本文主要是介绍数据资产入表-数据治理-指标建设标准,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
前情提要:数据价值管理是指通过一系列管理策略和技术手段,帮助企业把庞大的、无序的、低价值的数据资源转变为高价值密度的数据资产的过程,即数据治理和价值变现。上一讲介绍了标签标准设计的基本逻辑和思路。数据资产入表-数据治理-标签设计标准
本章重点讲解指标建设标准设计
指标数据是为了基于场景出发,为了满足内部分析决策或者外部使用的一个高度凝练的数据结果集,指标数据标准是为满足管理指标生产过程、对基础类数据加工而产生的指标数据标准化规范。
数据分析师或者数仓治理人员常常会听到”统计结果不对”、”这个指标没有”、”这个指标怎么用?”的灵魂拷问。在做了问题定位之后,除了真的指标缺失之外,还有以下三张情形:
①指标名称不规范:当指标生产了一段时间,有了初步沉淀后,发现存量指标的名称千奇百怪,各有各的风格,这个是在指标设计之初对于指标的命名没有做出对应的规范(做出规范的同时需要有工具支撑);
②指标重复建设:在盘点指标的过程中,发现指标因名称不规范、单位不规范等原因,同一个指标出现多次建设的情况;
③指标口径不清晰:在指标使用的过程中,发现指标命名长得相似,但是不知道具体含义,也不清楚哪个指标适用于哪个场景;
因此需要构建一套指标数据标准,帮助我们在指标体系搭建的过程中和用户使用的过程中更为清晰明了。
指标数据标准建设
指标数据标准是为满足内部分析管理需要和外部监管要求,对基础类数据加工而产生的指标数据标准化规范。指标数据标准通过基础属性、业务属性、技术属性和管理属性来描述指标数据规范化要求。--引用《JR/T0137-2017银行经营管理指标数据元》
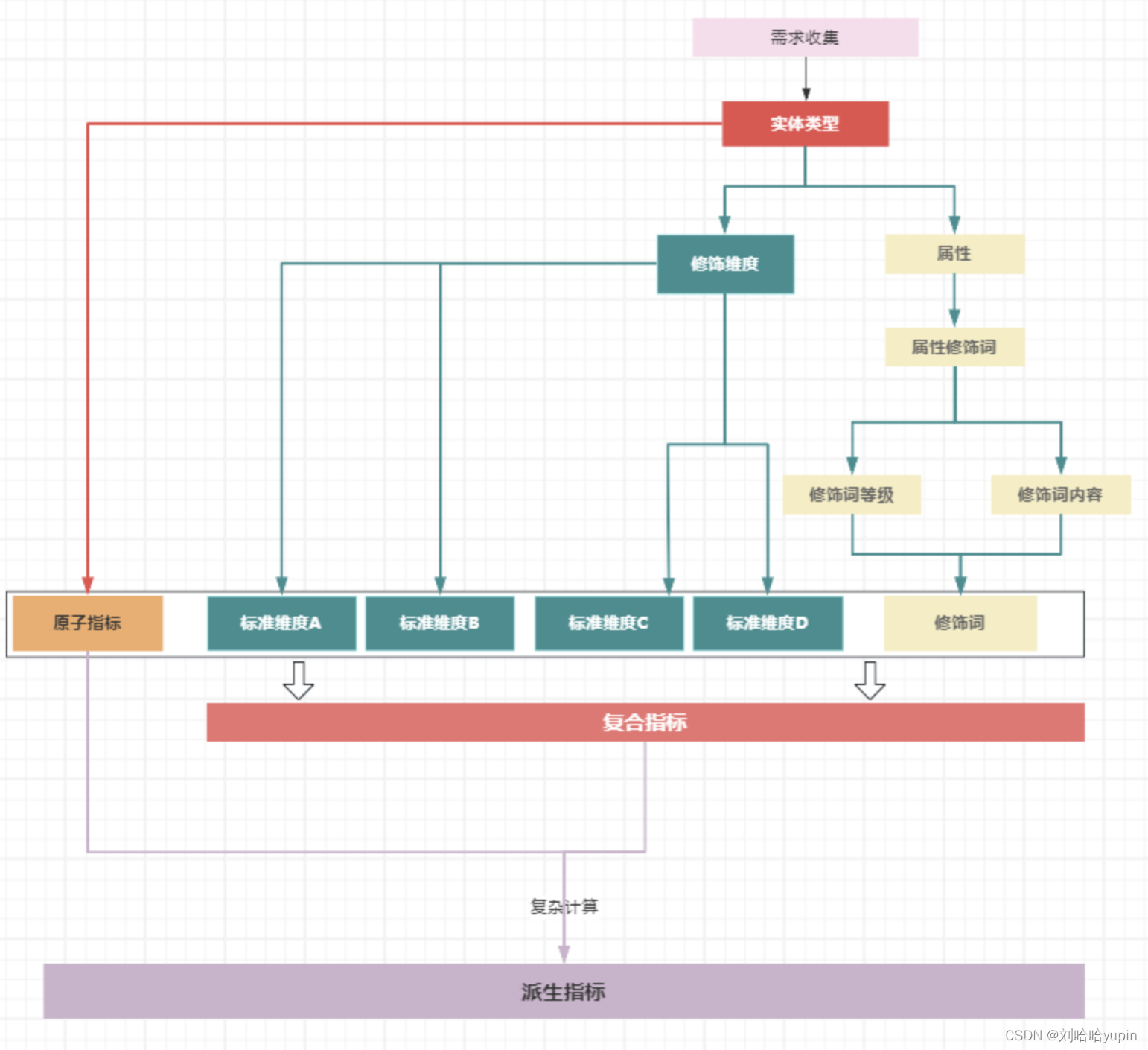
指标类型
指标的梳理还是离不开实体的确认,实体在指标体系中是指标统计的对象,在指标体系梳理的过程中,在业务的角度上把指标分为原子指标、复合指标、派生指标;
原子指标:是针对实体对象的基础统计值;例如(企业数量)
复合指标:是在原子指标的基础上,增加属性维度的统计;例如(杭州市:企业数量;杭州市:新成立企业数量)
派生指标:是在原子指标、复合指标的基础上,进行复合计算的派生指标;例如(杭州市:企业数量累计同比)
