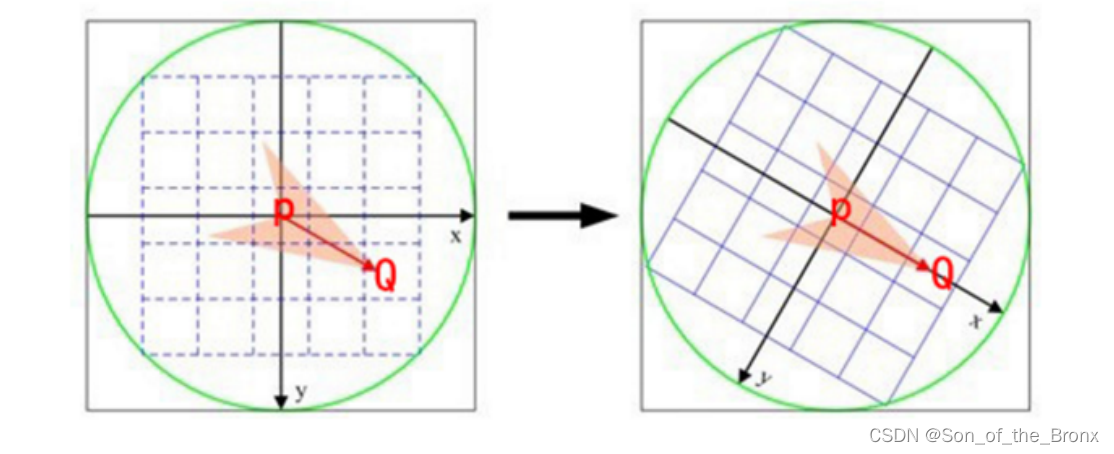
step4
通过opencv,对图像进行畸变矫正。其实就是根据标定好的畸变矫正系数 k 1 k_1 k1、 k 2 k_2 k2、 p 1 p_1 p1、 p 2 p_2 p2来对图像进行去畸变。

最后用校正后的特征点像素坐标覆盖特征点的老像素坐标。
step5
将特征点分配到图像网格中。目的应该就是为了方便后续两个图像帧之间的特征点配对。
总结
至此,就已经讲完了数据预处理的过程,主要的处理代码都是在Frame的构造函数当中,根据一帧图像,构建了一个Frame对象,里面存储着很多关键信息:每个金字塔图层的特征点及其对应旋转不变性的Rotated BRIEF,还对特征点进行去畸变。
这篇关于orbslam2代码解读(1):数据预处理过程的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







