本文主要是介绍【贡献度分析(帕累托图)】,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
文章目录
- 前言
- 一、贡献度分析是什么?
- 二、使用步骤
- 1. 准备数据
- 2. 排序数据
- 3. 绘制帕累托图
- 4. 分析结果
- 5. 实际应用
- 三、示例代码
前言
贡献度分析也称为帕累托分析。它可以帮助我们理解数据集中各个因素对整体影响的程度,从而优先处理最重要的因素,达到事半功倍的效果。
一、贡献度分析是什么?
贡献度分析源自于意大利经济学家维尔弗雷多·帕累托的名字,他在20世纪初提出了“20/80定律”,即80%的结果来自于20%的原因。贡献度分析通过绘制帕累托图,将数据按照重要性排序,揭示出影响最大的关键因素,有助于决策者更好地分配资源和精力。
二、使用步骤
1. 准备数据
首先准备要分析的数据集,可以是销售额、成本、客户数量等各种业务指标。
2. 排序数据
将数据按照重要性进行排序,可以是按照金额大小、数量多少等指标。
3. 绘制帕累托图
利用排序后的数据绘制帕累托图,横轴表示因素,纵轴表示累积贡献度,通常用累积百分比表示。同时,在图上添加累积百分比曲线,以便更直观地观察数据分布。
4. 分析结果
根据帕累托图的结果,可以清晰地看出哪些因素对整体影响最大,从而有针对性地进行决策和优化。
5. 实际应用
贡献度分析在各个领域都有广泛的应用,比如销售管理、生产管理、客户管理等。通过识别关键因素,可以帮助企业更加高效地运营和管理。
三、示例代码
import pandas as pd
import matplotlib.pyplot as plt# 准备数据
data = {'因素': ['A', 'B', 'C', 'D', 'E'],'金额': [100, 80, 60, 40, 20]
}
df = pd.DataFrame(data)# 排序数据
df_sorted = df.sort_values(by='金额', ascending=False)
df_sorted['累积百分比'] = df_sorted['金额'].cumsum() / df_sorted['金额'].sum() * 100
print(df_sorted)# 绘制帕累托图
fig, ax1 = plt.subplots()# 设置中文
plt.rcParams['font.sans-serif'] = ['SimHei']
plt.rcParams['axes.unicode_minus'] = False
color = 'tab:red'
ax1.bar(df_sorted['因素'], df_sorted['金额'], color=color)
ax1.set_xlabel('因素')
ax1.set_ylabel('金额', color=color)
ax1.tick_params(axis='y', labelcolor=color)ax2 = ax1.twinx()
color = 'tab:blue'
ax2.plot(df_sorted['因素'], df_sorted['累积百分比'], color=color, marker='o')
ax2.set_ylabel('累积百分比', color=color)
ax2.tick_params(axis='y', labelcolor=color)plt.title('贡献度分析(帕累托图)')
plt.show()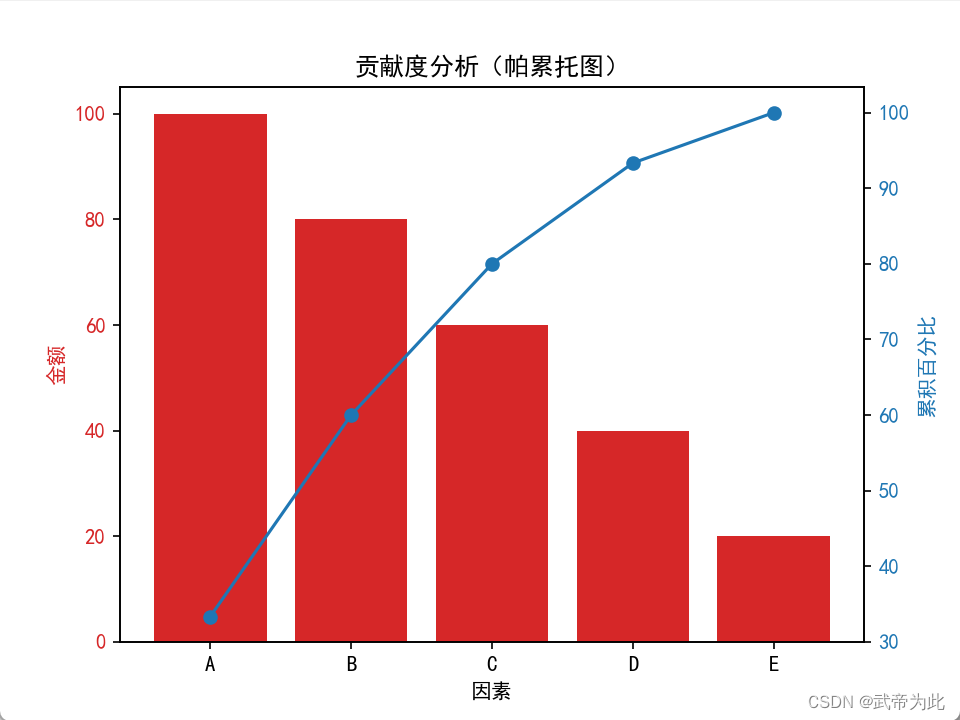
这篇关于【贡献度分析(帕累托图)】的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