指标体系搭建
指标体系的搭建一般是业务运行一段时间后,对于明细数据有一定沉淀,且业务人员在实际业务管理过程中存在一定的场景需求之后,才有具体的指标体系搭建场景。指标体系搭建的步骤如下:
step1:场景/业务需求收集和调研
在业务收集的过程中,需要用户明确的内容包含指标统计的场景描述、统计的时间范围、统计的类型(要当前值、同比值、累计值、环比值)、统计的区域(若业务上没有,可忽略),平常使用的频率,如果是金额维度,需要描述统计的单元;
step2:在收集和调研业务需求后,开始梳理指标体系,需要基于业务需求拆解核心信息
①确定原子指标:明确出来业务需求中需要统计的实体;
②确定复合属性:明确统计口径中包含的修饰维度,其中需要区分出常用修饰维度和使用率较低的属性;
③确定统计口径:基于需求确定统计时间、统计类型的口径;
④输出指标清单:基于上述的信息收集和梳理,生成版本号、构建指标名称模板、统计单位、计算类型、指标释义、指标计算规则、更新频率等;
- 版本号:是指本次指标逻辑操作的次数记录,一般依托于工具生成;
- 指标名称模板:在指标生产的过程中,一般不会一个个罗列指标进行生产,会采用group by 的逻辑分类统计,因此在我们输出需求清单的时候,可能不是实际的指标名称,而是指标名称的模板,需要在命名的时候给分类修饰词留下占位符;
- 指标类型:描述指标的类型是属于原子指标、复合指标,派生指标
- 业务标签:描述业务标签类型,业务标签类型背后可以映射一张标签结果表;
- 计算类型:指的是这个指标是基于count、sum、avg等类型计算而成;
- 指标释义:需要描述指标的统计维度,包含的必要维度有统计实体、参与统计的业务标签;
- 实体所在明细表:顾名思义是被统计实体的明细表表名;
- 计算规则:是指该指标的计算规则;
- 单位:描述指标的单位信息;
- 更新频率:指定指标计算的频率;结合明细表的更新频率,指标的计算频率要低于明细表的更新频率;
- 负责人:明确该指标的业务负责人名称;

step3:推动开发和验收:基于输出的需求清单推动开发和验收上线;
指标梳理流程
这篇关于数据资产入表-数据治理-指标建设标准的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!



